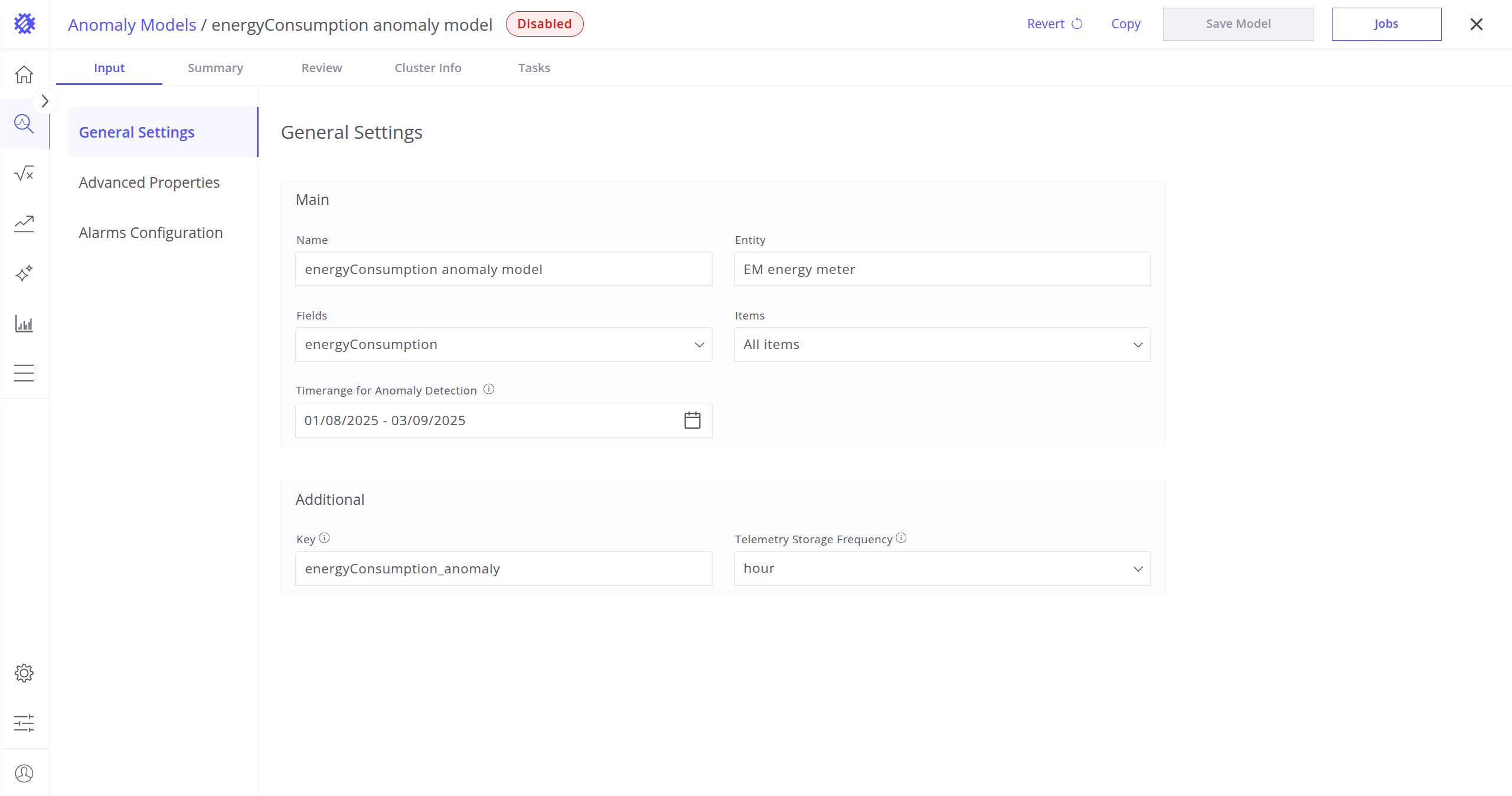
异常模型属性
通用设置
通用设置是创建异常模型时最重要的部分,用于确定参与训练异常模型的实体、遥测(或设备)以及时间范围。
-
实体:选择要进行异常检测的实体,用于确定异常模型的上下文。
-
字段:选择要分析的实体内具体字段,例如能耗、温度或其他可测参数。
说明:当前仅支持选择数值型遥测。
建议只选择可能相互关联的字段,例如振动可能与电机温度或负载相关。 -
项目(用于模型训练):在实体中选择要分析的具体项目(如某台设备或资产)。
建议优先选择最接近正常状态的数据以提升异常检测效果(可先对所有资产建一次模型以识别)。 -
异常检测时间范围(用于模型训练):定义模型训练使用的历史数据区间,例如过去 3 个月或 1 年,视数据可用性与相关性而定。
此外,可在此配置遥测保存选项。
-
Key:在重新处理/刷新时用于将异常分数及异常分数索引保存到ThingsBoard的遥测键名。
-
遥测存储频率:指定异常分数及异常分数索引在ThingsBoard中的聚合存储粒度。
建议使该频率:- 小于分段时间范围(固定分段策略时)
- 小于「分段大小 × 滑动步长% / 100」(滑动窗口策略时)
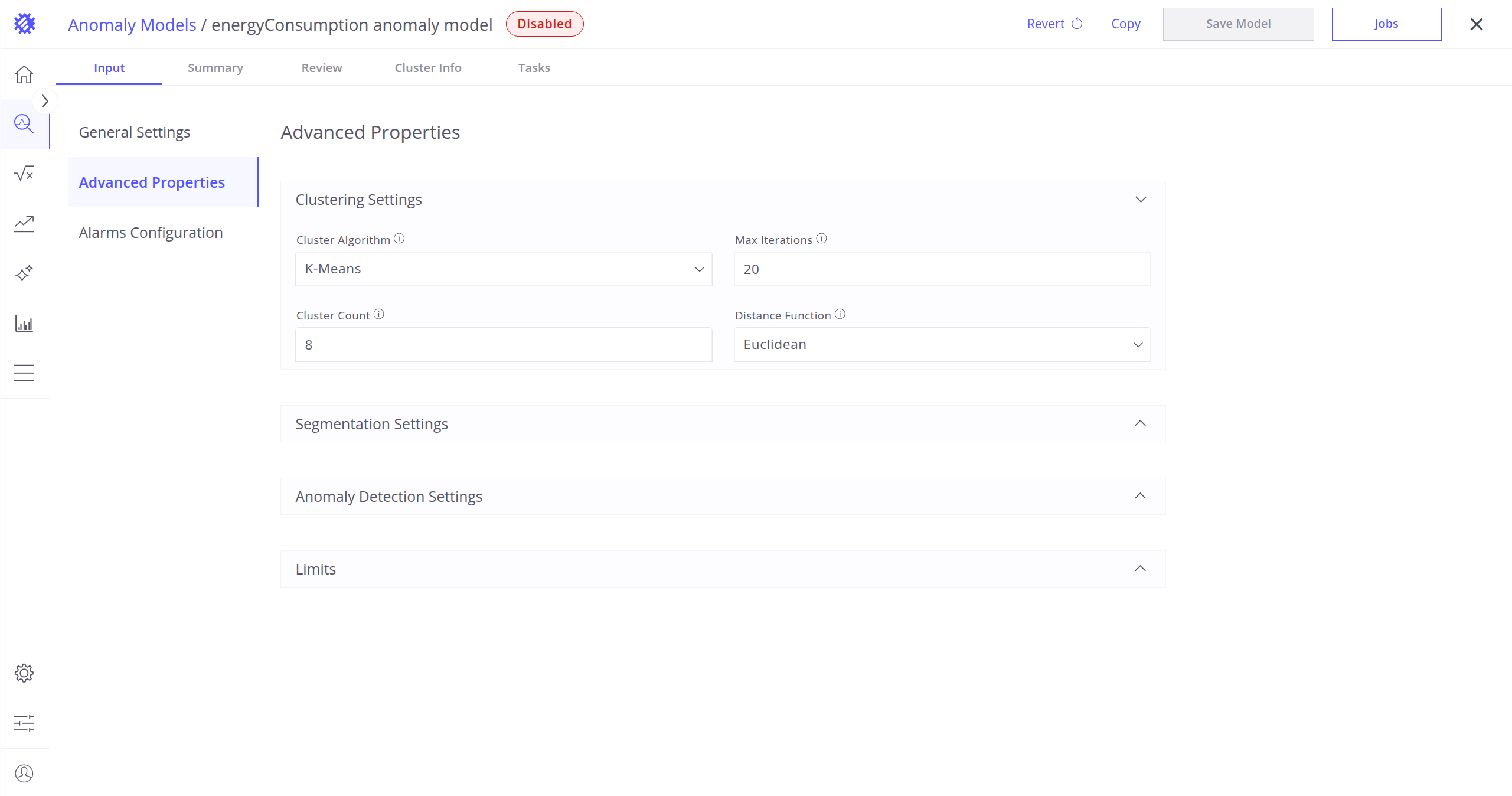
Advanced Properties
Clustering Settings
