异常检测理论
异常检测是指识别遥测数据中意外行为的过程——即与正常情况显著不同的模式。这些异常可能预示着系统故障、设备退化、安全漏洞或运行低效。
在现代监测与分析中,异常检测对于以下方面至关重要:
- 预测性维护
- 早期故障检测
- 运行效率
Trendz 提供开箱即用的强大异常检测解决方案,能自动发现时序数据中的异常模式,无需人工设定阈值或专家标注。对于高级用户,Trendz 还提供对模型配置流程的全面控制——包括输入准备、特征提取、距离函数调优和评分逻辑——均通过便捷直观的界面完成。
您可在此了解如何使用 Trendz Analytics 创建异常检测模型:
Trendz 异常检测核心概念
在 Trendz 中,异常检测基于两个核心指标:
-
异常分数(Anomaly Score)
表示数据段偏离预期(正常)行为的数值,可理解为衡量异常的强度。 -
异常分数指数(Anomaly Score Index)
将异常分数与异常的持续时间结合的综合指标,有助于优先发现随时间影响更大的异常。
实际示例:泵振动分析
以下示例展示泵启动后的振动情况:
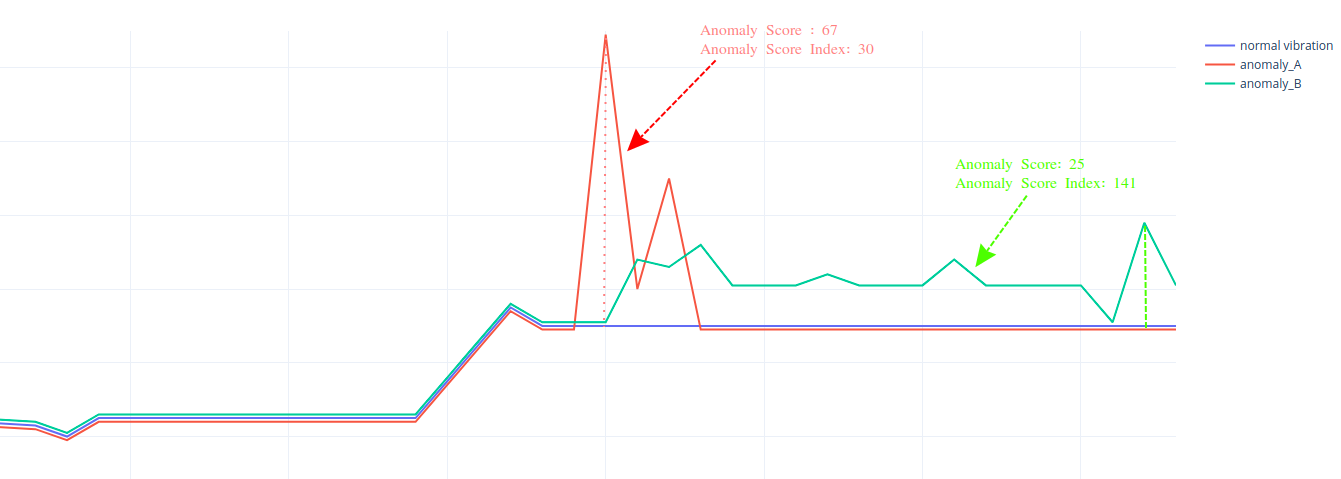
