ThingsBoard规则引擎支持对传入遥测数据进行基本分析,例如阈值越界。 规则引擎的设计理念是根据设备属性或数据本身,将IoT设备的数据路由到不同的插件。 然而,多数实战场景还需要高级分析支持:机器学习、预测分析等。
本教程将演示如何:
- 使用内置规则引擎能力将遥测设备数据从ThingsBoard路由到Kafka topic(适用于ThingsBoard CE和PE)。
- 使用简单的Kafka Streams应用聚合多设备数据。
- 通过ThingsBoard PE Kafka Integration将分析结果推送回ThingsBoard进行持久化和可视化。
本教程中的分析虽然较为简单,但目的是突出集成步骤。

假设我们拥有大量光伏板,每块板包含多个光伏组件。 ThingsBoard用于收集、存储和可视化每块板中各光伏组件的异常遥测。
我们通过将单个光伏组件的产出值与同板所有组件的平均值及该值的标准偏差进行比较来计算异常。
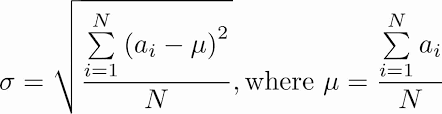
我们将使用30秒窗口(可配置)的Kafka Streams任务分析多设备的实时数据。
为存储和可视化分析结果,我们将为每块光伏板创建三个虚拟光伏组件设备。
前置条件
以下服务必须处于运行状态:
步骤1. 规则链配置
本步骤将配置三个generator节点,用于在开发期间生成模拟测试数据。 生产环境通常不需要它们,但对调试非常有用。我们将为3个组件和1块板生成数据。 其中两个组件产生相同值,一个组件产生较低值以模拟组件劣化。 当然,您应使用真实设备生成的真实数据来替换这些。此处仅为示例。
创建三个类型为”solar-module”的设备。若使用ThingsBoard PE,可将它们放入新的”Solar Modules”分组。
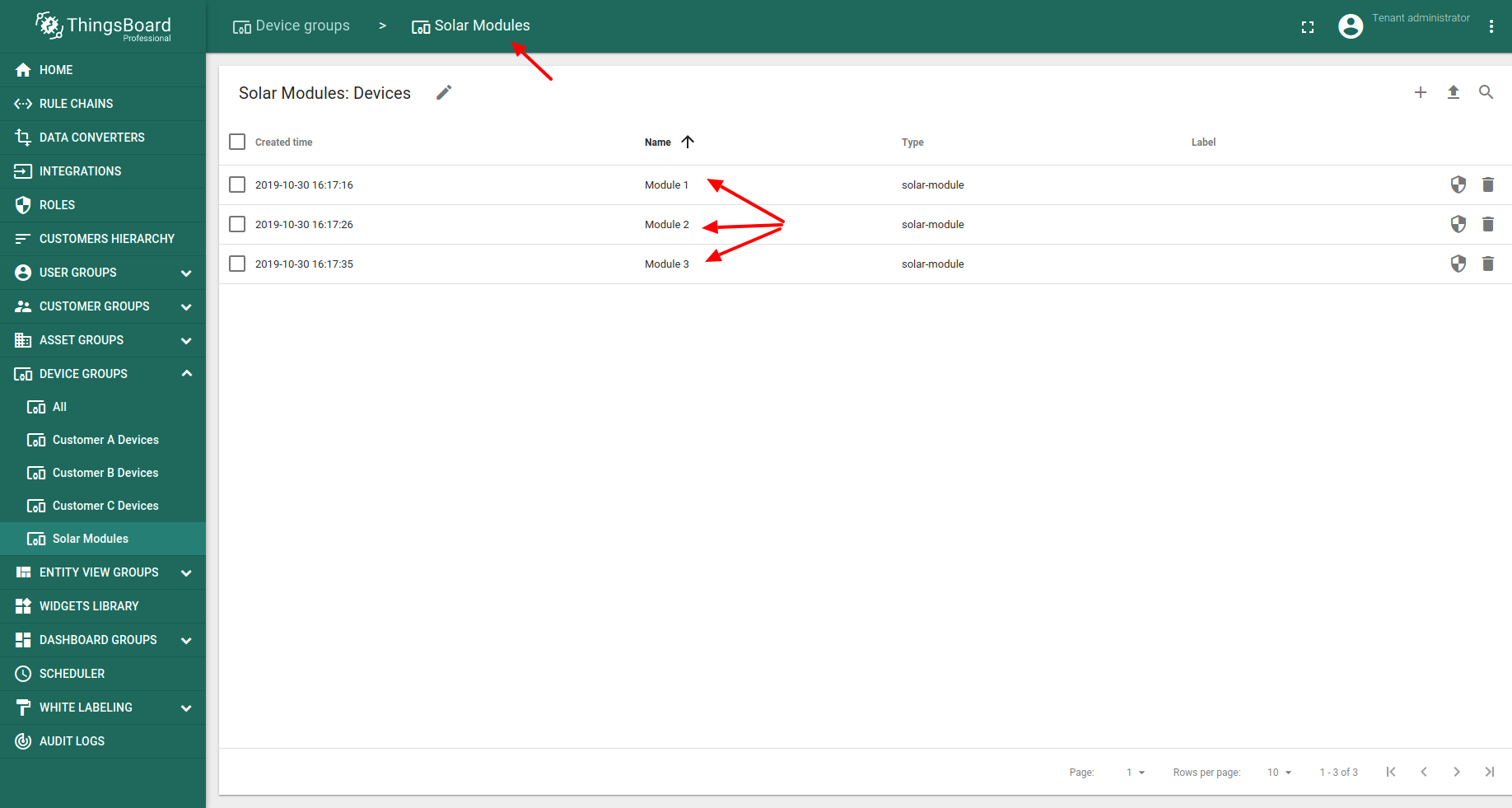
现在创建三个设备模拟器,将数据直接推送到本地Kafka broker。 模拟数据将推送到负责将数据写入Kafka topic的Kafka Rule Node。 先配置Kafka Rule Node。使用本地Kafka服务器(localhost:9092)和topic”solar-module-raw”。
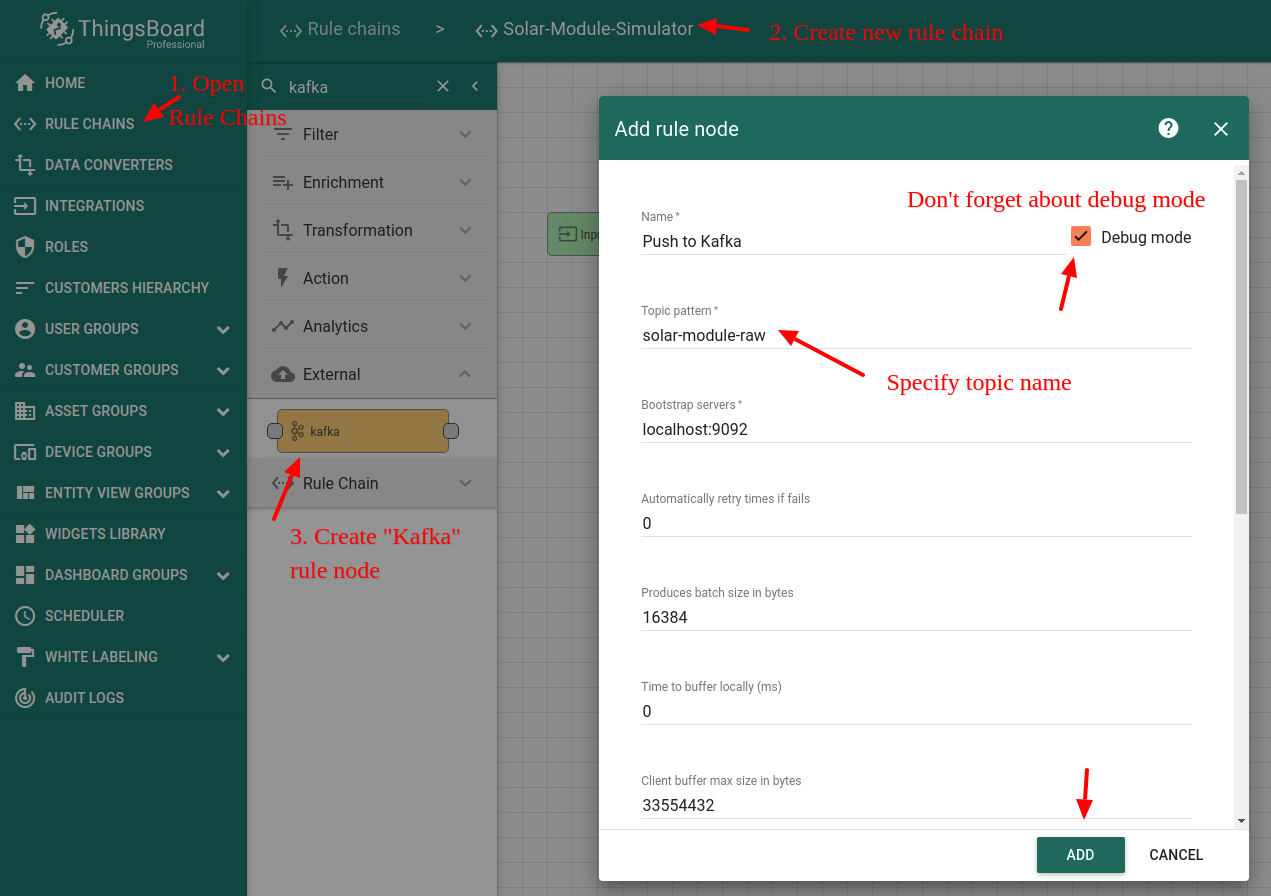
为第一个组件添加”generator”节点。将该generator配置为持续产生5瓦。
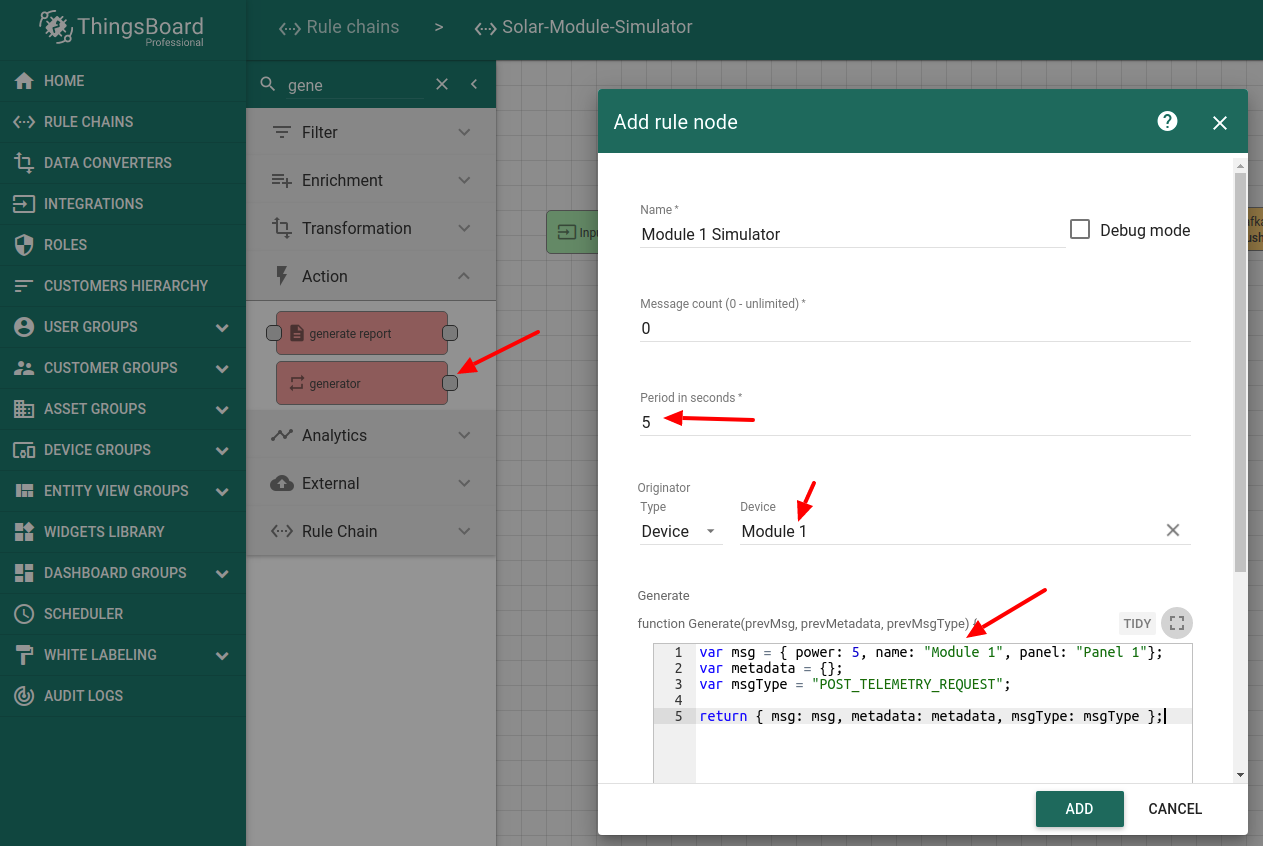
为第二个组件添加”generator”节点,同样配置为持续产生5瓦。
为第三个组件添加”generator”节点,配置为持续产生3.5瓦,以模拟组件劣化。
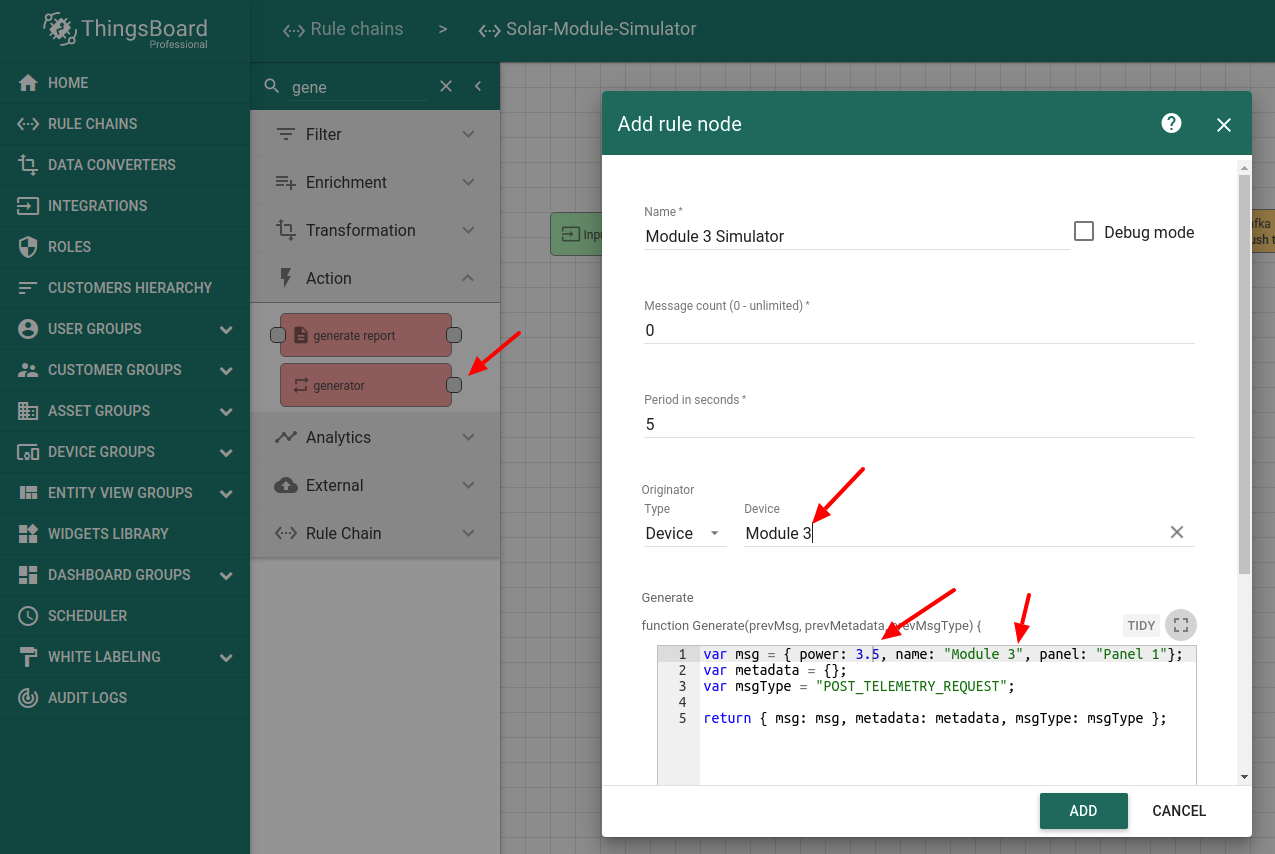
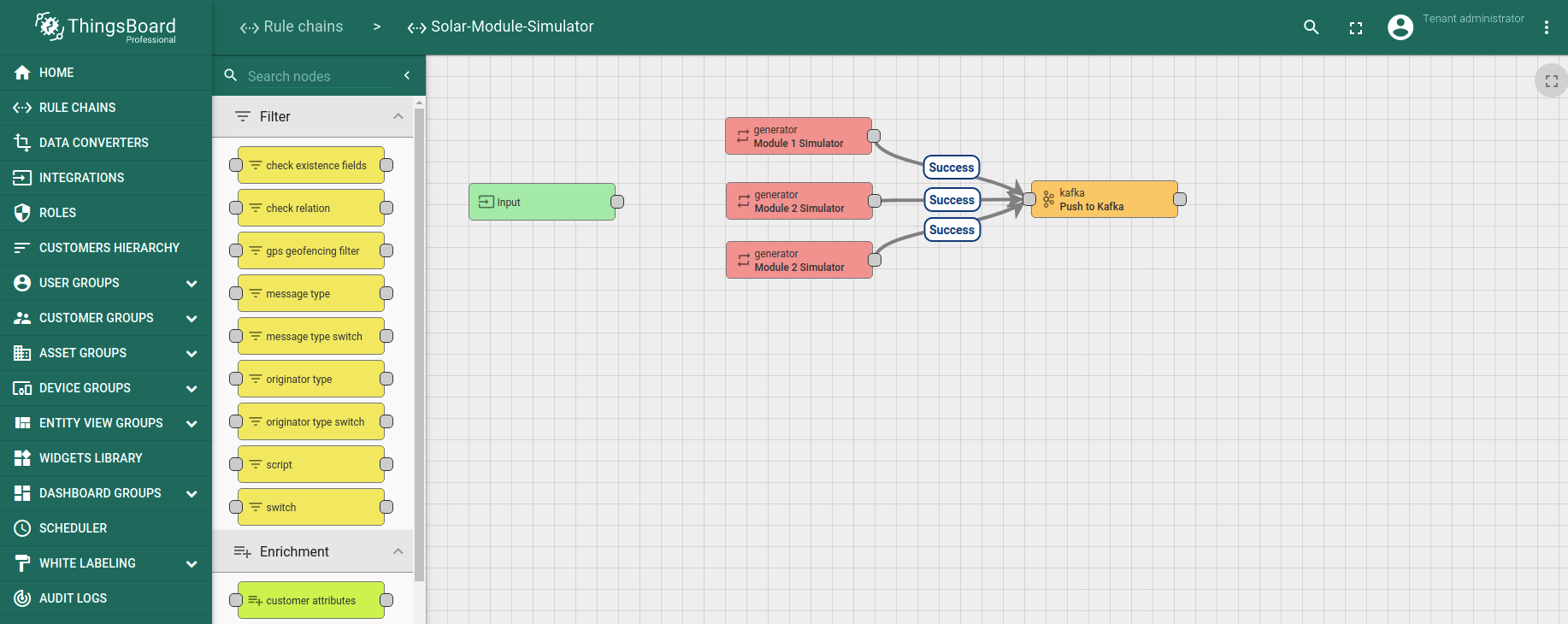
结果规则链应类似如下:
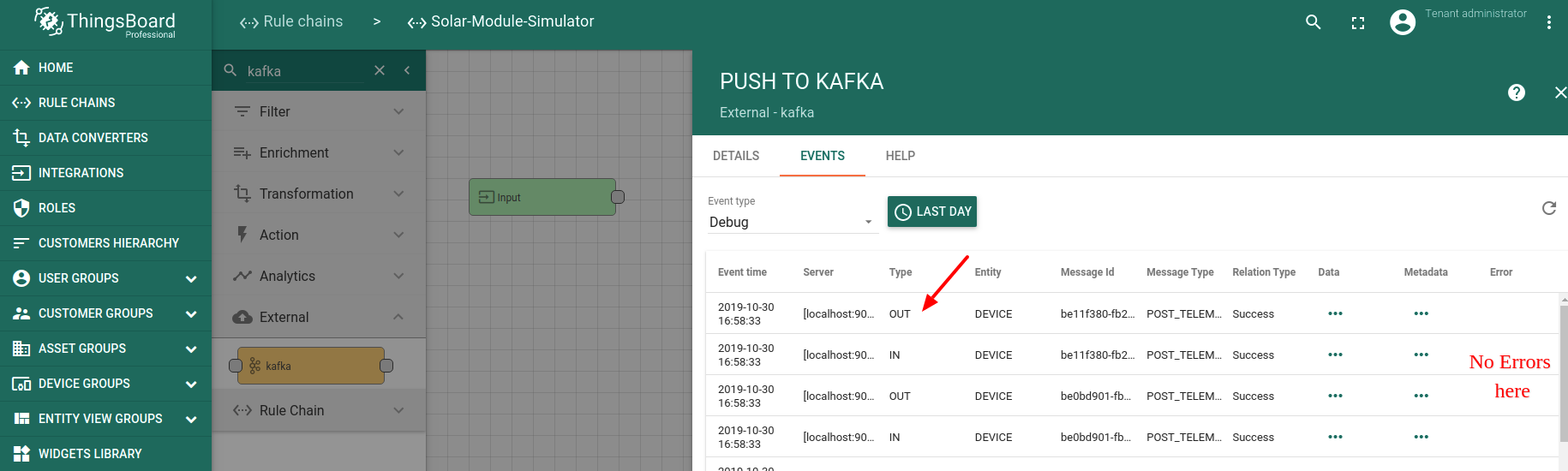
导入规则链后,请检查Kafka节点的调试输出。若Kafka在localhost正常运行,您应看到类似的调试消息。 注意调试日志中无错误:
步骤2. 启动Kafka Streams应用
本步骤将下载并启动示例应用,该应用分析”solar-module-raw”的原始数据并输出关于组件劣化的有价值洞察。 示例应用计算时间窗口(可配置)内每块板中各组件的总产能。 然后计算每块板各组件的平均功率及其在同一时间窗口内的偏差。 完成后,应用将各组件的值与平均值比较,若差值大于偏差,则视为异常。
异常计算结果推送到”anomalies-topic”。 ThingsBoard通过Kafka Integration订阅该topic,生成告警并将异常持久化到数据库。
下载示例应用
可从ThingsBoard仓库获取代码,并用Maven构建项目:
1
mvn clean install
将该Maven项目添加到您常用的IDE中。
依赖说明
项目使用的主要依赖:
1
2
3
4
5
6
7
8
9
<dependencies>
...
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
...
</dependencies>
源码说明
KafkaStreams应用逻辑主要集中于SolarConsumer类。
1
2
3
4
5
6
7
8
9
10
private static Properties getProperties() {
final Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
return props;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
private static final String IN_TOPIC = "solar-module-raw";
private static final TopicNameExtractor<String, SolarModuleAggregatorJoiner> OUT_TOPIC =
new StaticTopicNameExtractor<>("solar-module-anomalies");
// Time for windowing
private static final Duration DURATION = Duration.ofSeconds(30);
private static final TimeWindows TIME_WINDOWS = TimeWindows.of(DURATION);
private static final JoinWindows JOIN_WINDOWS = JoinWindows.of(DURATION);
