常见性能问题
本节描述可能出现的各类问题场景。
若某规则引擎队列使用 可按以下步骤排查原因:
提示: 可为不稳定或测试用例创建独立队列,与其它规则引擎分开。这样失败只会影响该独立队列,不会影响整个系统。 可通过 Device Profile 的 queue-name 功能,为设备自动配置该逻辑。 提示: 对连接外部服务(REST API 调用、Kafka、MQTT 等)的规则节点,务必处理 Failure 事件。 这样可在外部系统出现故障时,保证规则引擎处理不会中断。 可将失败消息存入 DB、发送通知,或仅记录消息。 |
有时规则引擎内消息处理延迟会逐渐增大。可按以下步骤排查原因:
|
故障排查工具与建议
规则引擎统计仪表板
可查看rule chain处理过程中是否存在Failures、Timeouts或Exceptions。更多详情见此处。
Kafka队列消费组消息延迟
说明: 仅在选择Kafka作为队列时适用。
通过该log可判断消息处理是否存在问题(Queue用于系统内所有消息传递,可分析rule-engine queues及 transport、core 等)。 使用consumer-group lag排查rule-engine处理的更多说明见此处。
CPU/Memory使用
有时问题源于某服务资源不足。可登录server/container/pod并执行 top 命令查看CPU和Memory使用情况。
建议配置Prometheus和Grafana便于监控。
若某服务偶尔占用100% CPU,可横向扩展(在cluster中新增节点)或纵向扩展(增加CPU总量)。
Message Pack处理日志
可启用对最慢且调用最频繁的rule node的日志记录。 需在日志配置中添加以下 logger:
1
<logger name="org.thingsboard.server.service.queue.TbMsgPackProcessingContext" level="DEBUG" />
配置后可在logs中看到如下消息:
1
2
3
4
5
6
7
8
9
2021-03-24 17:01:21,023 [tb-rule-engine-consumer-24-thread-3] DEBUG o.t.s.s.q.TbMsgPackProcessingContext - Top Rule Nodes by max execution time:
2021-03-24 17:01:21,024 [tb-rule-engine-consumer-24-thread-3] DEBUG o.t.s.s.q.TbMsgPackProcessingContext - [Main][3f740670-8cc0-11eb-bcd9-d343878c0c7f] max execution time: 1102. [RuleChain: Thermostat|RuleNode: Device Profile Node(3f740670-8cc0-11eb-bcd9-d343878c0c7f)]
2021-03-24 17:01:21,024 [tb-rule-engine-consumer-24-thread-3] DEBUG o.t.s.s.q.TbMsgPackProcessingContext - [Main][3f6debf0-8cc0-11eb-bcd9-d343878c0c7f] max execution time: 1. [RuleChain: Thermostat|RuleNode: Message Type Switch(3f6debf0-8cc0-11eb-bcd9-d343878c0c7f)]
2021-03-24 17:01:21,024 [tb-rule-engine-consumer-24-thread-3] INFO o.t.s.s.q.TbMsgPackProcessingContext - Top Rule Nodes by avg execution time:
2021-03-24 17:01:21,024 [tb-rule-engine-consumer-24-thread-3] INFO o.t.s.s.q.TbMsgPackProcessingContext - [Main][3f740670-8cc0-11eb-bcd9-d343878c0c7f] avg execution time: 604.0. [RuleChain: Thermostat|RuleNode: Device Profile Node(3f740670-8cc0-11eb-bcd9-d343878c0c7f)]