- 异常 A
- 表现为持续约 5 秒的剧烈振动尖峰。
- 因突然偏离导致异常分数较高。
- 持续时间短,故分数指数较低。
- 异常 B
- 无大幅尖峰,但偏离持续时间更长。
- 异常分数较低,但因时长增加使分数指数更高。
- 提示对泵健康的长期影响更大。
虽然异常 A 因尖峰乍看更严重,但异常 B 因持续影响往往更需要调查——这正是异常分数指数要揭示的内容。
- 使用异常分数检测剧烈、短期偏离。
- 使用异常分数指数发现可能随时间造成更大损害的持续异常。
监督式与非监督式异常检测
-
监督式异常检测:
需要预先标注正常与异常片段的标注数据集。
模型根据标签学习分类数据点。常见算法包括 KNN、SVM、逻辑回归、决策树和 LSTM。
局限: 需要大量标注数据,难以检测训练集中未出现的新异常类型。 -
非监督式异常检测:
无需标注数据。模型通过将相似数据段分组为簇来学习正常行为模式,并将显著偏离这些簇的点视为异常。
常见算法包括 K-Means、DBSCAN、高斯混合模型和层次聚类。
优势: 自动检测未知异常类型,适用于标注数据有限的现实场景。
Trendz 目前仅支持非监督式机器学习算法进行异常检测,采用基于聚类的方法在时序数据中检测异常。
Trendz 中非监督式异常检测的工作流程
- 收集并分割遥测数据。
- 数据规范化与预处理。
- 提取描述各段的特征。
- 将数据段聚类为代表正常行为的组。
- 根据与簇质心的距离计算异常分数。
- 实时应用模型以实现持续异常检测。
标签页概述
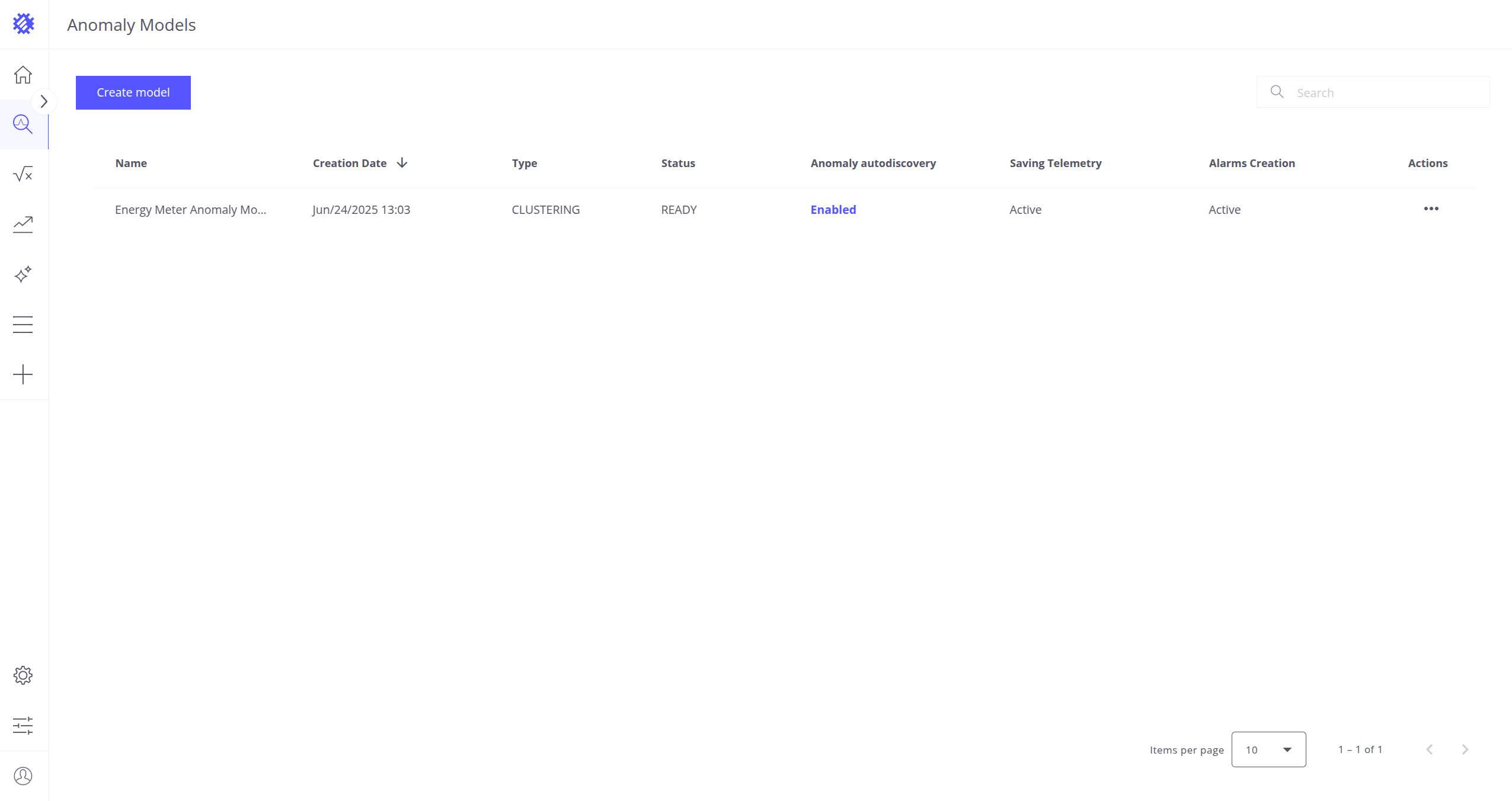
异常模型标签页
访问异常模型页面:在工作区左侧点击标有 Anomaly Models 的图标。
该页面展示各模型的主要属性:
- 创建日期
- 名称
- 类型 – 当前仅支持 CLUSTERING
- 状态:
- READY – 模型已就绪,可进行异常检测
- QUEUED – 等待训练任务启动
- IN PROGRESS – 正在训练
- CANCELLED – 训练已取消,需重新构建
- FAILED – 训练失败,需重新构建
- 异常自动发现 – 了解更多
- 遥测保存 – 了解更多
- 告警自动创建 – 了解更多
可用操作:
- 创建模型
- 点击屏幕右上角的 Create model 按钮创建新异常模型。