private static final StreamsBuilder builder = new StreamsBuilder();
// serde - Serializer/Deserializer
// for custom classes should be custom Serializer/Deserializer
private static final Serde<SolarModuleData> SOLAR_MODULE_DATA_SERDE =
Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleData.class));
private static final Serde<SolarModuleAggregator> SOLAR_MODULE_AGGREGATOR_SERDE =
Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleAggregator.class));
private static final Serde<SolarPanelAggregator> SOLAR_PANEL_AGGREGATOR_SERDE =
Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarPanelAggregator.class));
private static final Serde<SolarModuleKey> SOLAR_MODULE_KEY_SERDE =
Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleKey.class));
private static final Serde<SolarPanelAggregatorJoiner> SOLAR_PANEL_AGGREGATOR_JOINER_SERDE =
Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarPanelAggregatorJoiner.class));
private static final Serde<SolarModuleAggregatorJoiner> SOLAR_MODULE_AGGREGATOR_JOINER_SERDE =
Serdes.serdeFrom(new JsonPojoSerializer<>(), new JsonPojoDeserializer<>(SolarModuleAggregatorJoiner.class));
private static final Serde<String> STRING_SERDE = Serdes.String();
private static final Serde<Windowed<String>> WINDOWED_STRING_SERDE = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TIME_WINDOWS.size()));