2021-03-24 17:01:21,025 [tb-rule-engine-consumer-24-thread-3] INFO o.t.s.s.q.TbMsgPackProcessingContext - [Main][3f6debf0-8cc0-11eb-bcd9-d343878c0c7f] avg execution time: 1.0. [RuleChain: Thermostat|RuleNode: Message Type Switch(3f6debf0-8cc0-11eb-bcd9-d343878c0c7f)]
2021-03-24 17:01:21,025 [tb-rule-engine-consumer-24-thread-3] INFO o.t.s.s.q.TbMsgPackProcessingContext - Top Rule Nodes by execution count:
2021-03-24 17:01:21,025 [tb-rule-engine-consumer-24-thread-3] INFO o.t.s.s.q.TbMsgPackProcessingContext - [Main][3f740670-8cc0-11eb-bcd9-d343878c0c7f] execution count: 2. [RuleChain: Thermostat|RuleNode: Device Profile Node(3f740670-8cc0-11eb-bcd9-d343878c0c7f)]
2021-03-24 17:01:21,028 [tb-rule-engine-consumer-24-thread-3] INFO o.t.s.s.q.TbMsgPackProcessingContext - [Main][3f6debf0-8cc0-11eb-bcd9-d343878c0c7f] execution count: 1. [RuleChain: Thermostat|RuleNode: Message Type Switch(3f6debf0-8cc0-11eb-bcd9-d343878c0c7f)]
清理Redis/Valkey缓存
说明: 仅在选择Redis或Valkey作为cache时适用。
缓存内数据可能损坏。无论原因如何,清空缓存都是安全的 —— ThingsBoard会在运行时重新填充。清空缓存需登录部署的server/container/pod,打开应用命令行工具(Redis用 redis-cli,Valkey用 valkey-cli),执行 FLUSHALL。Sentinel模式下,需访问master container执行清空命令。
