| 4.2及以上版本 |
AI模型是能够处理数据、生成预测、检测异常或生成类人响应的机器学习或大语言模型。 在ThingsBoard中,AI模型用于通过高级分析和自动化扩展IoT数据处理能力。
通过集成外部AI提供方(如OpenAI、Google Gemini、Azure OpenAI、Amazon Bedrock等),您可以:
- 预测未来值(如能耗或设备温度)。
- 检测实时遥测流中的异常。(参见工业设备故障检测示例)。
- 分类设备状态(例如”正常”、”警告”、”故障”)。
- 生成面向操作员和最终用户的回复或自然语言洞察。
ThingsBoard允许您配置并连接不同的AI提供方、管理模型设置,并在Rule Engine中用于自动化与决策。
向ThingsBoard添加AI模型
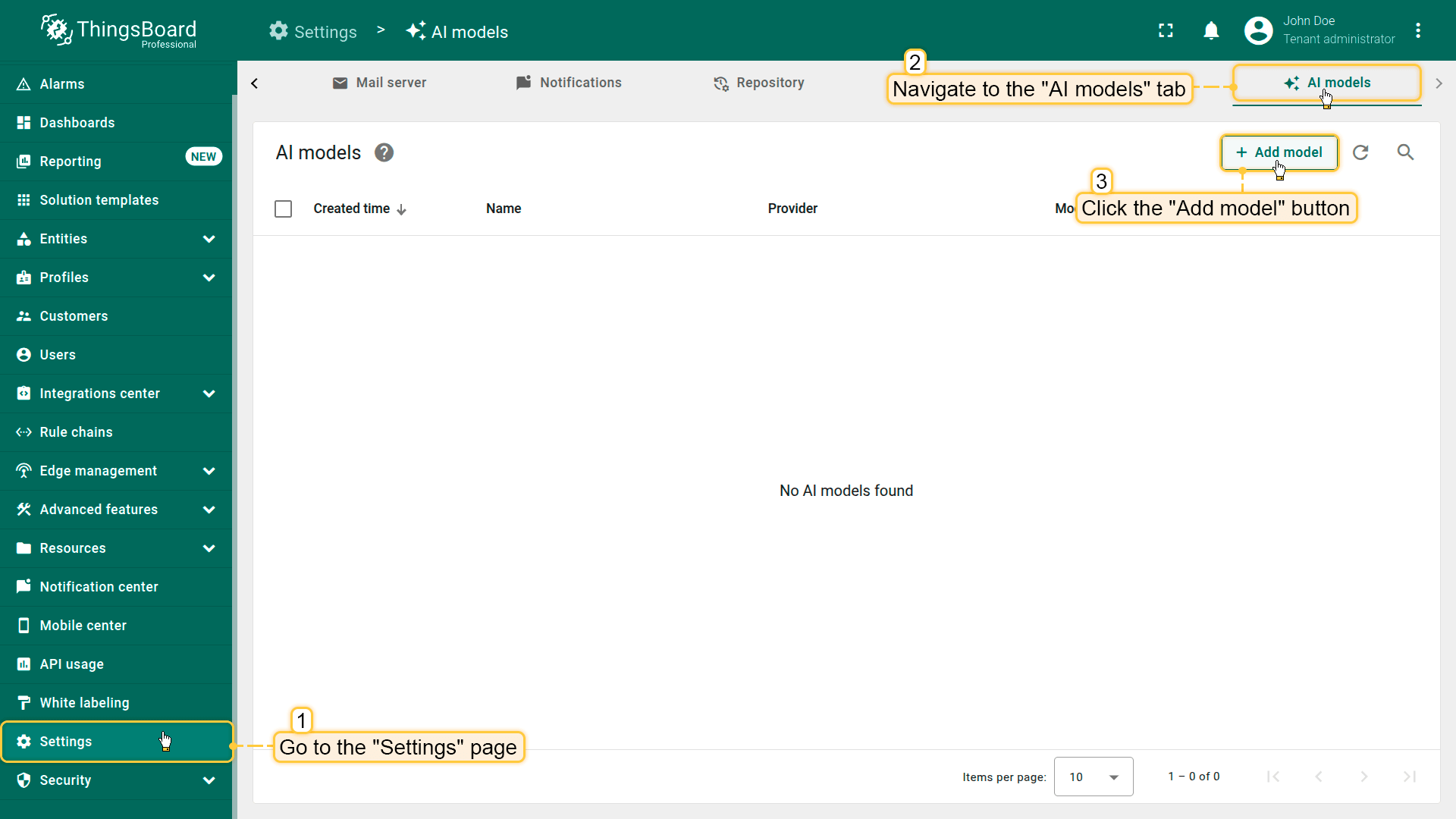
在ThingsBoard中添加AI模型,请按以下步骤操作:
- 进入”Settings“页面的”AI models“标签页。
- 点击”Add model“按钮(位于右上角)。
- 将打开AI模型配置表单:
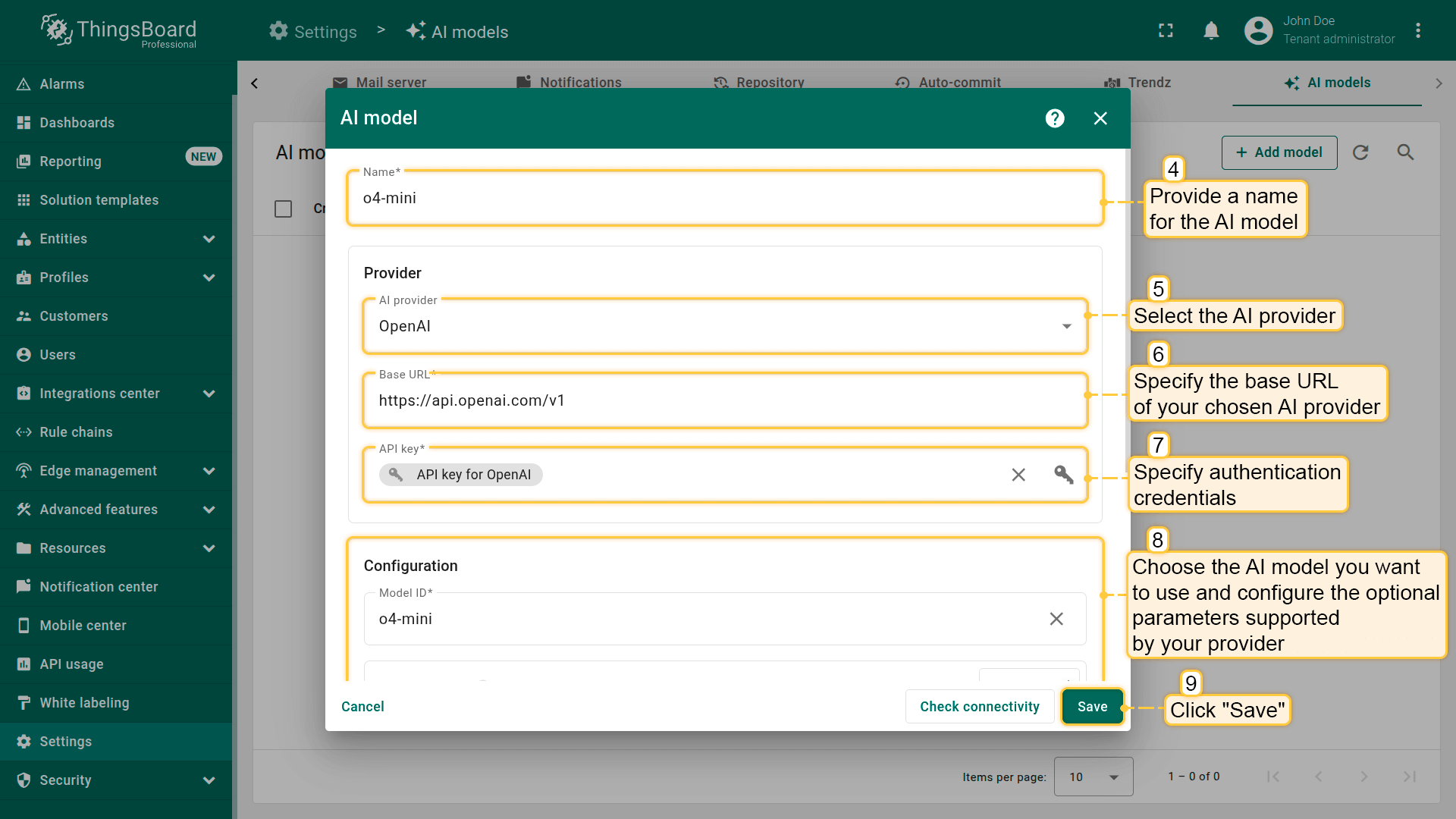
- Name - 为AI模型提供有意义的名称。
- Provider — 选择AI提供方,指定Base URL(仅OpenAI和Ollama需要),并输入该提供方的认证凭据。
- Model ID – 选择要使用的模型(在Azure OpenAI中为部署名称)。
- Advanced settings – 如提供方支持,可配置可选参数(如temperature、topP、最大tokens)。
- 点击”Save“完成添加。
保存后,模型可在Rule Engine的AI request node中使用。
- 名称 - 为 AI 模型指定有意义的名称。
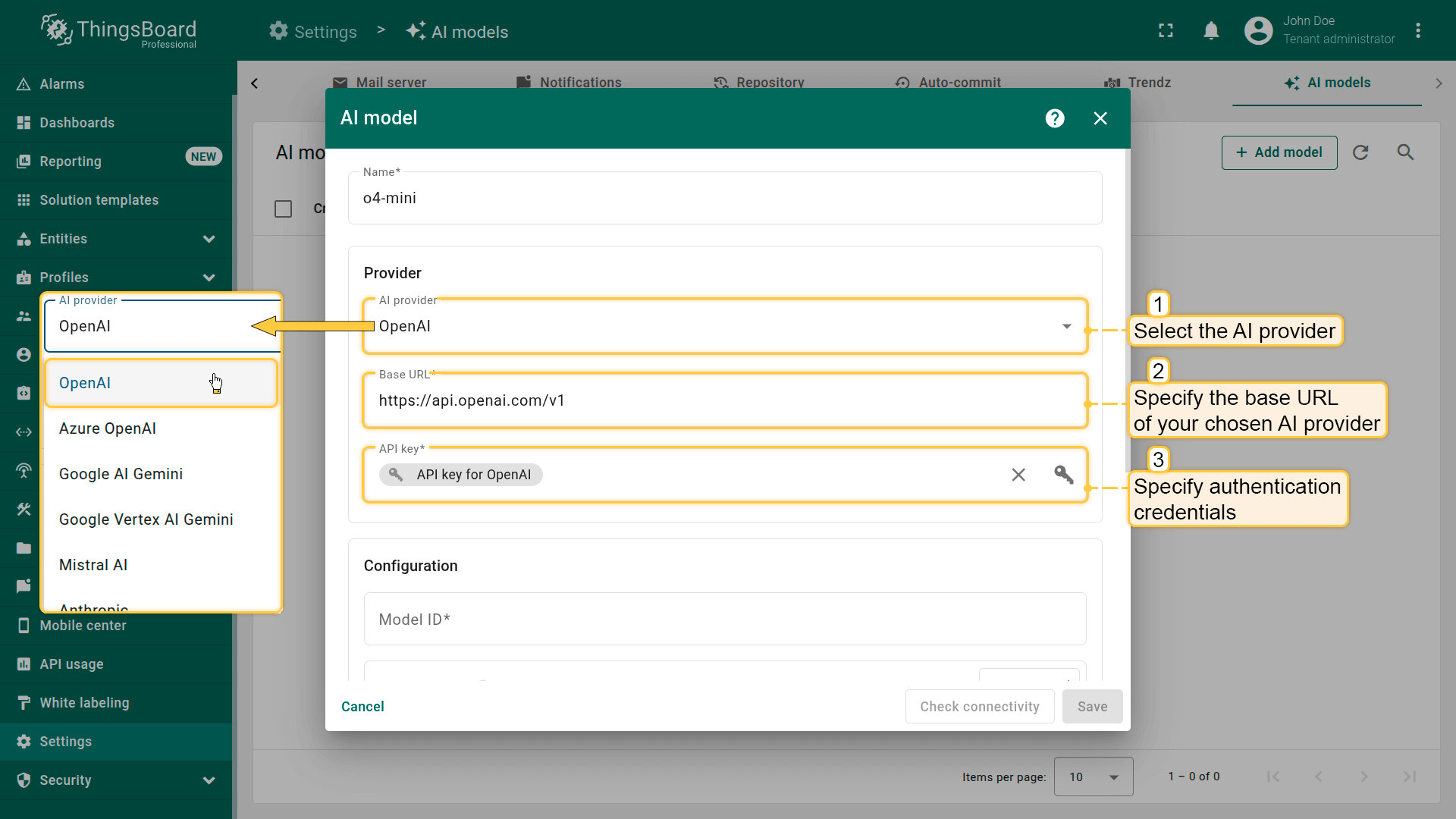
- Provider - 选择 AI 提供商并指定其认证凭据。
- Model ID - 选择要使用的模型(Azure OpenAI 则为部署名称)。
- 如提供商支持,可配置可选参数。
- 点击「保存」完成新 AI 模型的添加。
Provider配置