// 1 - sigma
private static final double Z = 1;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
// source stream from kafka
final KStream<SolarModuleKey, SolarModuleData> source =
builder
.stream(IN_TOPIC, Consumed.with(STRING_SERDE, SOLAR_MODULE_DATA_SERDE))
.map((k, v) -> KeyValue.pair(new SolarModuleKey(v.getPanel(), v.getName()), v));
// calculating sum power and average power for modules
final KStream<Windowed<SolarModuleKey>, SolarModuleAggregator> aggPowerPerSolarModuleStream =
source
.groupByKey(Grouped.with(SOLAR_MODULE_KEY_SERDE, SOLAR_MODULE_DATA_SERDE))
.windowedBy(TIME_WINDOWS)
.aggregate(SolarModuleAggregator::new,
(modelKey, value, aggregation) -> aggregation.updateFrom(value),
Materialized.with(SOLAR_MODULE_KEY_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE))
.suppress(Suppressed.untilTimeLimit(DURATION, Suppressed.BufferConfig.unbounded()))
.toStream();
// calculating sum power and average power for panels
final KStream<Windowed<String>, SolarPanelAggregator> aggPowerPerSolarPanelStream =
aggPowerPerSolarModuleStream
.map((k, v) -> KeyValue.pair(new Windowed<>(k.key().getPanelName(), k.window()), v))
.groupByKey(Grouped.with(WINDOWED_STRING_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE))