- 将跳转到输入标签页配置模型。
- 了解输入标签页详情
- 查看模型
- 点击任意模型行以打开并查看。
- 将跳转到输入标签页。
- 了解输入标签页详情
- 删除模型
- 在 Actions 列点击三点菜单,选择 Delete。
- 在确认对话框中确认删除。
- 重命名模型
- 在 Actions 列点击三点菜单,选择 Rename。
- Name 列将出现文本框。
- 输入新名称并按 Enter 保存。
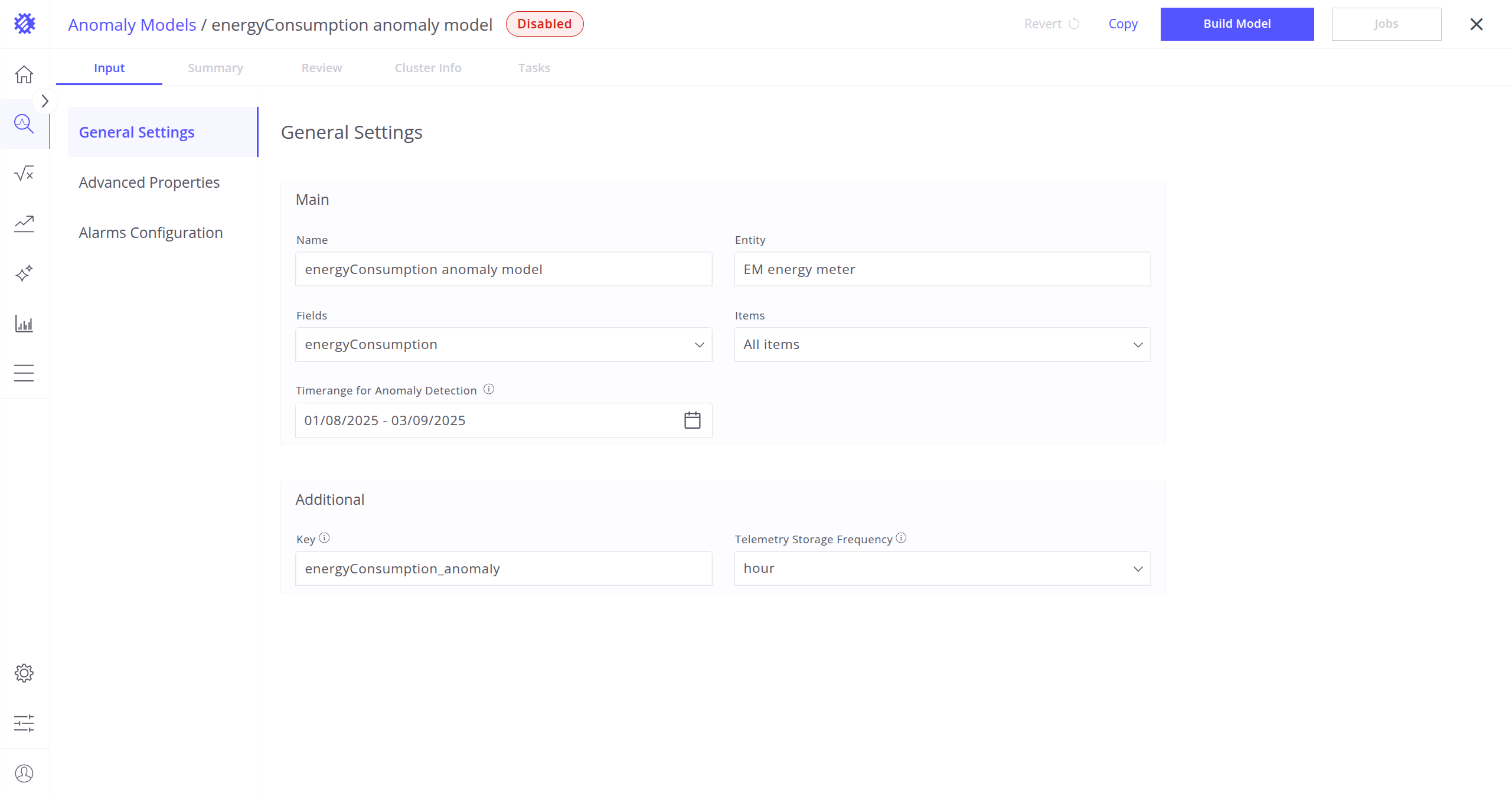
输入标签页
输入标签页可用于管理和配置异常模型的核心方面,支持:
- 重命名模型
- 点击模型名称旁的铅笔图标,输入新名称并按 Enter。
- 要应用新名称,点击 Save Model。此更改无需重新构建。
- 恢复模型
- 点击屏幕右上角的 Revert 按钮可放弃未保存更改并恢复到上次保存状态。
- 配置作业
- 仅 READY 状态的模型可配置作业。
- 点击屏幕上方的 Jobs 按钮打开作业配置弹窗。
- 在此可配置刷新作业(了解刷新作业详情)。
- 修改属性
- 可在输入标签页更新多种异常模型属性(了解模型属性详情)。