These settings define which clustering algorithm will be used to detect anomalies in your telemetry data, and how it will work.
- Cluster Algorithm: Choose how the data will be grouped into clusters. Points that don’t fit well into any group will be considered anomalies.
Supported methods:-
K-Means: Splits data into a fixed number of groups. Anomalies are points far from their group center.
Use when: Data is clean, consistent, and you know how many clusters to expect.
Learn more about K-Means.Additional parameters:
- Max Iterations: How many times K-Means should try to improve the clustering.
-
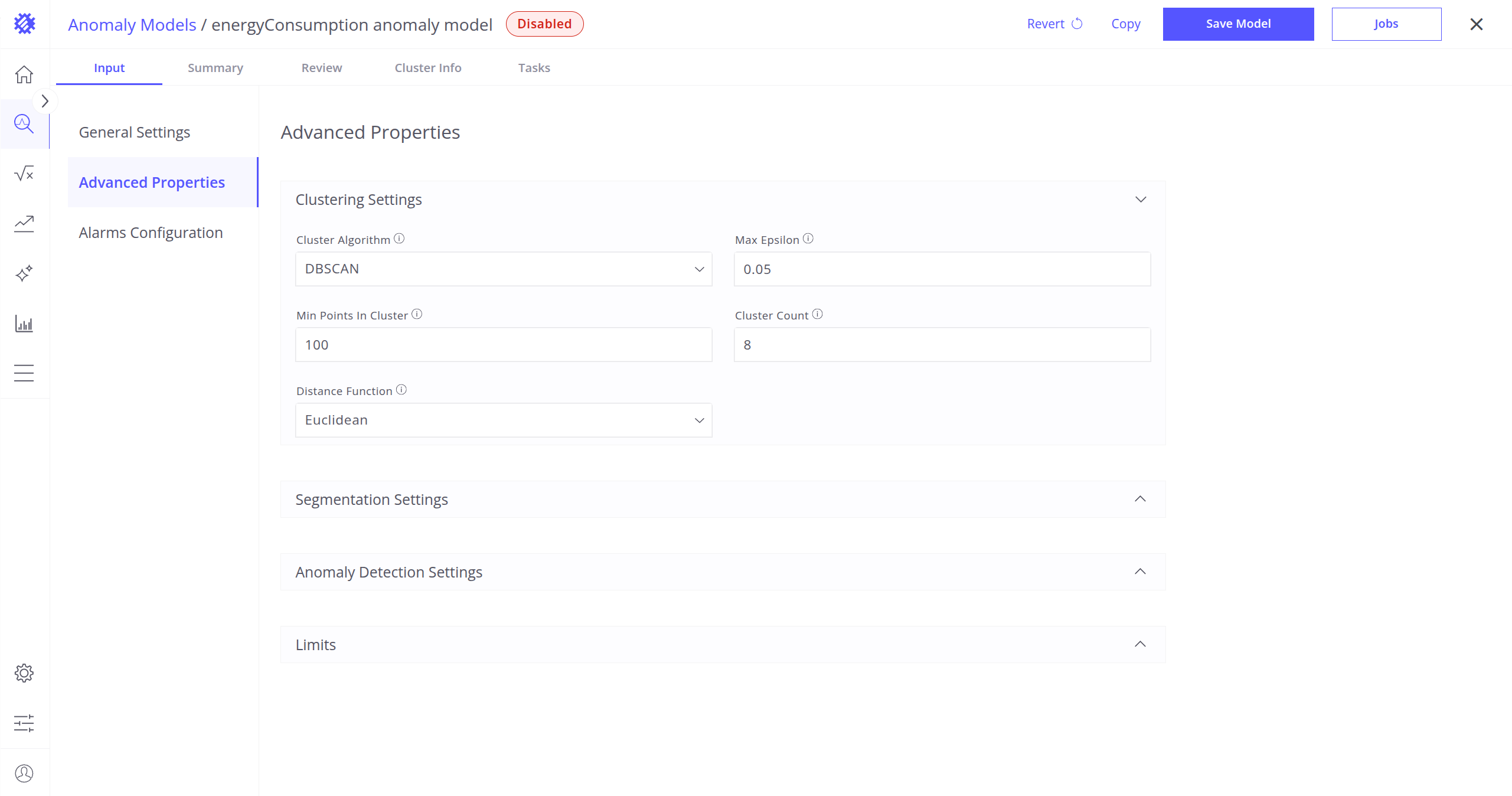
DBSCAN: Groups data based on how close and dense points are. Anomalies are isolated or low-density points.
Use when: You have noisy data or clusters of different shapes/sizes.
Learn more about DBSCAN.Additional parameters:
- Max Epsilon: Maximum distance between points to consider them as part of the same group.
- Min Points in Cluster: Minimum number of nearby points to form a valid cluster.
-
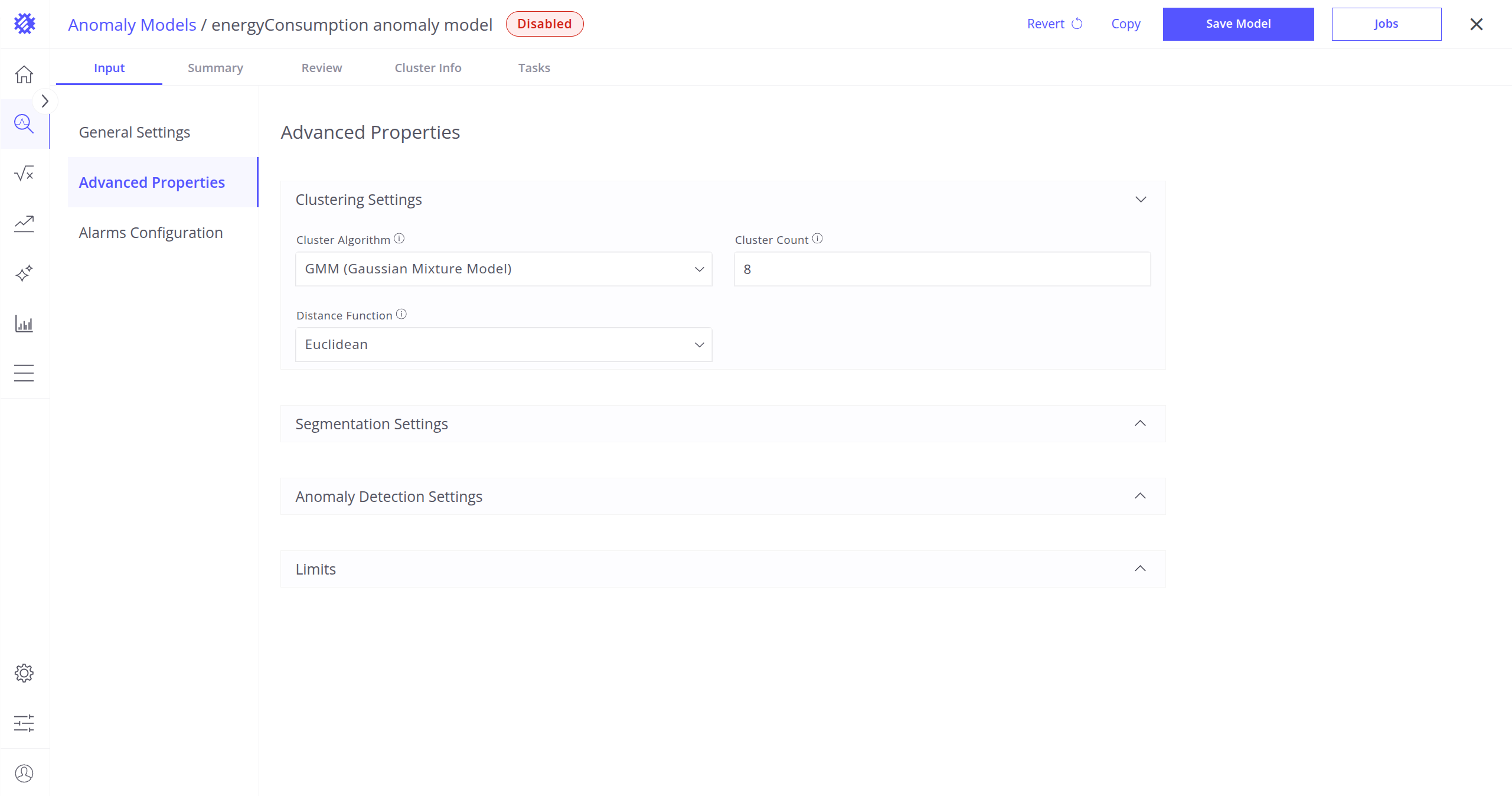
GMM (Gaussian Mixture Model): Models data as a mix of several normal distributions. Anomalies are points with low probability.