.aggregate(SolarPanelAggregator::new,
(panelKey, value, aggregation) -> aggregation.updateFrom(value),
Materialized.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE))
.suppress(Suppressed.untilTimeLimit(DURATION, Suppressed.BufferConfig.unbounded()))
.toStream();
// if used for join more than once, the exception "TopologyException: Invalid topology:" will be thrown
final KStream<Windowed<String>, SolarModuleAggregator> aggPowerPerSolarModuleForJoinStream =
aggPowerPerSolarModuleStream
.map((k, v) -> KeyValue.pair(new Windowed<>(k.key().getPanelName(), k.window()), v));
// joining aggregated panels with aggregated modules
// need for calculating sumSquare and deviance
final KStream<Windowed<String>, SolarPanelAggregatorJoiner> joinedAggPanelWithAggModule =
aggPowerPerSolarPanelStream
.join(
aggPowerPerSolarModuleForJoinStream,
SolarPanelAggregatorJoiner::new, JOIN_WINDOWS,
Joined.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE));
//calculating sumSquare and deviance
final KStream<Windowed<String>, SolarPanelAggregator> aggPowerPerSolarPanelFinalStream =
joinedAggPanelWithAggModule
.groupByKey(Grouped.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_JOINER_SERDE))
.aggregate(SolarPanelAggregator::new,