- 要应用更改,点击 Save Model。除非修改以下内容,否则无需重新构建:
- Anomaly Model Name
- Telemetry key
- Telemetry storage frequency
- Alarm Configuration
- Save Model(保存模型)
- 使用 Save Model 按钮保存更改或发起重新构建。
- 若需要重新构建,将出现确认弹窗。
- 注意: 重新构建模型将删除所有现有异常并禁用刷新作业。
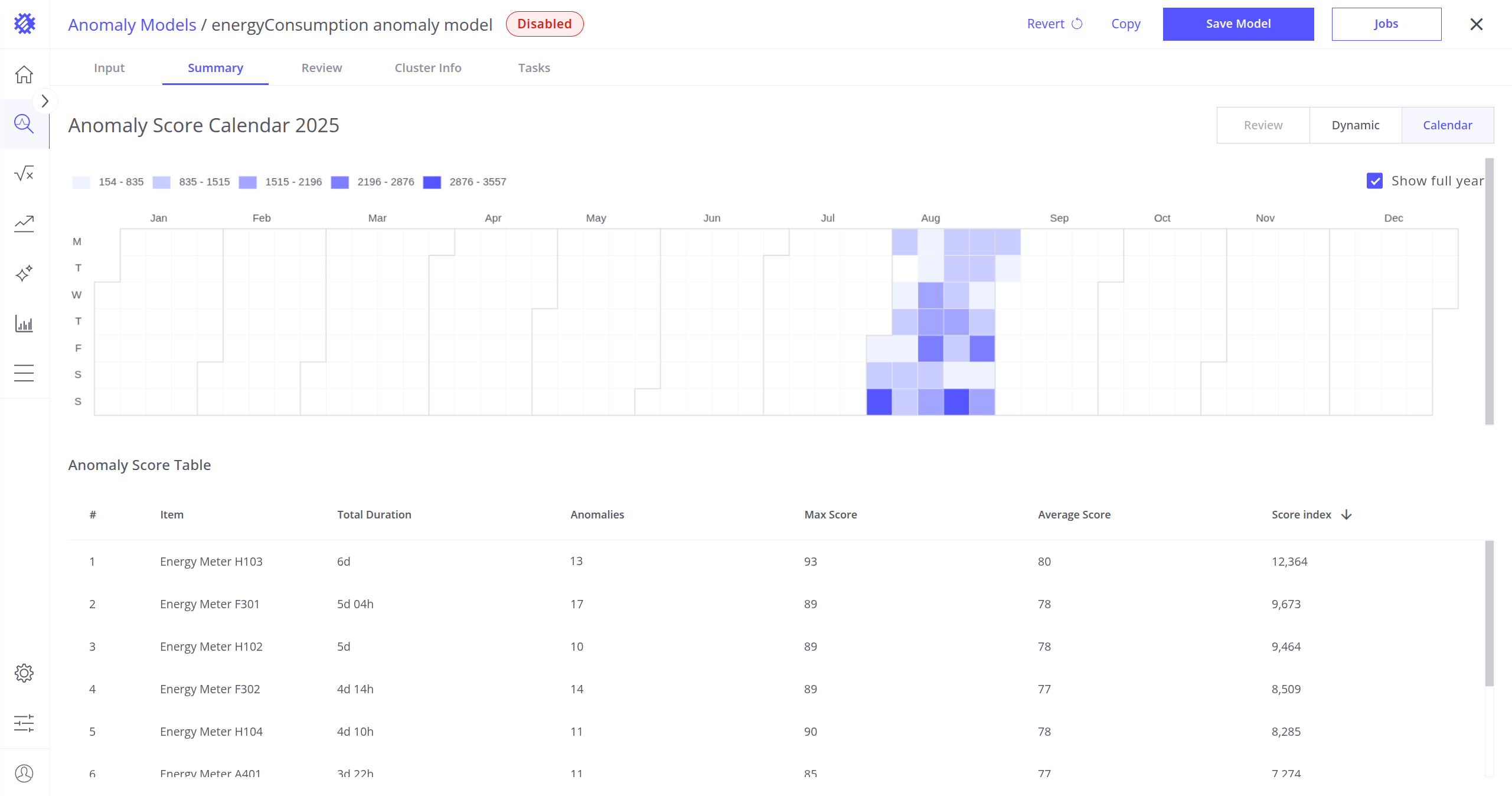
摘要标签页
Summary 标签页提供按设备分组的异常概览。
您可以:
- 查看所有设备或特定设备的异常统计。
- 使用图表下方表格选择或取消选择设备。
- 使用屏幕右上角的 Review、Dynamic 和 Calendar 按钮选择显示模式。
可用模式
- Calendar Mode(日历模式,全部设备):
- 显示所有项目的每日异常指数总和。
- 默认仅显示有异常的月份。
- 启用 Full Range 开关可查看全年。