Use when: You need flexible clustering and probabilistic results. Learn more about GMM.
-
-
Cluster Count: Number of clusters to create.
- Distance Function: How to measure similarity between telemetry time series.
- Dynamic Time Warping (DTW): Good for time series with similar shapes but different timing.
- Euclidean: Straight-line distance, simple and fast.
- Chebyshev: Focuses on the largest single difference.
- Manhattan: Adds up all absolute differences.
- Canberra: Highlights small values and sparsity.
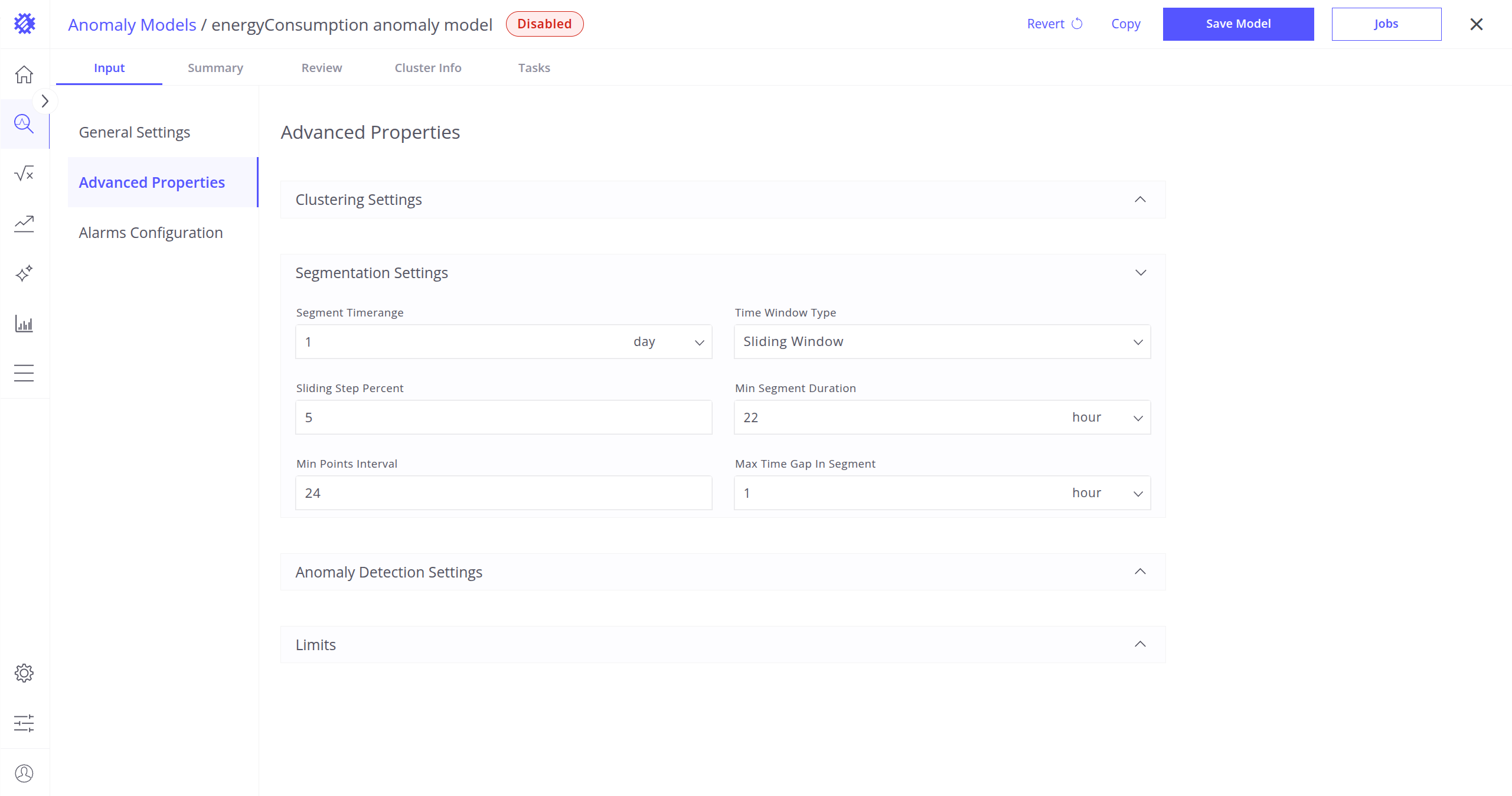
分段设置
将遥测拆分为更小、可管理的时间窗口,有助于更准确地分析行为。
-
分段时间范围:每个数据分段的时间长度(如 6 小时、1 天)。
- 时间窗口类型:分段在时间上的构建方式:
- 固定范围:不重叠的分段。
- 滑动窗口:以固定步长向前滑动的重叠分段。
-
滑动步长百分比:仅对滑动窗口生效,表示重叠分段的步长占比。
- 分段内最大时间间隔:同一分段内数据点之间允许的最大时间间隔。
- 最小分段时长:分段被视为有效的最短时间。
- 分段内最小点数:有效分段所需的最少数据点数。
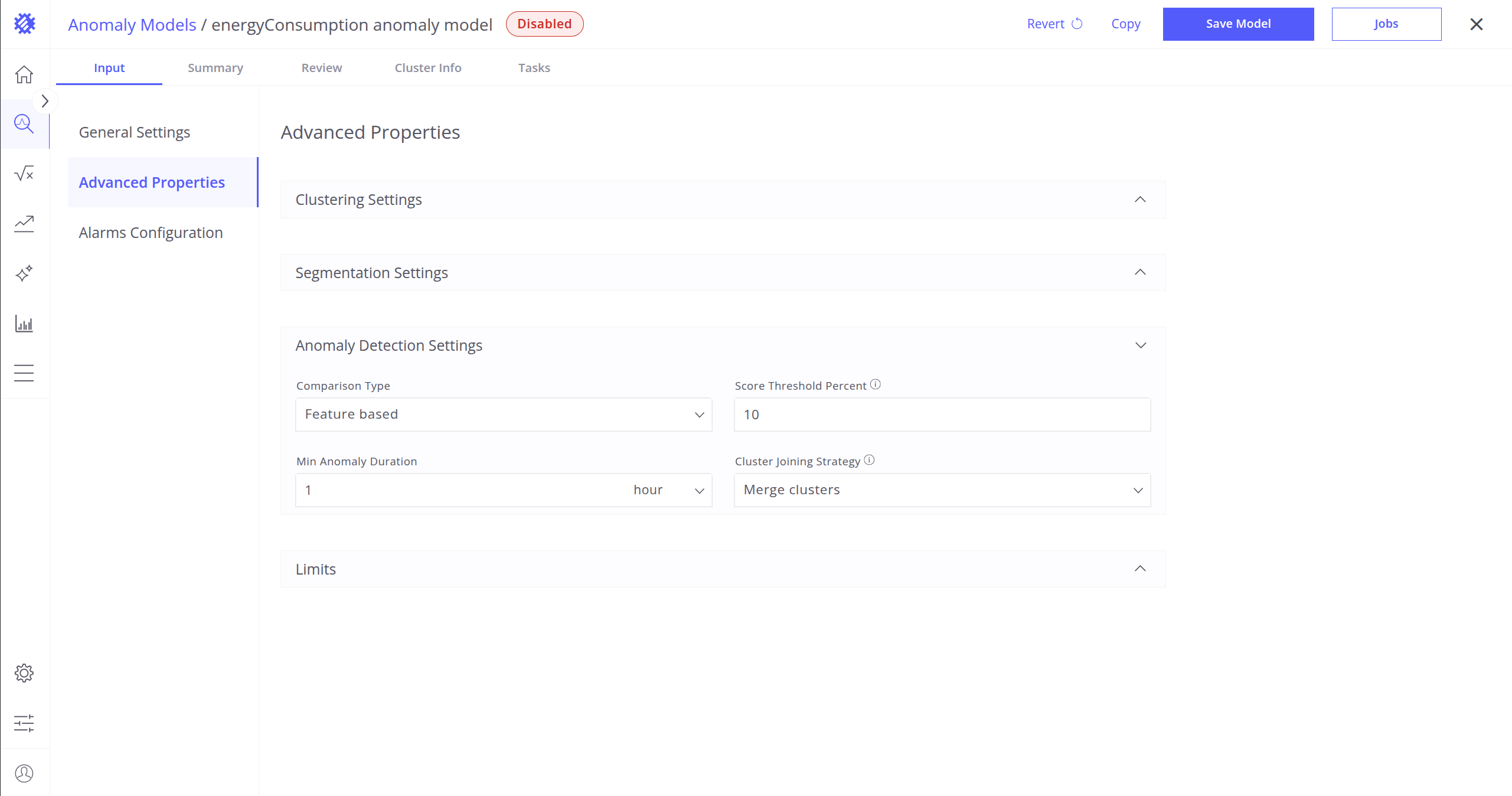
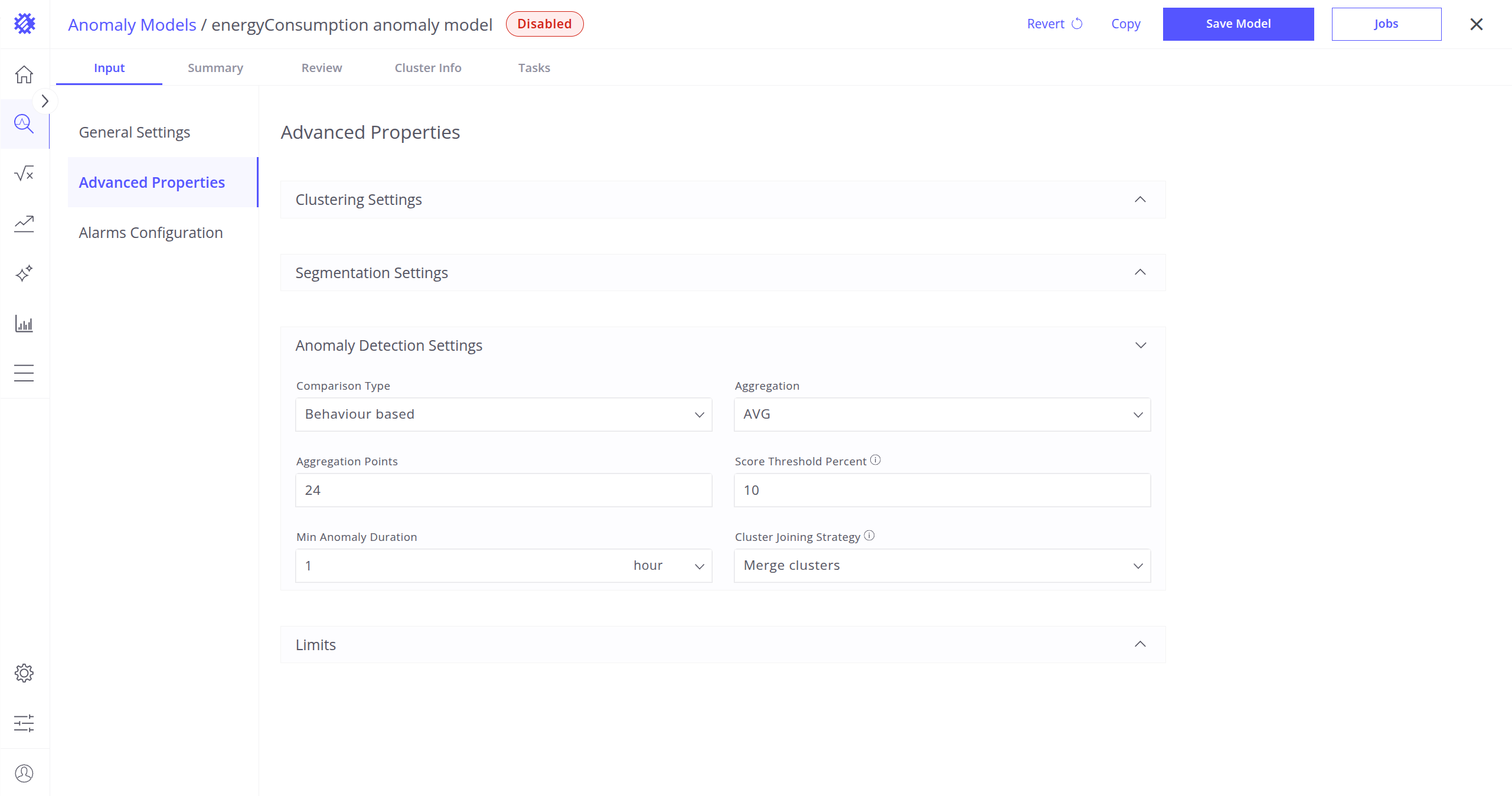
异常检测设置