在Provider区域选择AI提供方,指定Base URL(仅OpenAI和Ollama需要),并输入认证凭据(如API密钥、密钥文件等)。
建议使用Secrets storage安全存储凭据。
支持的AI提供方
ThingsBoard目前支持以下AI提供方的集成:
OpenAI
- Base URL:指定访问OpenAI API的地址。
- Authentication:API密钥。
- 可从OpenAI仪表板获取API密钥。
使用OpenAI兼容模型
| 4.2.1及以上版本 |
使用兼容OpenAI API的模型时,一个重要参数是Base URL,它定义了向API发送请求所使用的地址。
官方Base URL
ThingsBoard中预配置的标准OpenAI API端点。用于访问OpenAI托管的模型。
自定义Base URL
实现OpenAI兼容API协议的提供方的替代端点。 当没有针对该提供方的专用集成且其提供OpenAI兼容API时使用(如DeepSeek、Qwen、自托管Ollama)。
使用自定义Base URL时,API密钥为可选。这样可支持无需认证的模型,如本地托管模型。但大多数云模型提供方仍需要有效的API密钥。
Base URL示例:
| Provider | Base URL |
|---|---|
| DeepSeek | https://api.deepseek.com |
| Alibaba Qwen (Singapore) | https://dashscope-intl.aliyuncs.com/compatible-mode/v1 |
| Ollama (local) | http://localhost:11434/v1 |
Ollama也作为独立集成提供,具有更多配置选项。
Azure OpenAI
- Authentication:API key和endpoint。
- 需在Azure AI Studio中创建目标模型的deployment。
- 从deployment页面获取API key和endpoint URL。
- 可选:可设置service version。
Google AI Gemini
- Authentication:API密钥。
- 可从Google AI Studio获取API密钥。
Google Vertex AI Gemini