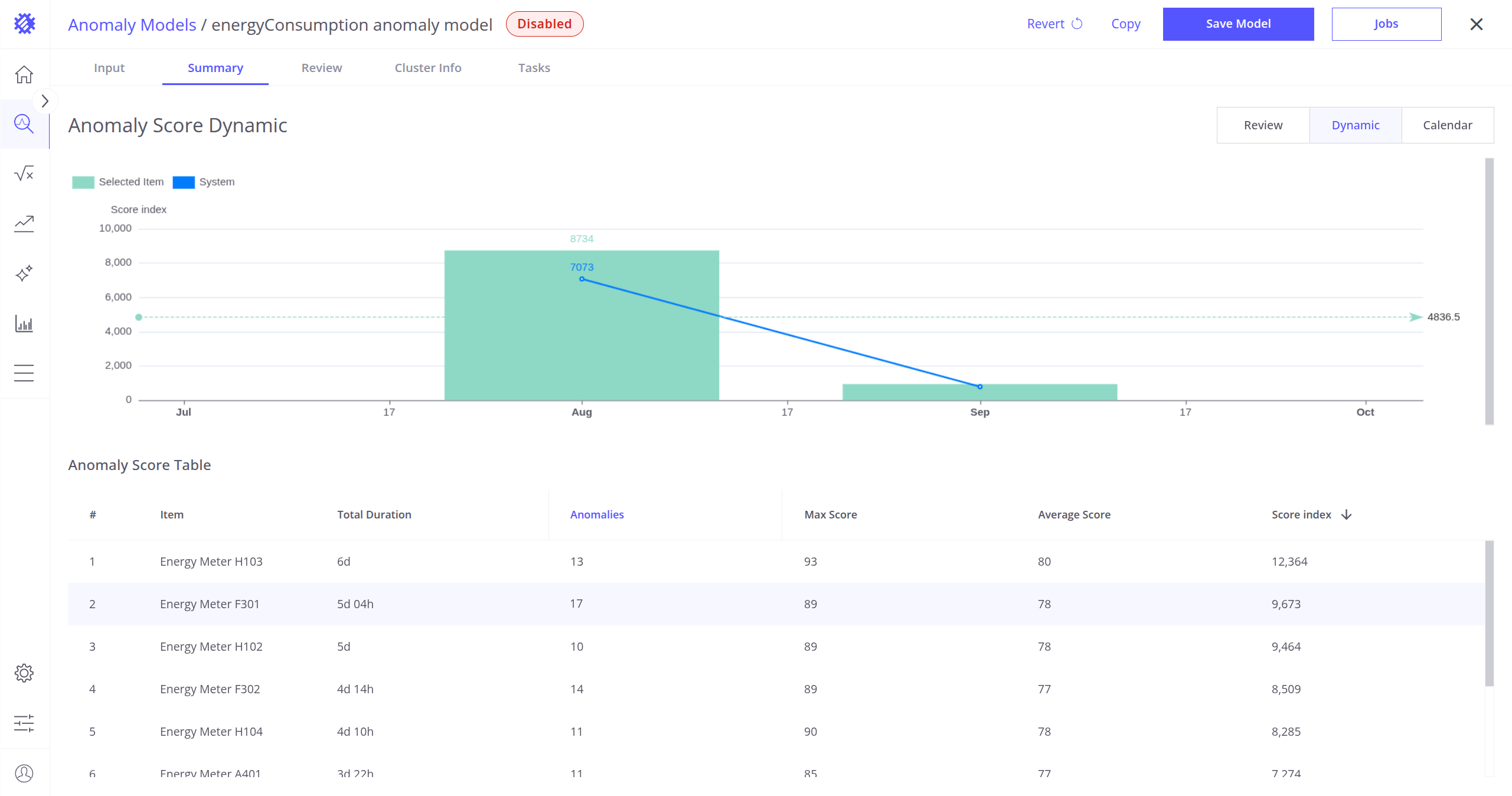
- Dynamic Mode(动态模式,仅所选设备):
- 可视化所选设备的月度异常分布。
- 绿色柱表示当前设备的异常分数指数总和。
- 蓝色线表示所有设备的月度平均分数指数总和。
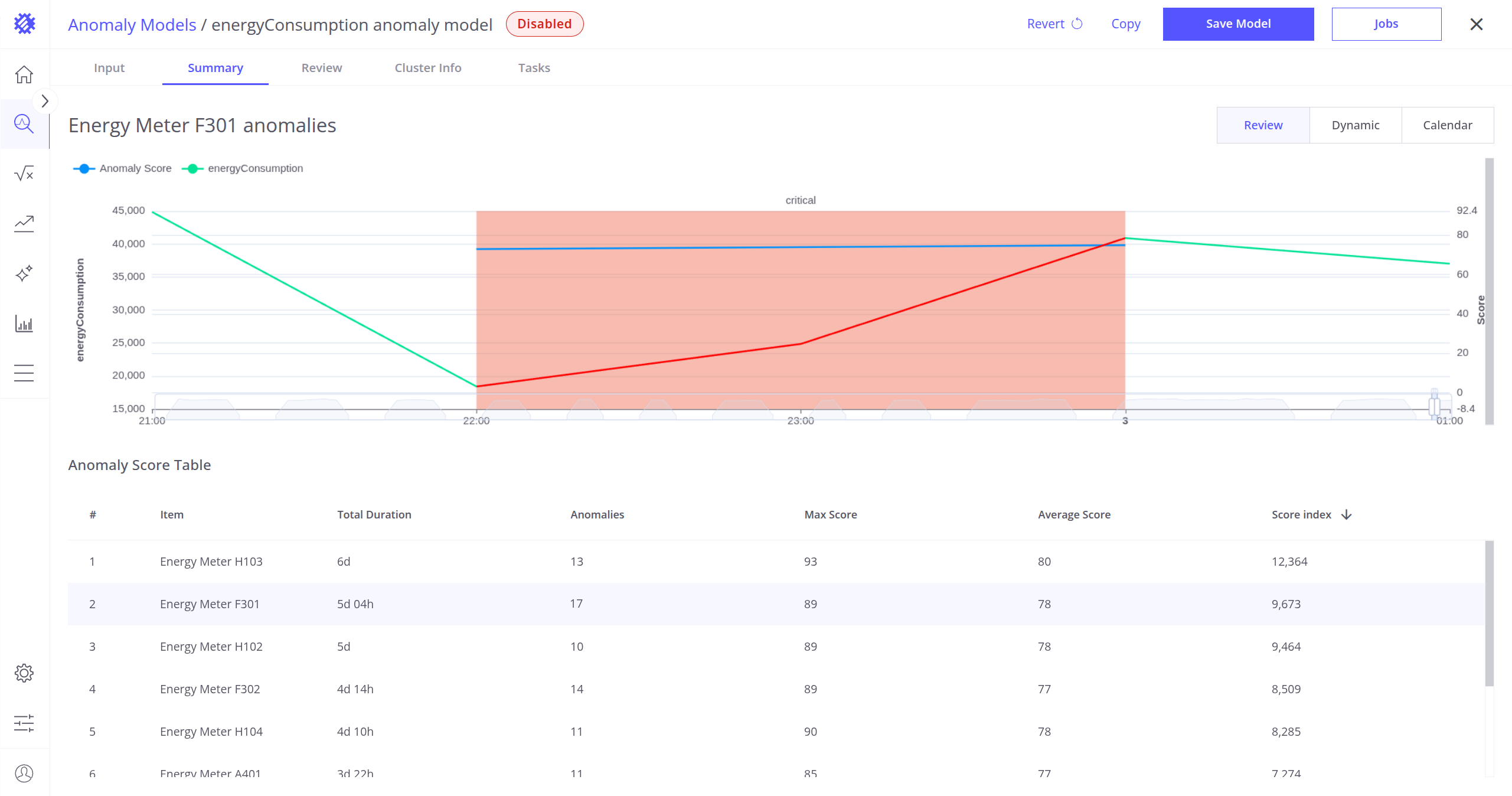
- Review Mode(审阅模式,仅所选设备):
- 显示最新检测到的异常。
- 可放大或缩小查看当前设备的完整异常历史。
审阅标签页
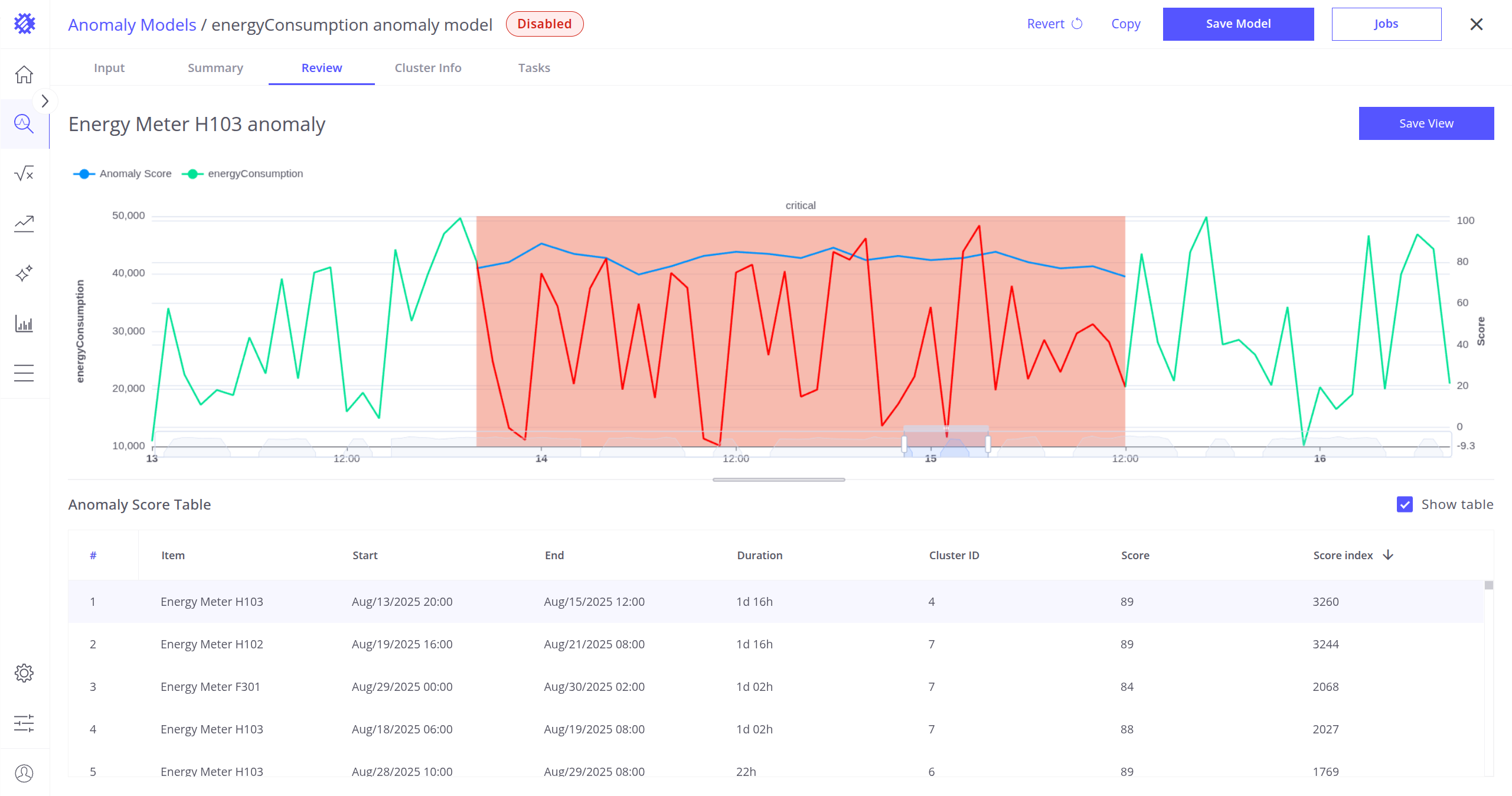
Review 标签页可查看构建、刷新或重新处理期间检测到的所有异常。
您可在此标签页:
- 验证异常模型发现的异常。
- 通过查看结果并在需要时重新训练来微调模型。
- 确定告警创建的最优阈值(了解更多告警说明)。
可按以下字段排序异常以便更好分析:
- Total Duration(总持续时间)
- Score(分数)
- Score Index(分数指数)
- Item(设备)
- End Timestamp(结束时间戳)
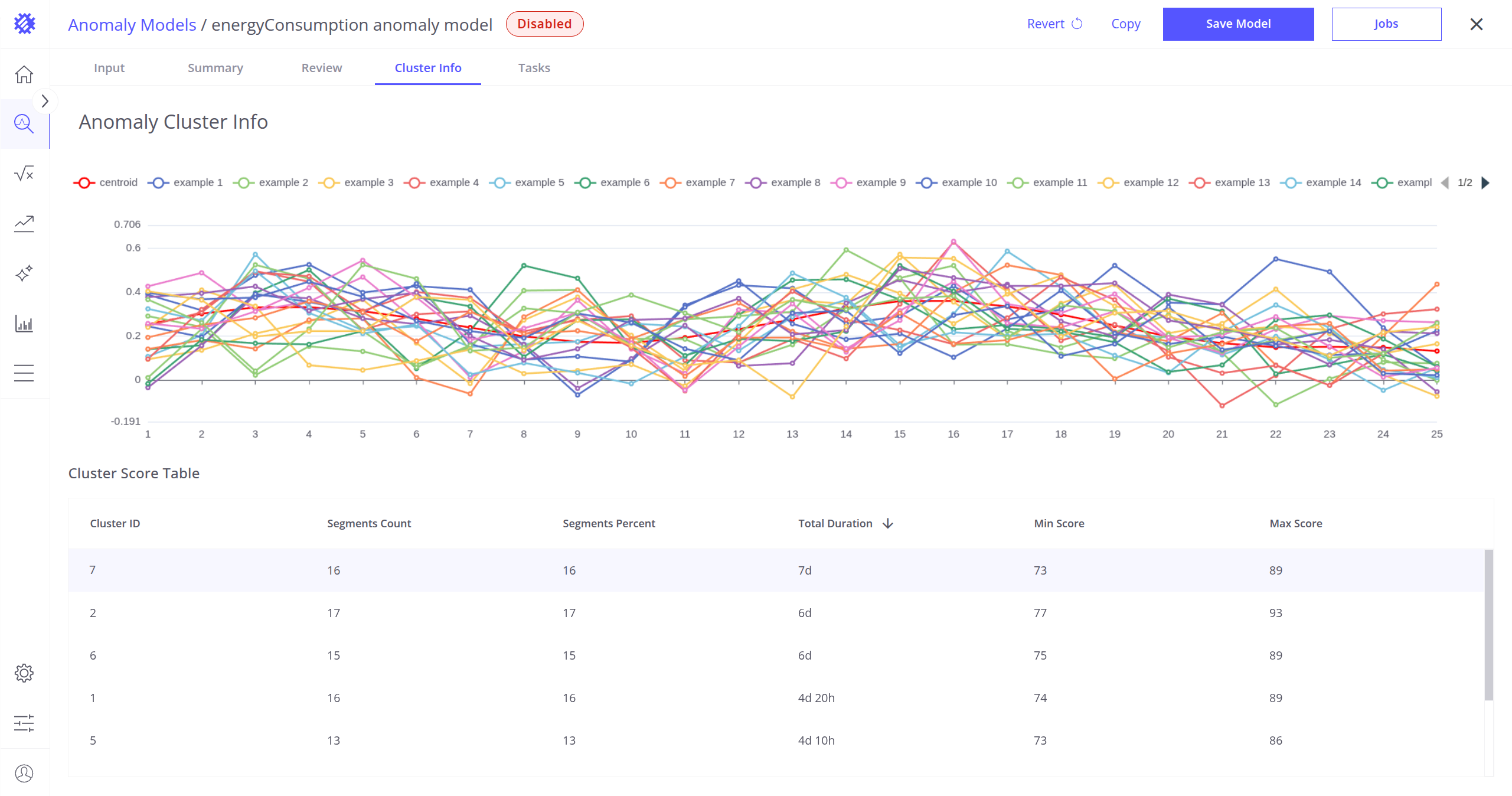