在数据分段后,提取有助于模型理解行为并逐段检测异常的特征:
- 比较类型:定义分段之间的比较方式。
- 基于行为:刻画数据中的整体模式与趋势。
附加参数:Aggregation(段内聚合函数:AVG、MIN、MAX、SUM、COUNT);Aggregation Points(聚合前每段划分成的点数)。 - 基于特征:关注从数据得到的特定度量或属性。
- 基于行为:刻画数据中的整体模式与趋势。
-
分数阈值百分比:用于判断分段是否异常的百分位阈值,得分高于该阈值的分段将被标记为异常。
示例:设为 15% 时,得分最高的 15% 分段将被视为异常。 - 最小异常时长:事件被认定为真实异常的最短持续时间。
- 簇合并策略:允许系统将相邻分段中的异常(即使属于不同簇)视为一条连续异常。
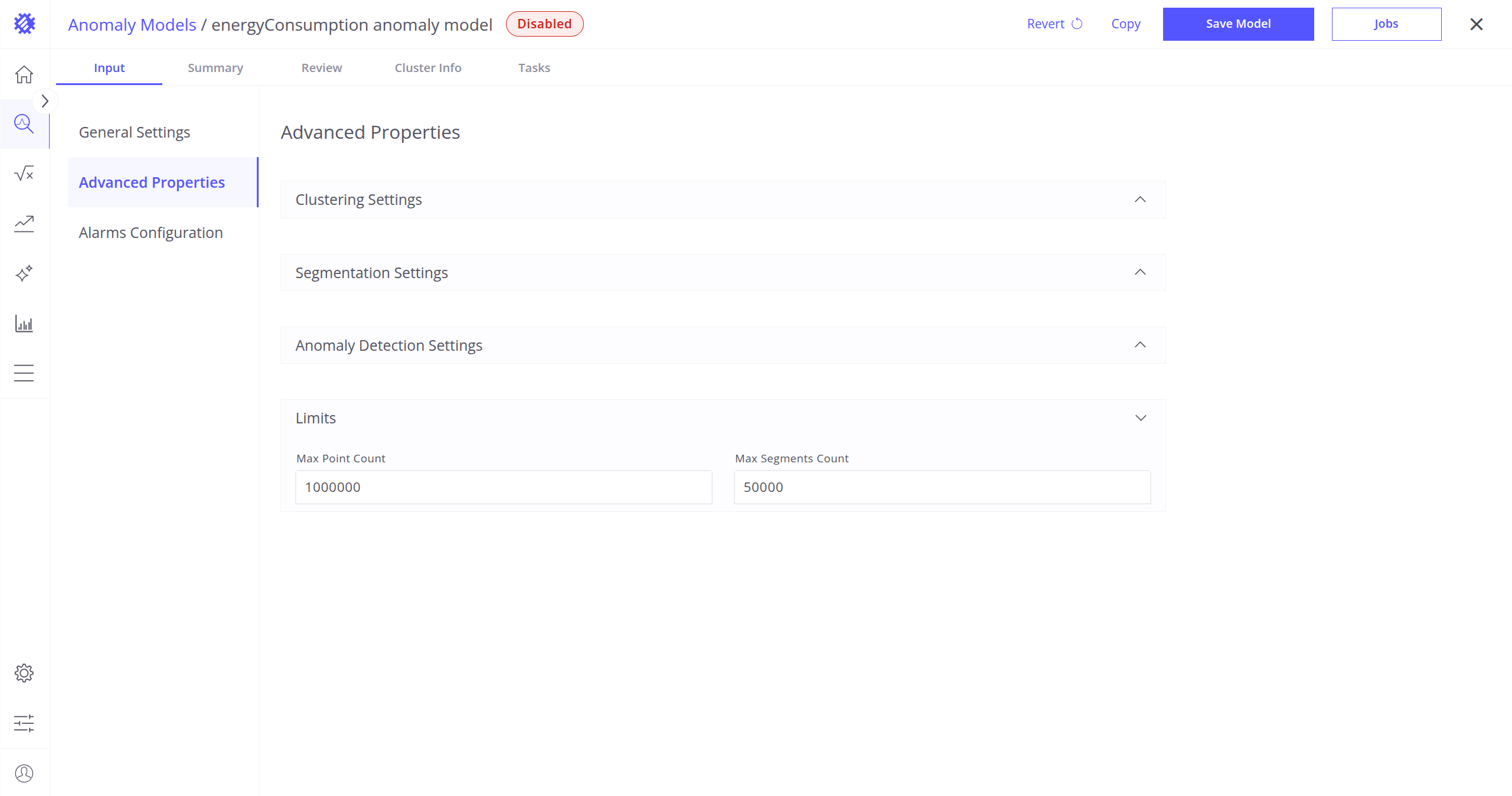
限制
- 最大点数:用于训练与检测的最大数据点数。
- 最大分段数:处理过程中系统可处理的最大分段数。