- Authentication:Service account key file。
- 必需参数:
- Google Cloud Project ID。
- 目标模型所在区域(region)。
- 具有与Vertex AI交互权限的Service account key file。
Mistral AI
- Authentication:API密钥。
- 可从Mistral AI门户获取API密钥。
Anthropic
- Authentication:API密钥。
- 可从Anthropic控制台获取API密钥。
Amazon Bedrock
- Authentication:AWS IAM凭据。
- 必需参数:
- 访问密钥ID。
- 秘密访问密钥。
- AWS区域(推理运行所在区域)。
不支持使用Bedrock API密钥进行Authentication。
GitHub Models
- Authentication:个人访问令牌。
- 令牌需具有
models:read权限。 - 可按照此指南创建令牌。
Ollama
| 4.2.1及以上版本 |
Ollama让您可以在本机轻松运行Llama 3、Mistral等开源大语言模型。支持本地实验、离线使用以及对数据的更好掌控。
要连接Ollama服务,需要其Base URL(如http://localhost:11434)和认证方式。支持以下选项:

- None
- 标准Ollama安装的默认方式。
- 无需认证,请求中不发送凭据。
- Basic
- 当Ollama位于需要HTTP基本认证的反向代理之后时使用。
- 提供的用户名和密码组合为
username:password字符串,进行Base64编码后以header形式发送:1
Authorization: Basic <encoded_credentials>
- Token
- 当Ollama位于需要Bearer令牌认证的反向代理之后时使用。
- 提供的令牌在header中发送:
1
Authorization: Bearer <token>
安全建议:使用Basic或Token认证时,始终通过HTTPS URL连接。使用明文HTTP会在网络上明文传输凭据,不安全。
Model配置