若难以定位问题原因,可尝试清空缓存以排除缓存导致的问题。
日志
读取logs
无论部署方式如何,ThingsBoard logs均存储在ThingsBoard Server/Node所在server/container的以下目录:
1
/var/log/thingsboard
不同部署方式查看logs的方法不同:
实时查看最新日志: 可使用 grep 命令仅显示包含指定字符串的输出。 例如,可用以下命令检查后端是否存在错误: |
实时查看最新日志: 若仍使用带连字符的 docker-compose,请执行: docker-compose logs -f tb-core1 tb-core2 tb-rule-engine1 tb-rule-engine2 若怀疑问题仅与 rule-engine 相关,可只查看 rule-engine 日志: 若仍使用带连字符的 docker-compose,请执行: docker-compose logs -f tb-rule-engine1 tb-rule-engine2 可使用 grep 命令仅显示包含指定字符串的输出。 例如,可用以下命令检查后端是否存在错误: 若仍使用带连字符的 docker-compose,请执行: docker-compose logs tb-core1 tb-core2 tb-rule-engine1 tb-rule-engine2 | grep ERROR 提示: 可将日志重定向到文件后用任意文本编辑器分析: 若仍使用带连字符的 docker-compose,请执行: docker-compose logs -f tb-rule-engine1 tb-rule-engine2 > rule-engine.log 注意: 可随时进入 ThingsBoard 容器内查看日志: |
查看集群所有 pods: 查看指定 pod 的最新日志: 查看 ThingsBoard 节点日志: 可使用 grep 命令仅显示包含指定字符串的输出。 例如,可用以下命令检查后端是否存在错误: 若有多节点,可将各节点日志重定向到本地文件再分析: 注意: 可随时进入 ThingsBoard 容器内查看日志: |
启用特定logs
ThingsBoard可根据故障排查需求对系统各部分启用或禁用日志。
通过修改 logback.xml 文件实现。该文件与logs同处ThingsBoard Server/Node所在server/container的以下目录:
1