(key, value, aggregation) -> aggregation.updateFrom(value),
Materialized.with(WINDOWED_STRING_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE))
.suppress(Suppressed.untilTimeLimit(DURATION, Suppressed.BufferConfig.unbounded()))
.toStream();
// joining aggregated modules with aggregated panels in which calculated sumSquare and deviance
// need for check modules with anomaly power value
final KStream<Windowed<String>, SolarModuleAggregatorJoiner> joinedAggModuleWithAggPanel =
aggPowerPerSolarModuleStream
.map((k, v) -> KeyValue.pair(new Windowed<>(k.key().getPanelName(), k.window()), v))
.join(
aggPowerPerSolarPanelFinalStream,
SolarModuleAggregatorJoiner::new, JOIN_WINDOWS,
Joined.with(WINDOWED_STRING_SERDE, SOLAR_MODULE_AGGREGATOR_SERDE, SOLAR_PANEL_AGGREGATOR_SERDE));
// streaming result data (modules with anomaly power value)
joinedAggModuleWithAggPanel
.filter((k, v) -> isAnomalyModule(v))
.map((k, v) -> KeyValue.pair(k.key(), v))
.to(OUT_TOPIC, Produced.valueSerde(SOLAR_MODULE_AGGREGATOR_JOINER_SERDE));
// starting streams
final KafkaStreams streams = new KafkaStreams(builder.build(), getProperties());
streams.cleanUp();
streams.start();
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
计算异常数据

1
2
3
4
private static boolean isAnomalyModule(SolarModuleAggregatorJoiner module) {