选择并完成AI提供方的认证后,需指定要使用的具体AI模型(Azure OpenAI中为部署名称)。
对于部分提供方(如OpenAI),ThingsBoard提供自动完成选项,列出常用模型。 您不限于该列表 — 可指定该提供方支持的任意模型ID,包括模型别名或快照。 生产环境建议使用模型快照以确保行为可预测(模型别名可能被提供方更新并指向新快照,从而影响响应质量)。
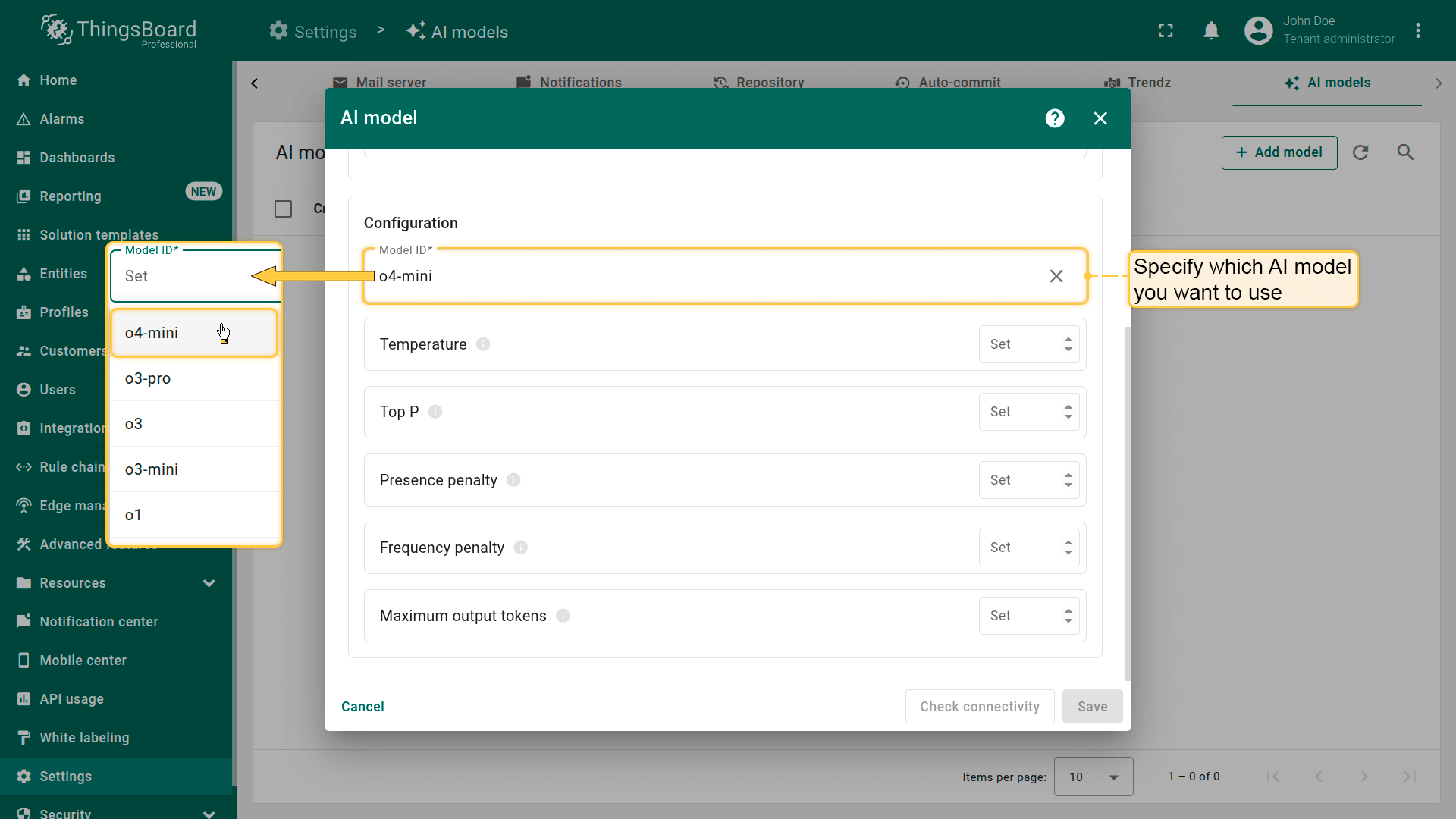
高级模型设置
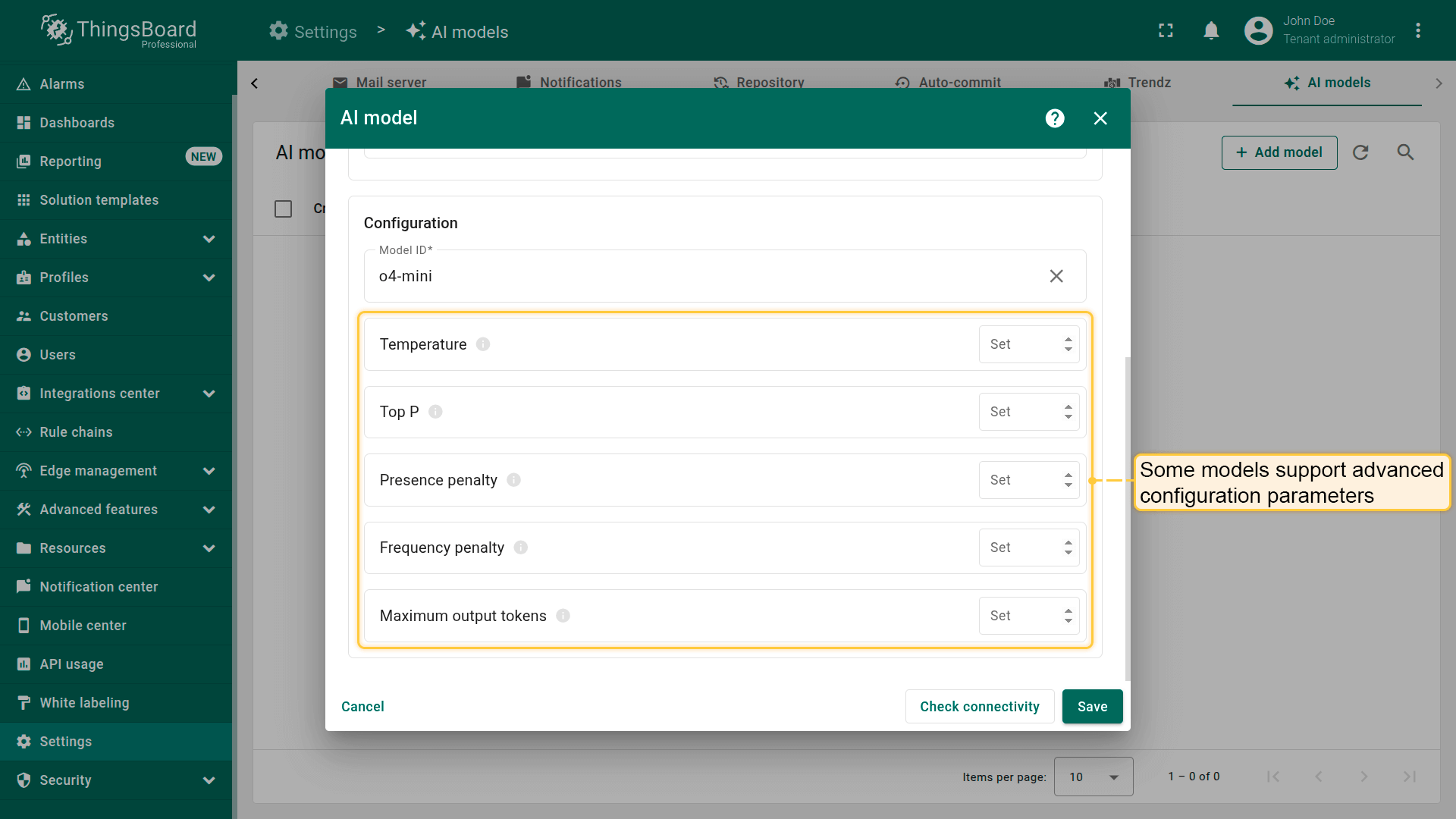
部分模型支持高级配置参数(取决于提供方),例如:
- Temperature – 调整模型输出随机度。值越高越随机,越低越确定。
- Top P – 为模型创建最可能的token池。值越大池越大、越多样,越小越聚焦。
- Top K - 将模型选择限制在”K”个最可能的token的固定集合内。
- Presence penalty - 对已出现过的token施加固定惩罚。
- Frequency penalty - 根据token在文本中的出现频率施加递增惩罚。