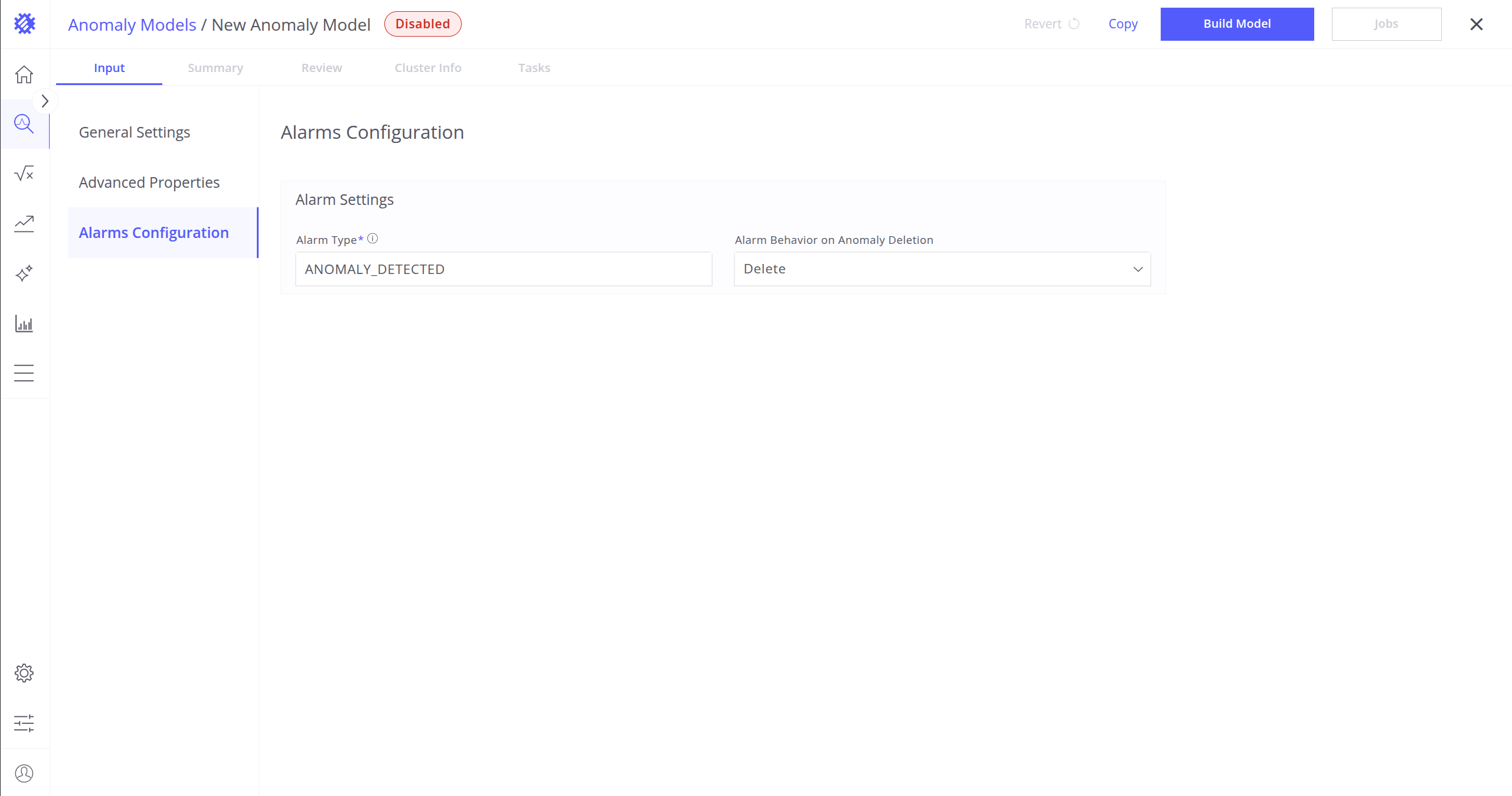
告警配置
-
告警类型:配置为检测到的异常创建的告警类型/分类,便于在ThingsBoard中区分告警。
-
异常删除时的告警行为:定义异常被删除时告警的处理方式。
-
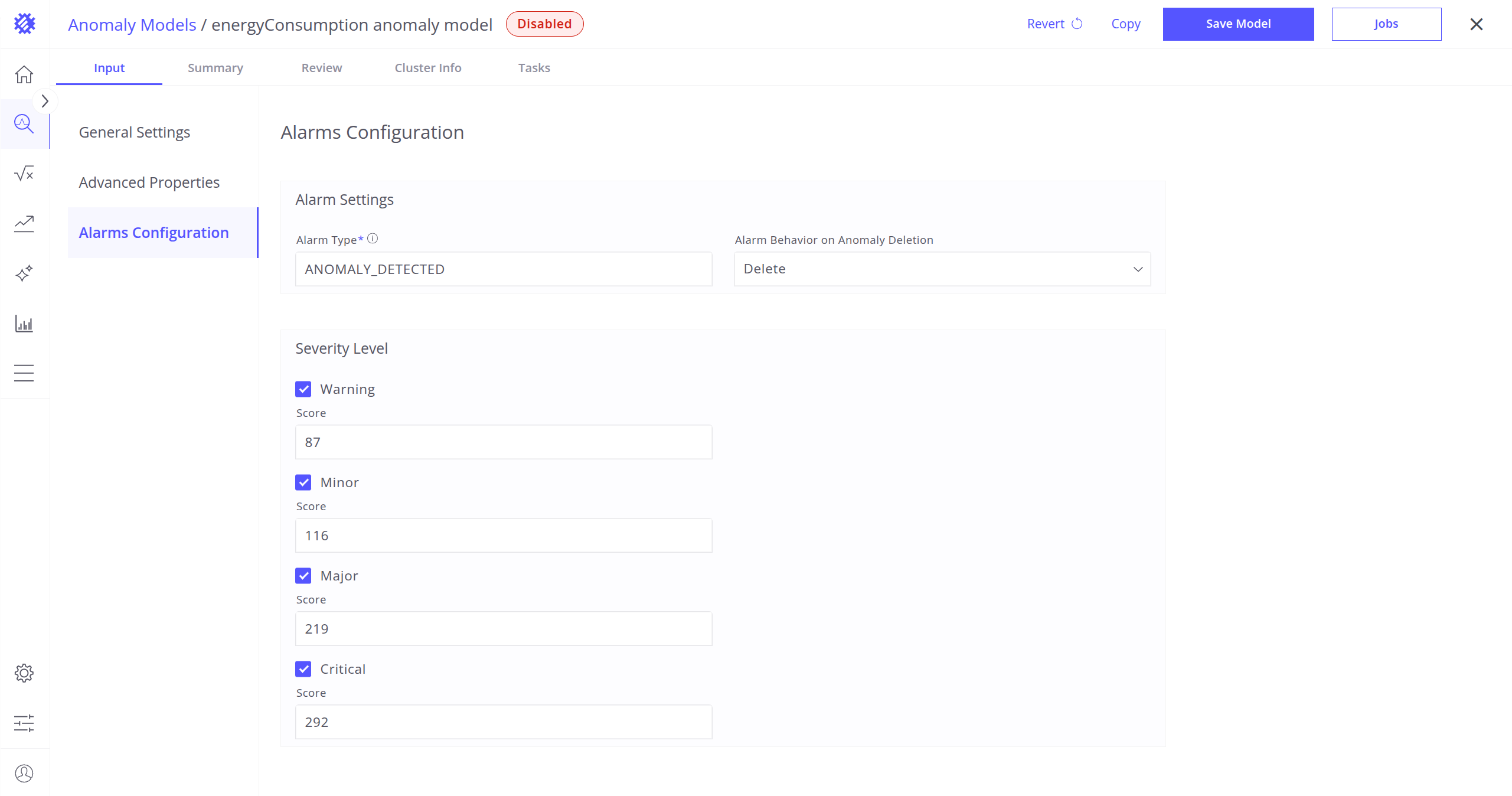
严重程度:首次构建模型后可用,用于配置各告警严重程度(如 Critical、Major、Minor)的阈值。Trendz 会根据异常分数分布自动生成默认阈值。
最佳实践
-
选择有代表性的训练数据:使用最能代表正常行为的数据进行训练,以提高检测准确率并减少误报。
-
合理设置分段:分段时间长度与滑动步长应与业务自然周期或预期异常持续时间相匹配。
-
按数据特性选择聚类方法:根据数据形态与噪声水平选择算法(如噪声大时用 DBSCAN,簇较分离时用 K-Means)。
-
按业务需求调整告警阈值:严重程度阈值应体现运维优先级与对告警的容忍度。
-
确认模型可靠后再启用告警:仅在验证模型能稳定检测真实异常后再开启告警创建,避免告警疲劳。
-
关注告警量以防告警风暴:留意告警数量与频率,避免对人员或系统造成过载。
-
用历史数据做重新处理测试:在启用刷新前,用重新处理任务在历史数据上验证模型效果并微调参数。
下一步
-
快速入门指南 - 快速了解 Trendz 主要功能。
-
安装指南 - 学习在各种操作系统上部署 Trendz。
-
指标探索器 - 学习使用 Trendz Metric Explorer 探索和创建指标。
-
字段计算 - 了解字段计算及使用方法。
-
状态 - 学习基于原始遥测定义和分析资产状态。
-
预测 - 学习进行预测及遥测行为预测。
-
筛选器 - 学习在分析中筛选数据集。
-
可用可视化部件 - 了解 Trendz 中可用的可视化部件及配置方法。
-
分享与嵌入可视化 - 学习将 Trendz 可视化添加到 ThingsBoard 仪表盘或第三方网页。
-
AI 助手 - 学习使用 Trendz AI 功能。