/usr/share/thingsboard/conf
以下是 logback.xml 配置示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
<!DOCTYPE configuration>
<configuration scan="true" scanPeriod="10 seconds">
<appender name="fileLogAppender"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/thingsboard/thingsboard.log</file>
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>/var/log/thingsboard/thingsboard.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>%d{ISO8601} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<logger name="org.thingsboard.server" level="INFO" />
<logger name="org.thingsboard.js.api" level="TRACE" />
<logger name="com.microsoft.azure.servicebus.primitives.CoreMessageReceiver" level="OFF" />
<root level="INFO">
<appender-ref ref="fileLogAppender"/>
</root>
</configuration>
配置文件中与故障排查最相关的是 loggers。
可为特定类或类组启用/禁用日志。
上例中默认日志级别为 INFO(仅包含一般信息、警告和错误),对包 org.thingsboard.js.api 启用了最详细级别。
也可完全关闭某部分的日志,上例中通过 OFF 级别对 com.microsoft.azure.servicebus.primitives.CoreMessageReceiver 类进行了禁用。
为系统某部分启用/禁用日志需添加相应 </logger> 配置并等待最多10秒。
不同部署方式更新logs的方法不同:
独立部署时,需修改 |
Docker Compose 部署将 |
Kubernetes 部署使用 ConfigMap 为 tb-nodes 提供 logback 配置。 要更新 logback.xml,请执行以下操作: 约 10 秒后,日志配置更改将生效。 |
指标
在配置文件中将环境变量 METRICS_ENABLED 设为 true、METRICS_ENDPOINTS_EXPOSE 设为 prometheus 可启用Prometheus metrics。
若以microservices方式运行ThingsBoard且MQTT与COAP transport为独立服务,还须将 WEB_APPLICATION_ENABLE 设为 true、
WEB_APPLICATION_TYPE 设为 servlet、HTTP_BIND_PORT 设为 8081,以启用带Prometheus metrics的web-server。
Metrics暴露在 https://<yourhostname>/actuator/prometheus,可由Prometheus抓取(无需认证)。
Prometheus指标
Spring Actuator可通过Prometheus暴露部分内部状态指标。
以下是ThingsBoard推送到Prometheus的metrics列表。
tb-node 指标
- attributes_queue_${index_of_queue}: 将属性写入数据库的统计数据。为了最大性能,有多个队列用于保存属性。
- ruleEngine_${name_of_queue}: 规则引擎中的消息处理统计。每个队列都有统计数据。一些统计描述:
- tmpFailed: 失败后将重新处理的消息数量
- tmpTimeout: 超时后将重新处理的消息数量
- timeoutMsgs: 超时且随后被丢弃的消息数量
- failedIterations: 消息处理包的迭代,其中至少有一条消息未成功处理
- ruleEngine_${name_of_queue}_seconds: 不同队列的消息处理耗时统计。
- core: 内部系统消息处理统计。一些统计描述:
- toDevRpc: 来自传输层服务RPC响应的处理数量
- sessionEvents: 来自传输层服务的会话事件计数
- subInfo: 来自传输层服务的订阅信息计数
- subToAttr: 来自传输层服务的属性更新订阅计数