簇信息标签页
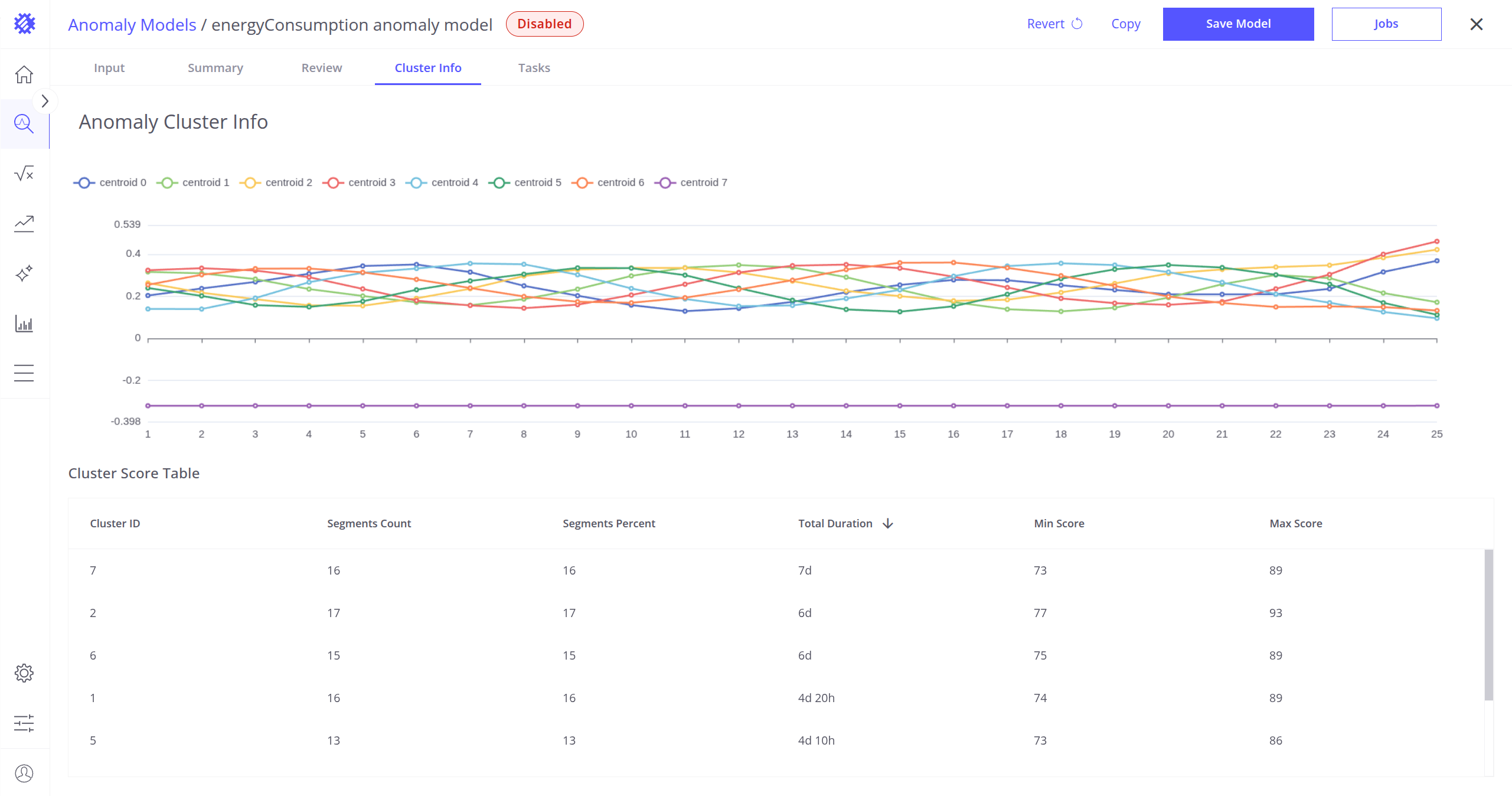
在此标签页可验证模型构建过程中创建的簇。
Cluster Info 标签页显示形成了多少簇、它们代表的形状或模式,以及数据段在各簇间的分布。
簇表
屏幕底部显示包含以下列的表:
- Cluster ID – 簇的唯一标识符。
- Segments Count – 最接近该簇的异常段数量。
- Segments Percent – 落入该簇的异常段百分比。
- Total Duration – 最接近该簇的所有异常段的总持续时间。
- Min Score – 最接近该簇的段中的最小异常分数。
- Max Score – 最接近该簇的段中的最大异常分数。
质心可视化
屏幕顶部可查看所有簇的质心。每个质心代表属于该簇的所有段的平均模式。这些曲线有助于理解各簇捕获的典型形状或行为。
也可点击簇表中的任意行打开详情视图。该视图显示:
- 选中的质心,以及
- 属于该簇的20+ 个随机段。
此功能便于在簇内直观比较段的可变性并验证聚类准确性。
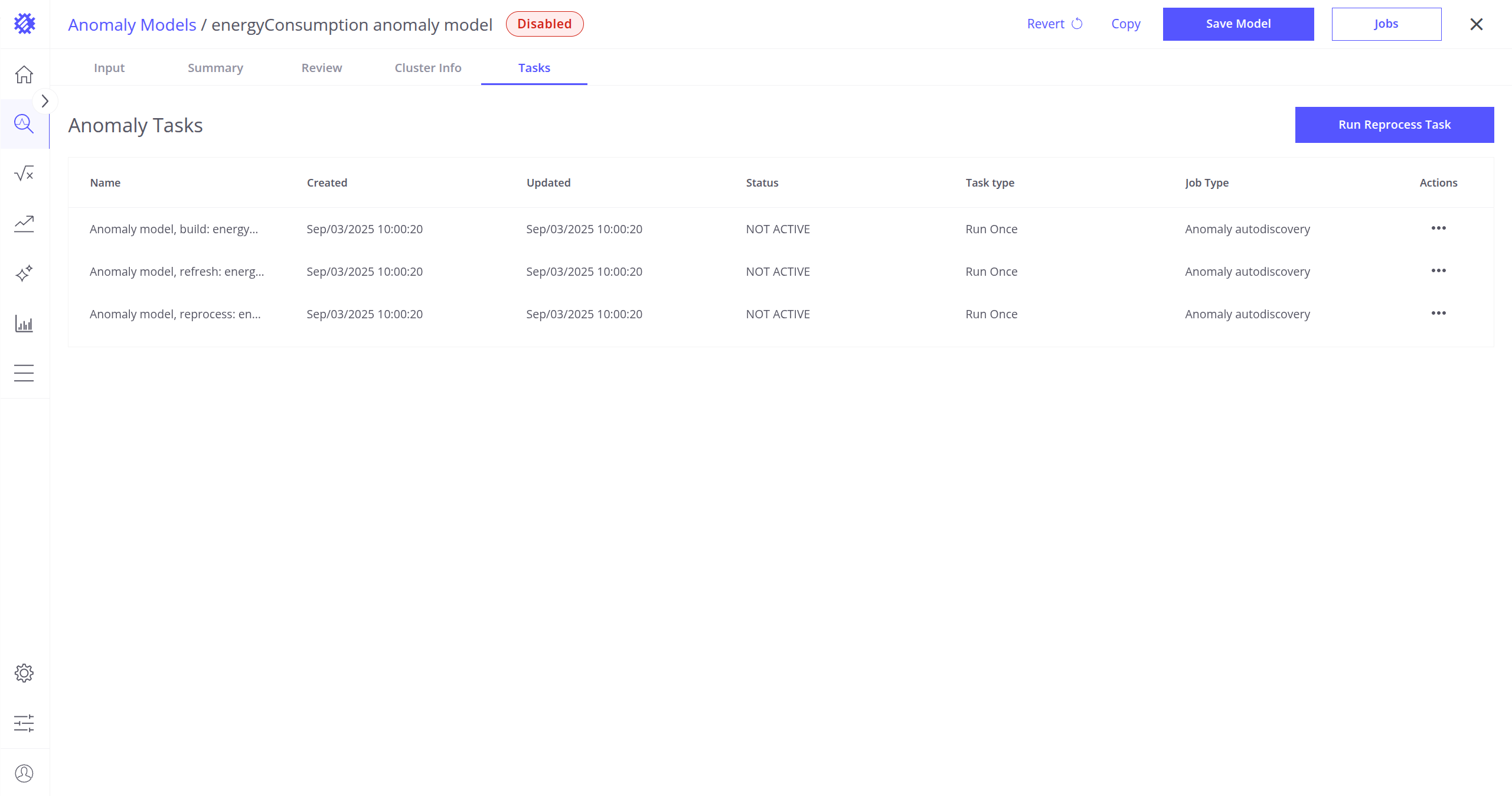
任务标签页
在任务标签页中可查看与当前异常模型关联的任务。可在此验证如下任务:
- 异常模型构建
- 异常模型刷新
- 异常模型重新处理
可查看其结果、上次执行时间等。更多 Trendz 任务说明。
也可通过点击屏幕右上角的 Run Reprocess Task 按钮,直接从此标签页运行异常模型重新处理任务(更多异常重新处理说明)。
下一步
-
快速入门指南 - 快速了解 Trendz 主要功能。
-
安装指南 - 学习在各种操作系统上部署 Trendz。
-
指标探索器 - 学习使用 Trendz Metric Explorer 探索和创建指标。
-
字段计算 - 了解字段计算及使用方法。
-
状态 - 学习基于原始遥测定义和分析资产状态。
-
预测 - 学习进行预测及遥测行为预测。
-
筛选器 - 学习在分析中筛选数据集。
-
可用可视化部件 - 了解 Trendz 中可用的可视化部件及配置方法。
-
分享与嵌入可视化 - 学习将 Trendz 可视化添加到 ThingsBoard 仪表盘或第三方网页。
-
AI 助手 - 学习使用 Trendz AI 功能。