double currentZ = Math.abs(module.getSumPower() - module.getSolarPanelAggregator().getAvgPower()) / module.getSolarPanelAggregator().getDeviance();
return currentZ > Z;
}
示例应用输出
1
2
3
4
5
6
...SolarConsumer - PerSolarModule: [1572447720|Panel 1|Module 1]: 30.0:6
...SolarConsumer - PerSolarModule: [1572447720|Panel 1|Module 2]: 30.0:6
...SolarConsumer - PerSolarModule: [1572447720|Panel 1|Module 3]: 21.0:6
...SolarConsumer - PerSolarPanel: [1572447690|Panel 1]: 81.0:3
...SolarConsumer - PerSolarPanelFinal: [1572447660|Panel 1]: power:81.0 count:3 squareSum:54.0 variance:18.0 deviance:4.2
...SolarConsumer - ANOMALY module: [1572447660|Panel 1|Module 3]: sumPower:21.0 panelAvg:27.0 deviance:4.2
步骤3. 配置Kafka Integration
将ThingsBoard配置为订阅”solar-module-anomalies”topic并创建告警。我们将使用自ThingsBoard v2.4.2起可用的Kafka Integration。
配置Uplink转换器
在设置Kafka integration前,需创建Uplink数据转换器。Uplink数据转换器负责解析传入的异常数据。
由KafkaStreams应用产生的传入消息示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"moduleName": "Module 3",
"panelName": "Panel 1",
"count": 6,
"sumPower": 21.0,
"avgPower": 3.5,
"solarPanelAggregator": {
"panelName": "Panel 1",
"count": 3,
"sumPower": 81.0,
"avgPower": 27.0,
"squaresSum": 54.0,
"variance": 18.0,
"deviance": 4.2
}
}