- subToRpc: 来自传输层服务的RPC订阅计数
- getAttr: 来自传输层服务的获取属性请求计数
- claimDevice: 来自传输层服务的设备订阅请求计数
- deviceState: 设备状态变化处理计数
- subMsgs: 处理的订阅计数
- coreNfs: 处理特定系统消息的计数
- jsInvoke: 向JS执行器发送的合计、成功和失败请求的统计数据
- attributes_cache: 属性请求中缓存未命中率的统计计数
传输层指标
- transport: 传输层接收来自ThingsBoard节点的请求统计数据
- ruleEngine_producer: 从传输层推送消息到规则引擎的统计数据。
- core_producer: 从传输层推送消息到ThingsBoard节点设备执行器的统计数据。
- transport_producer: 来自传输层到ThingsBoard的请求统计计数。
某些指标取决于持久化时间序列数据所使用的数据库类型。
PostgreSQL特有指标
- ts_latest_queue_${index_of_queue}: 将最新遥测值写入数据库的统计数据。为了实现最大性能,有多个队列(线程)。
- ts_queue_${index_of_queue}: 将遥测值写入数据库的统计数据。为了实现最大性能,有多个队列(线程)。
Cassandra特有指标
- rateExecutor_currBuffer: 当前正在Cassandra中持久化的消息数量。
- rateExecutor_tenant: 根据租户ID被速率限制的请求数量
- rateExecutor: 统计说明:
- totalAdded: 提交保存的消息数量
- totalRejected: 在提交保存时被拒绝的消息数量
- totalLaunched: 发送到Cassandra的消息数量
- totalReleased: 成功保存的消息数量
- totalFailed: 未能保存的消息数量
- totalExpired: 过期且未发送到Cassandra的消息数量
- totalRateLimited: 由于租户速率限制而未处理的消息数量
Grafana仪表板
可从此处导入预配置的Grafana dashboards。
注意: 根据集群配置,可能需对dashboards进行调整。
部署ThingsBoard docker-compose集群配置后也可查看Grafana dashboards(更多信息请参考本指南)。