- Maximum output tokens – 设置模型单次响应可生成的最大token数。
- Context length – 以token为单位定义上下文窗口大小。此值设置模型的总内存限制,包括用户输入和模型生成的响应。
如果高级设置导致错误,可尝试移除其值。此时将应用默认值。这通常可解决与某些模型的兼容性问题。
连接测试
点击Check connectivity按钮验证配置。 将使用提供的凭据和模型设置向提供方API发送测试请求。
若响应成功,将显示✅绿色勾选。
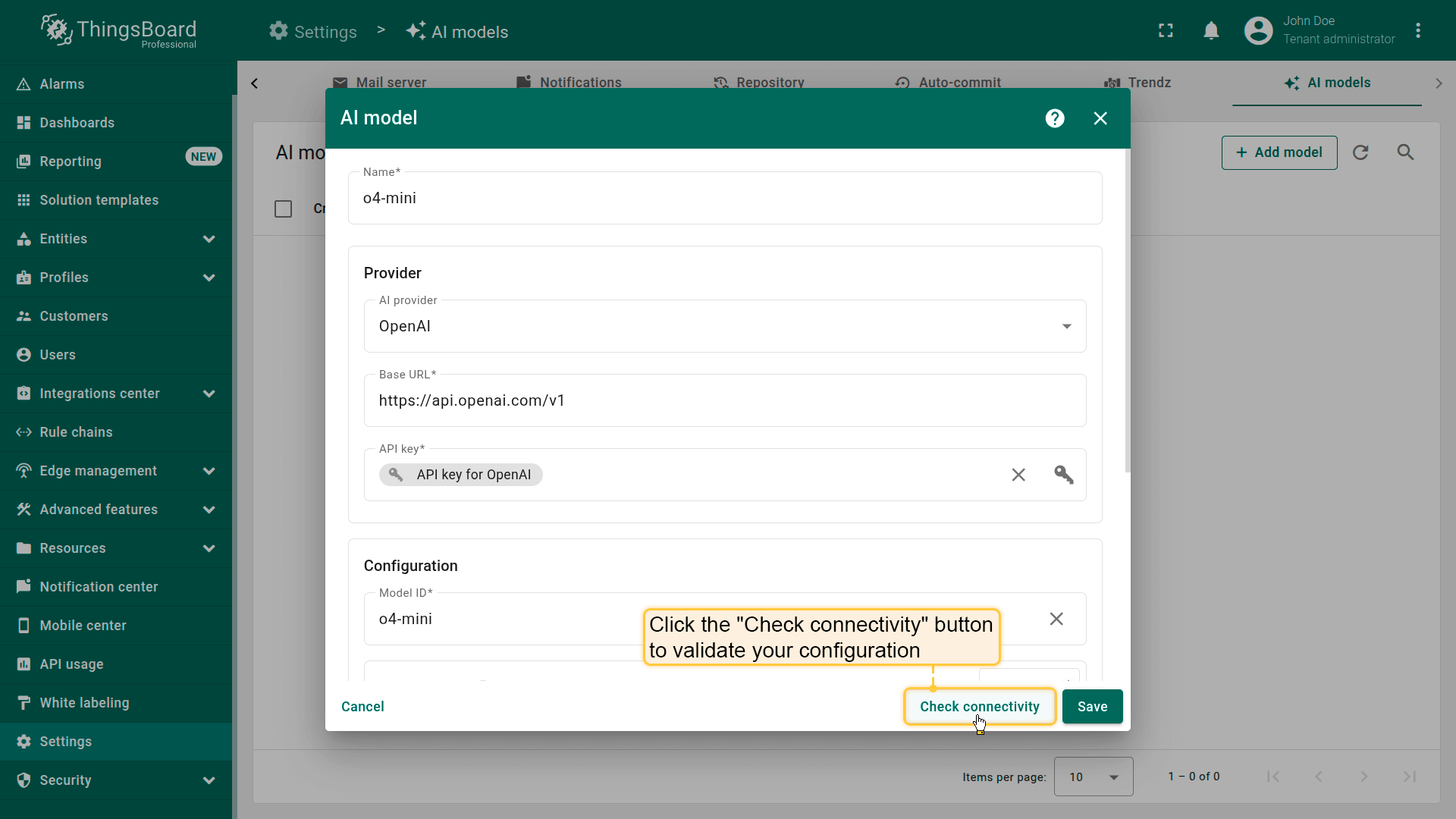
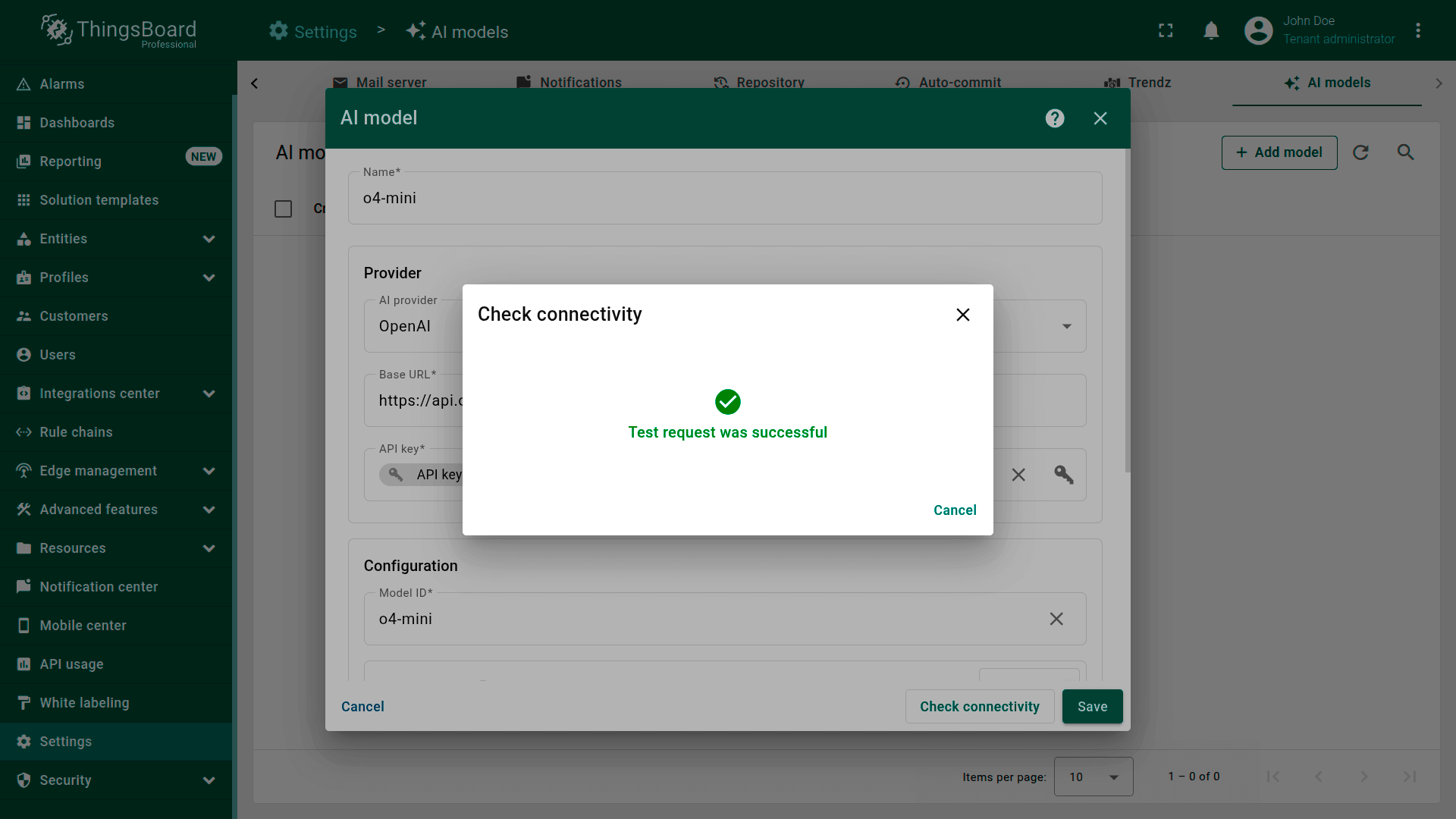
配置提供方后始终使用连接性检查,以确保运行时正常执行。
若发生错误(如无效API密钥、不存在的模型),将显示带详情的错误消息❌。
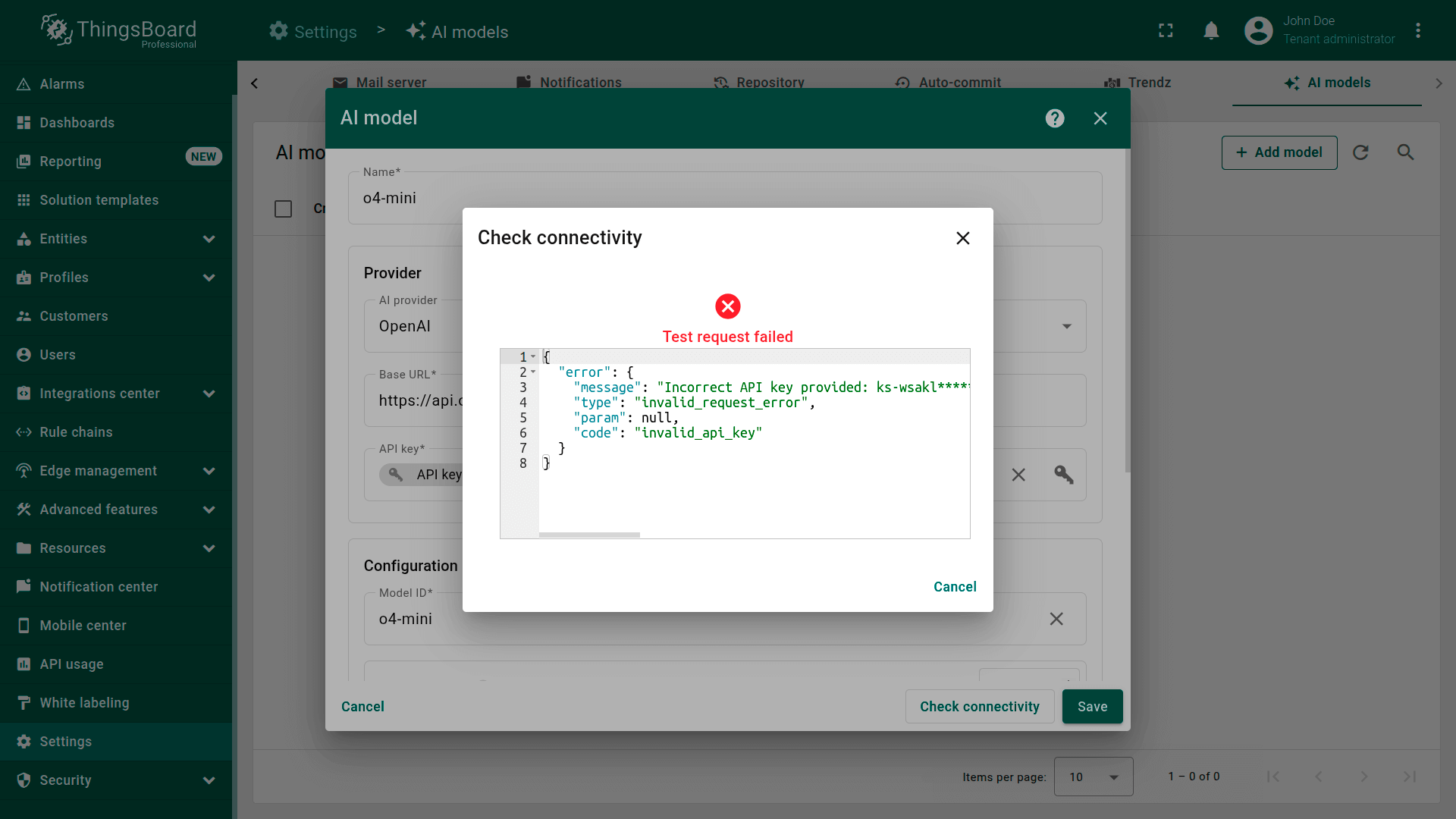
此功能可确保配置有效,并在生产环境中使用模型时避免运行时错误。
尽管测试请求较简单(如”某国的首都是哪里?”),提供方通常仍会收费。但费用很低。