确保将 MONITORING_ENABLED 环境变量设为 true。部署完成后,可访问http://localhost:9090 的Prometheus和http://localhost:3000 的Grafana(默认用户名为 admin,密码为 foobar)。
以下是默认预配置Grafana dashboards的截图:
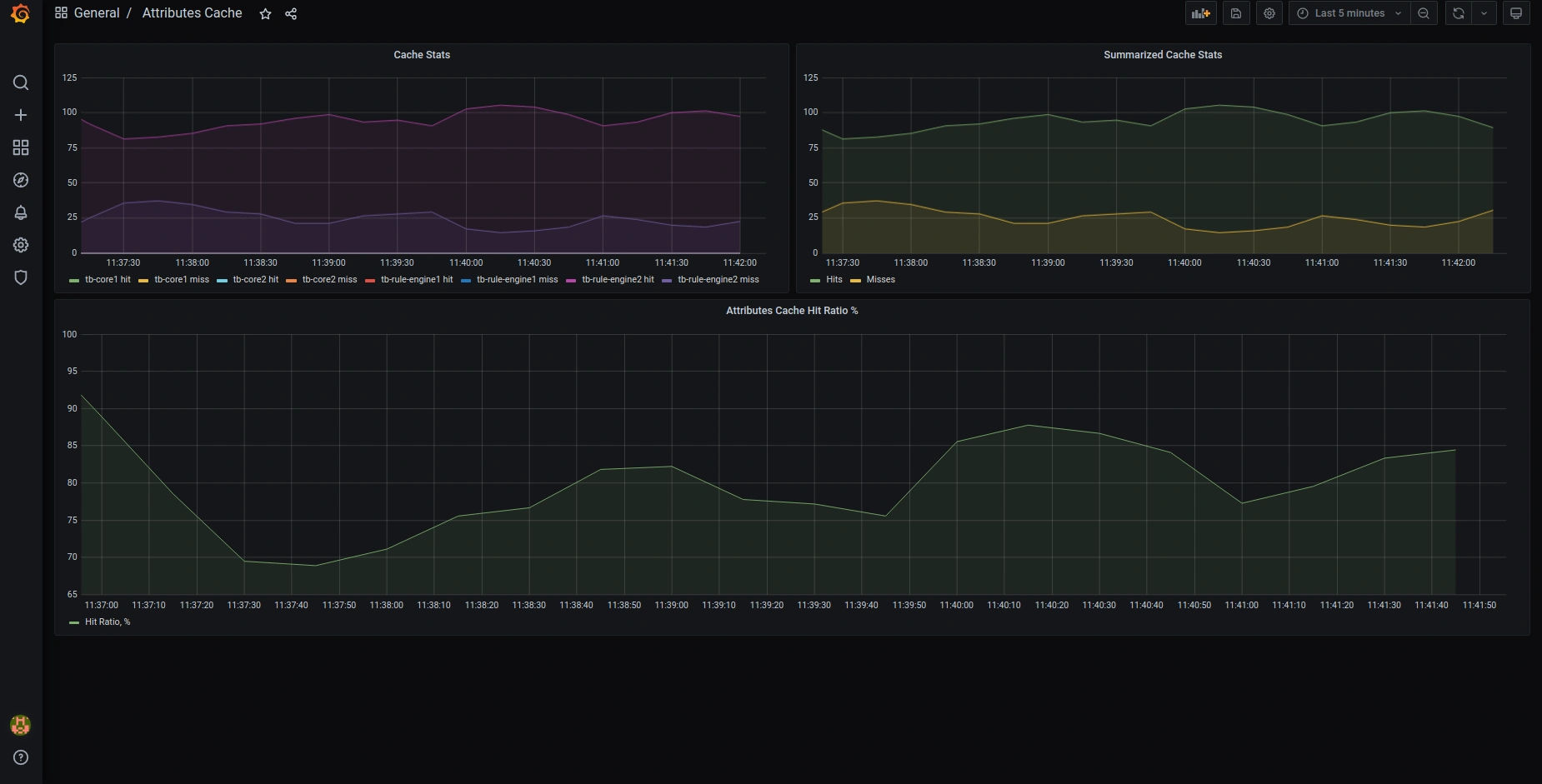
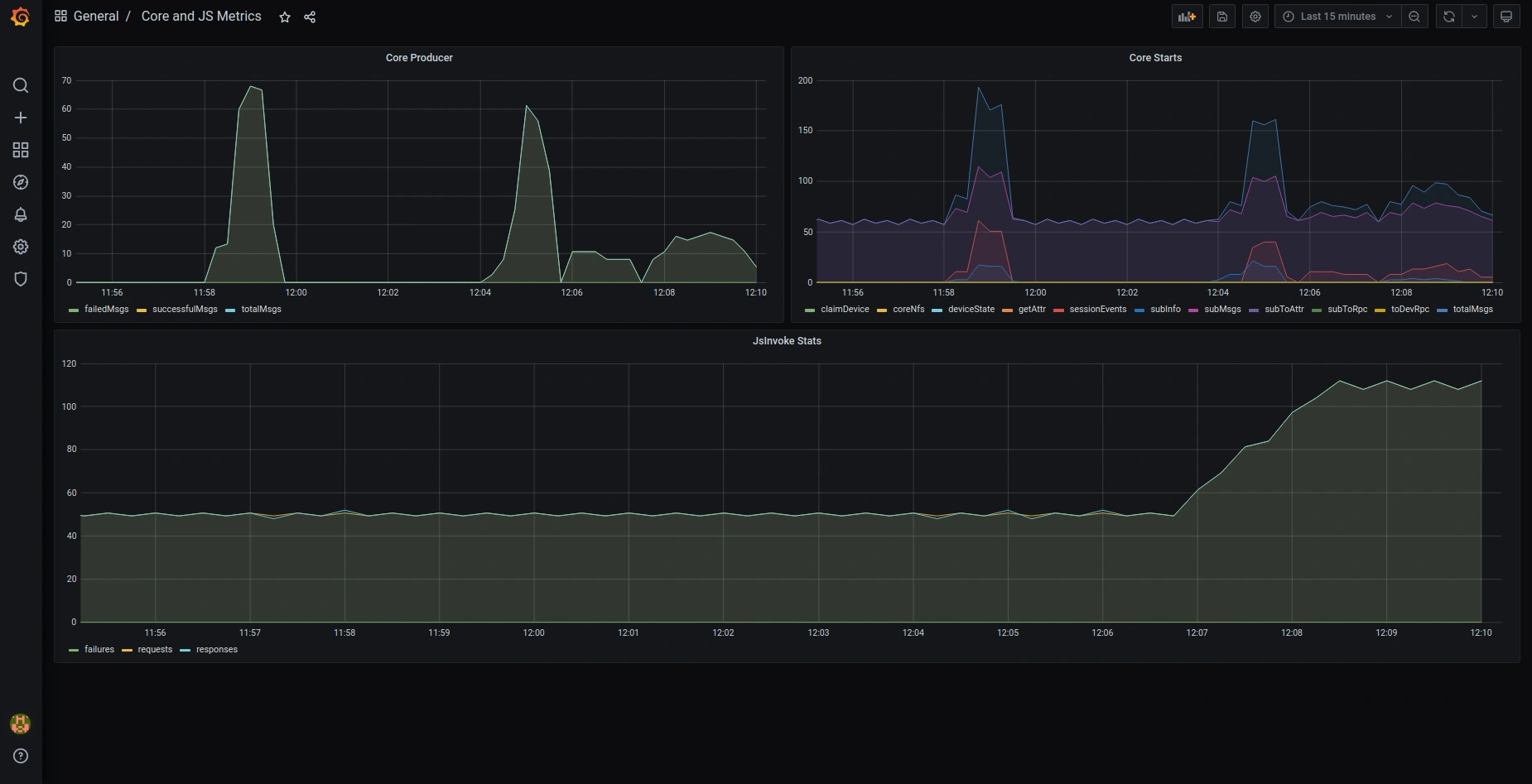
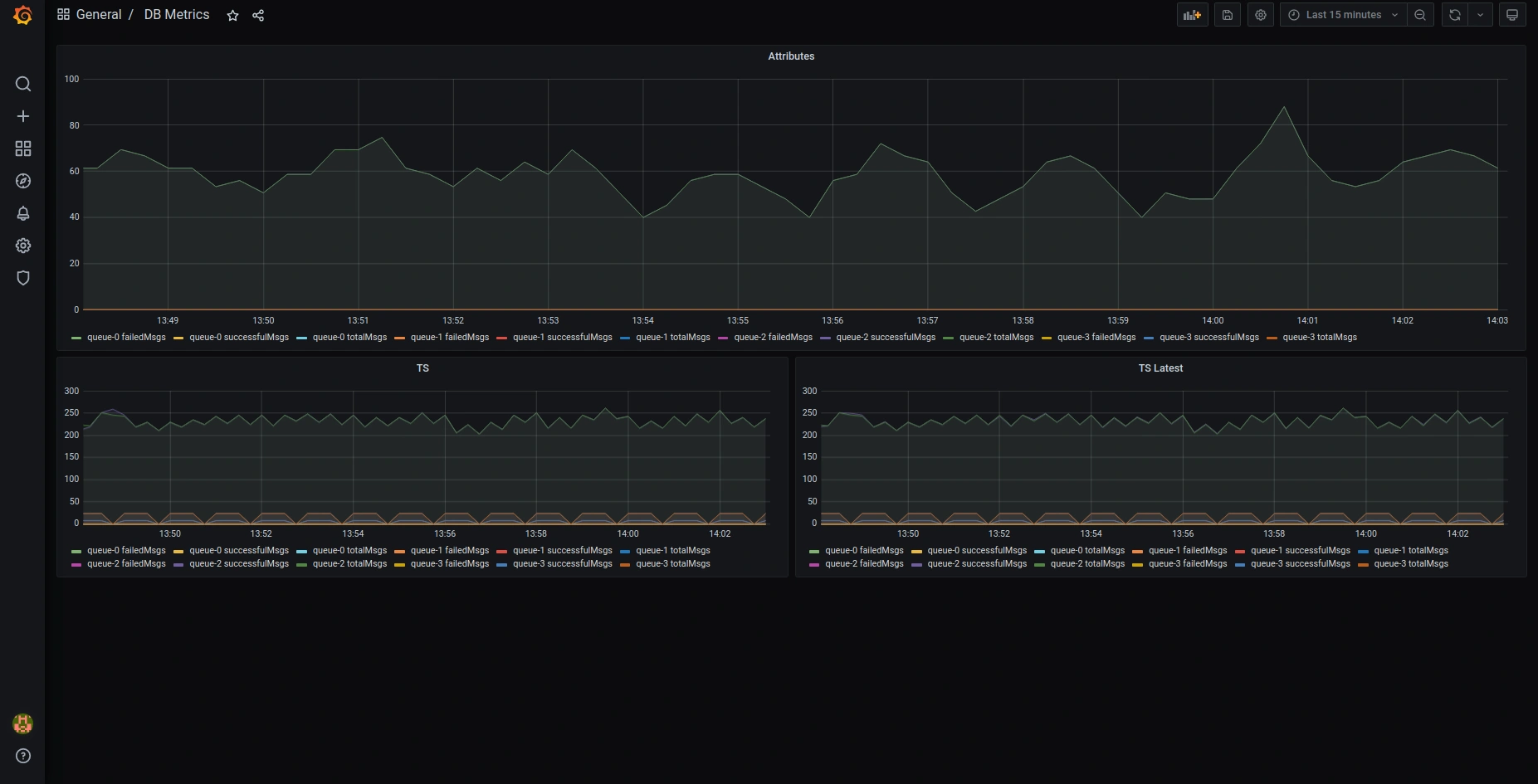
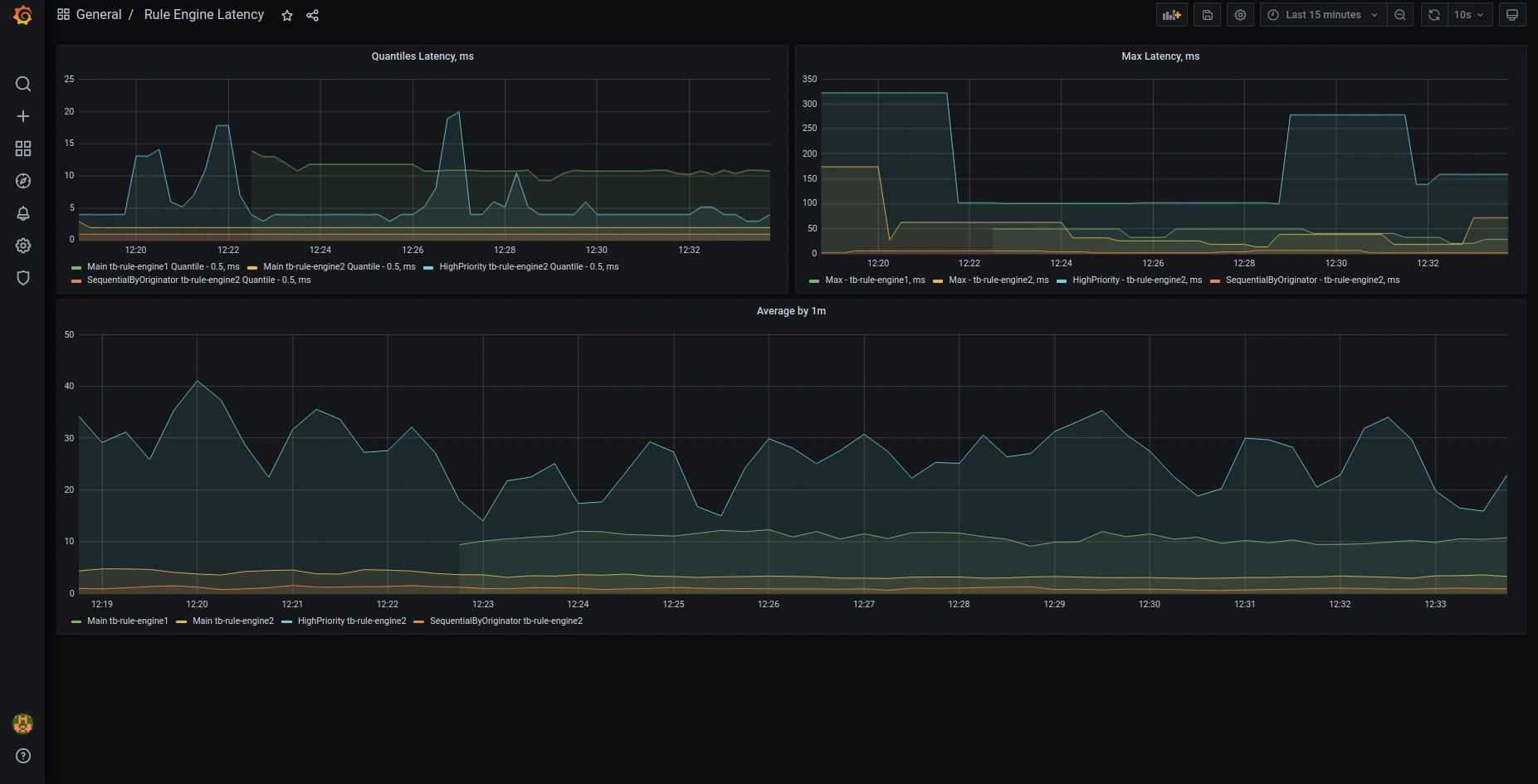
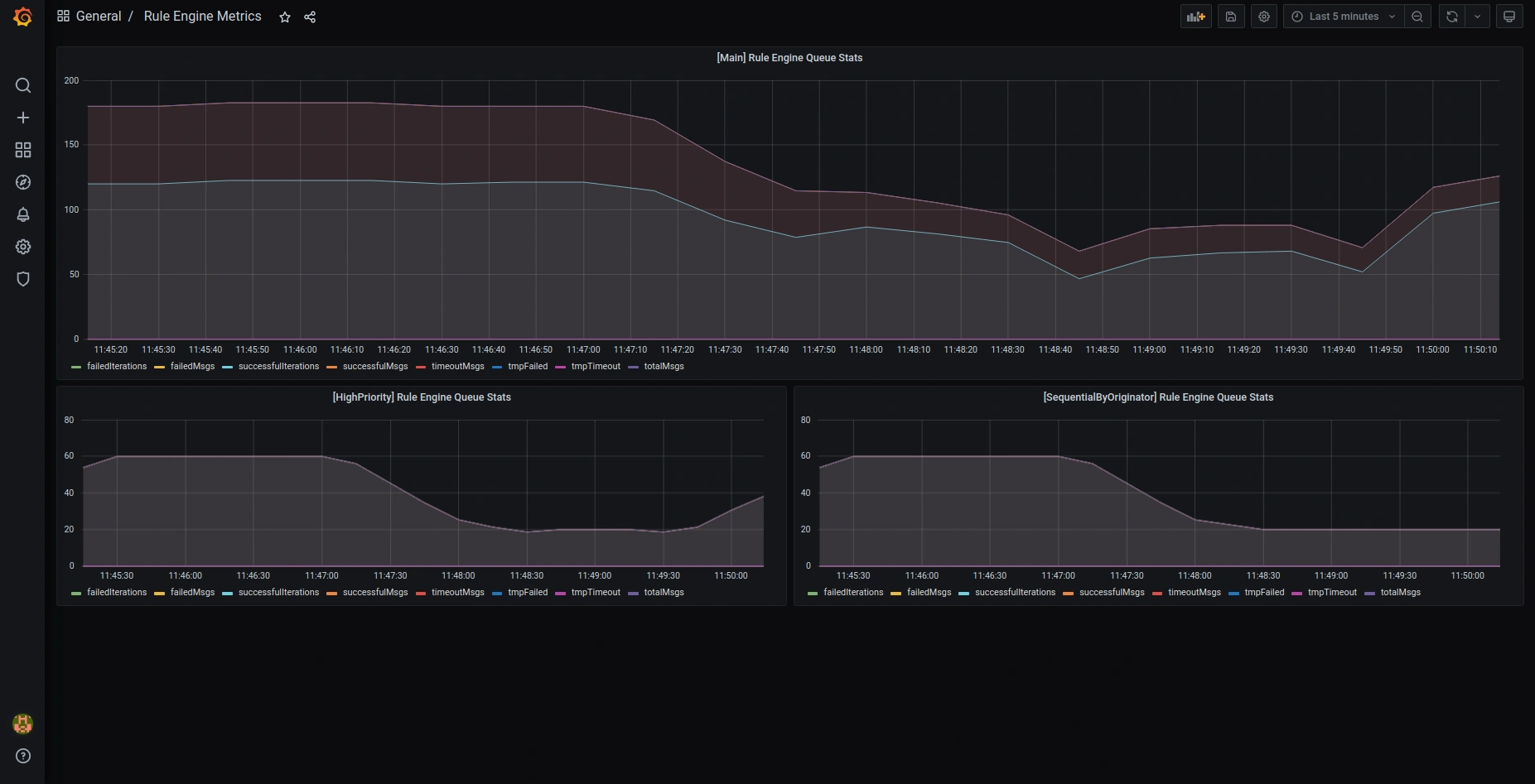
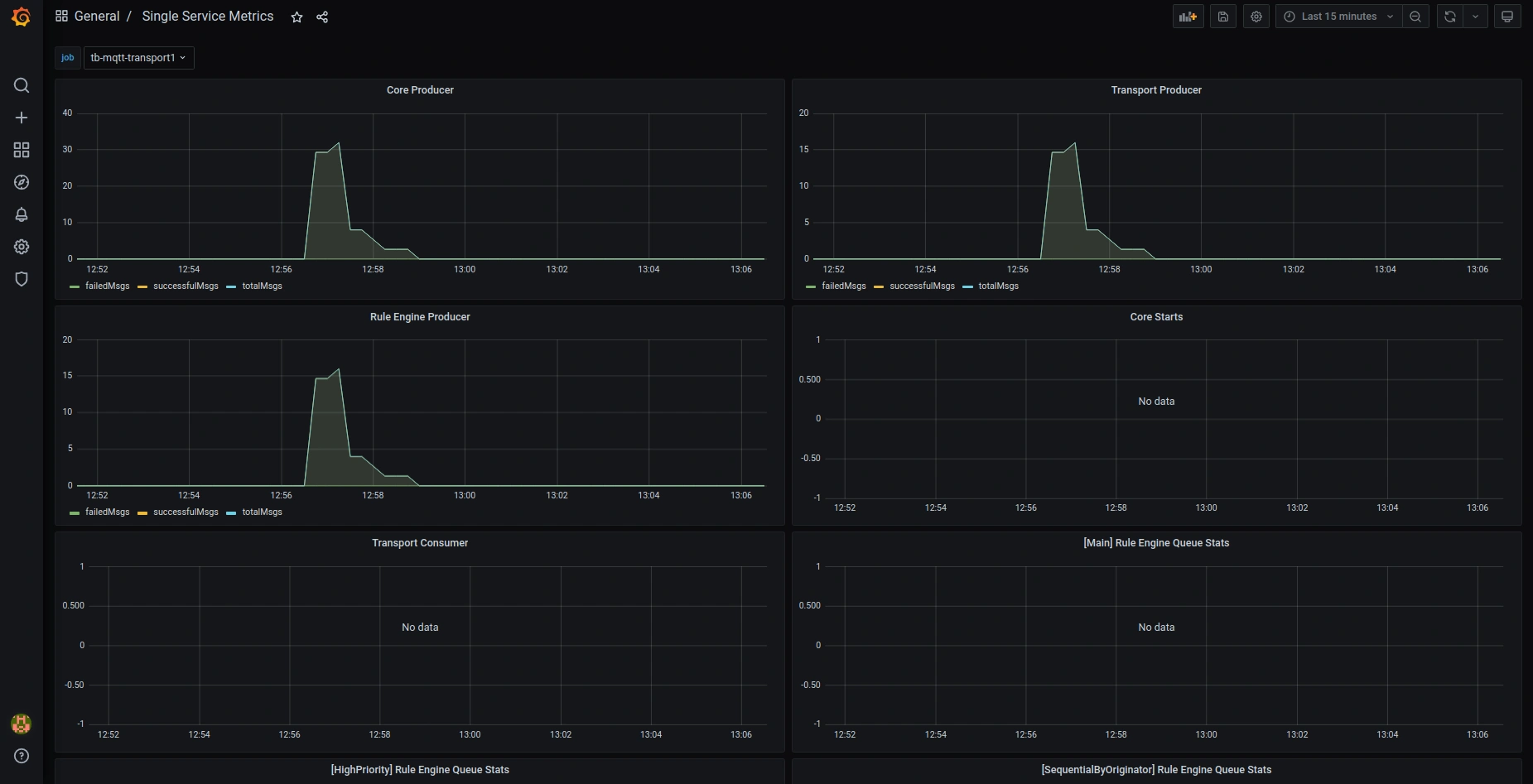
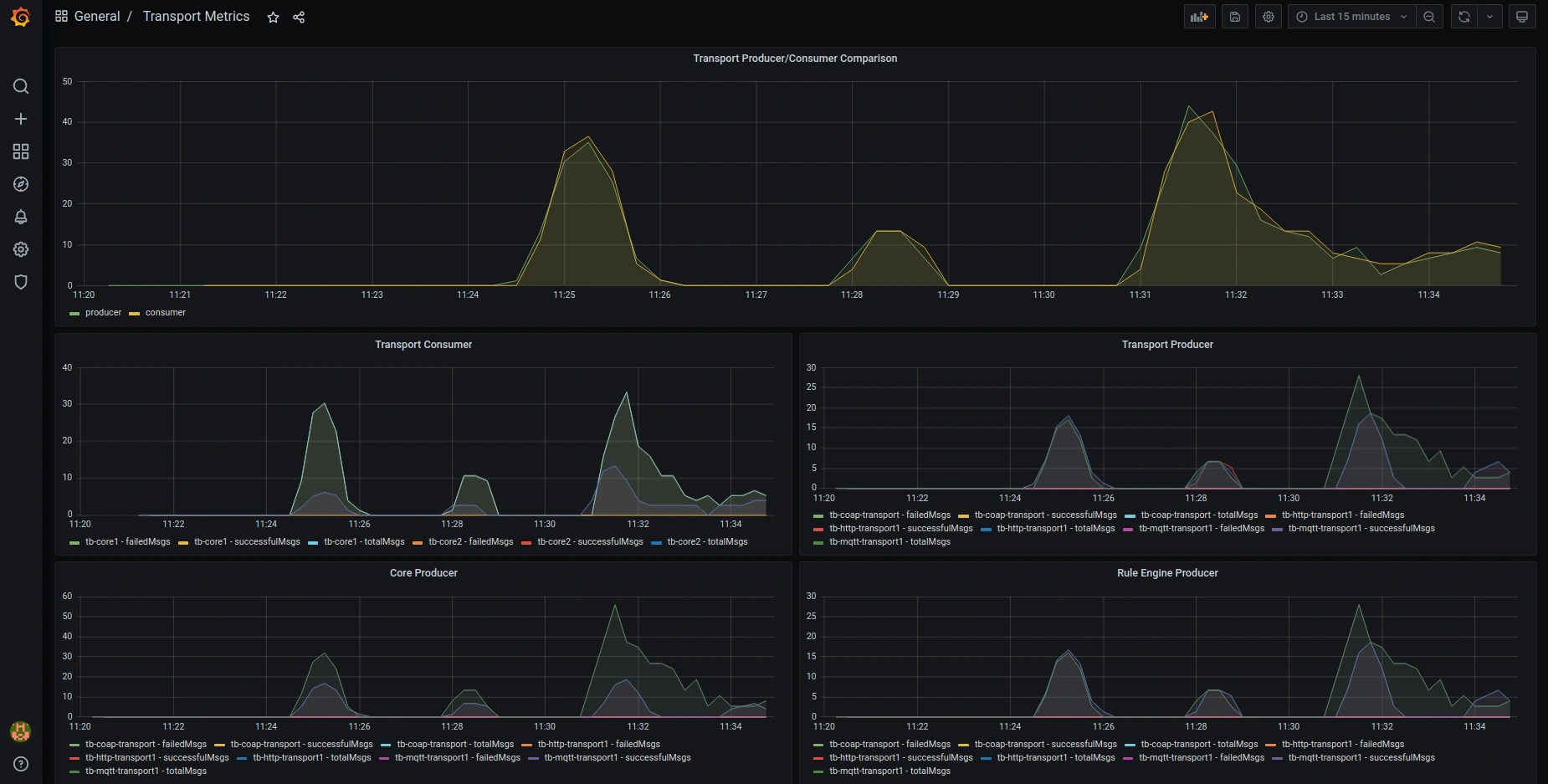
OAuth2
配置OAuth后,有时无法看到使用OAuth提供商登录的按钮。这是因为\u201c域名\u201d和\u201c重定向URI模板\u201d包含错误的值,它们需要与访问您的ThingsBoard网页使用的值相同。
示例:
| 基础URL | 域名 | 重定向URI模板 |
|---|---|---|
| http://mycompany.com:8080 | mycompany.com:8080 | http://mycompany.com:8080/login/oauth2/code |
| https://mycompany.com | mycompany.com | https://mycompany.com/login/oauth2/code |
\u201c主页\u201d部分的基础URL不应包含\u201c/\u201d或其他字符。
作为System Administrator登录ThingsBoard。棠查一般 设置 -> 基础URL不应包含”/”或会关指向末尾 (e.g. “https:// mycompany.com ”instead of “https://mycompany.com/”).
OAuth2配置请点击此处。
获取帮助
若以上指南均未解答您的问题,欢迎联系ThingsBoard团队。