以下脚本粘贴到Decoder函数区域:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
// Decode an uplink message from a buffer
// payload - array of bytes
// metadata - key/value object
/** Decoder **/
// decode payload to string
var msg = decodeToJson(payload);
// decode payload to JSON
// var data = decodeToJson(payload);
var deviceName = msg.moduleName;
var deviceType = 'module';
// Result object with device attributes/telemetry data
var result = {
deviceName: deviceName,
deviceType: deviceType,
attributes: {
panel: msg.panelName
},
telemetry: {
avgPower: msg.avgPower,
sumPower: msg.sumPower,
avgPowerFromPanel: msg.solarPanelAggregator.avgPower,
deviance: msg.solarPanelAggregator.deviance
}
};
/** Helper functions **/
function decodeToString(payload) {
return String.fromCharCode.apply(String, payload);
}
function decodeToJson(payload) {
// covert payload to string.
var str = decodeToString(payload);
// parse string to JSON
var data = JSON.parse(str);
return data;
}
return result;
decoder函数的作用是将传入数据和元数据解析为ThingsBoard可使用的格式。 deviceName和deviceType为必填,attributes和telemetry为可选。 attributes和telemetry为扁平键值对象,不支持嵌套对象。
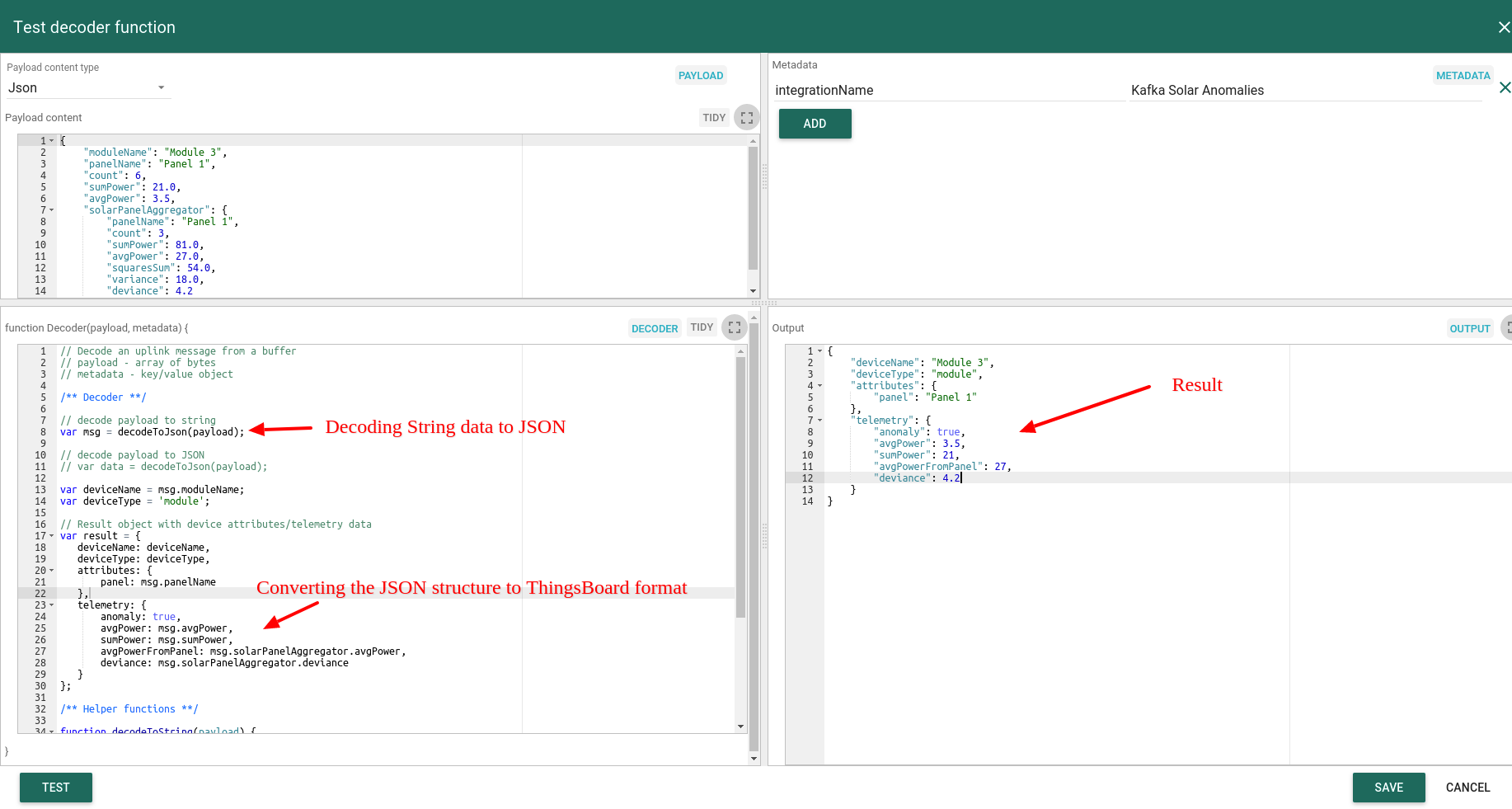
配置Kafka Integration
创建Kafka integration,订阅”solar-module-anomalies”topic。
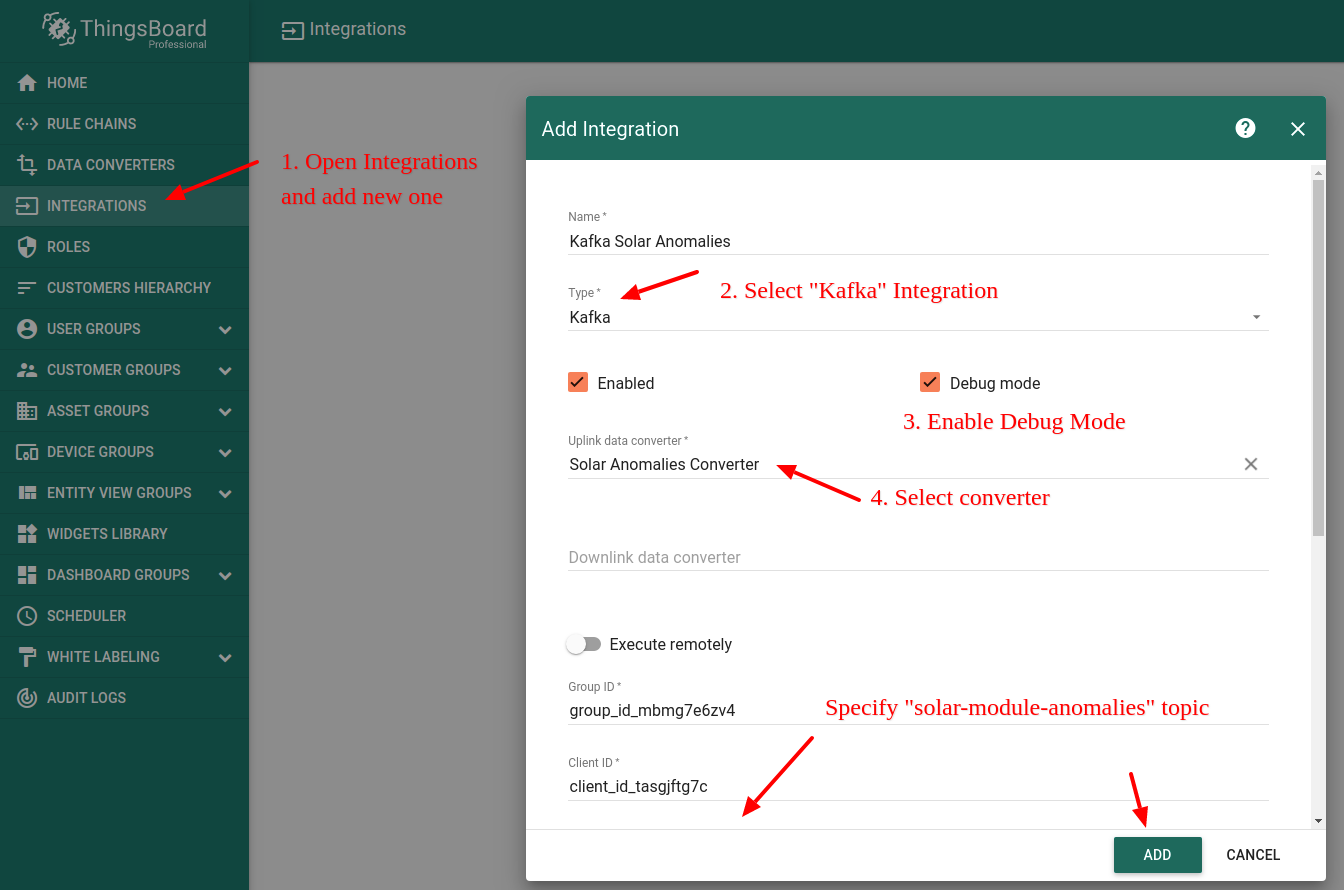
步骤4. 配置规则引擎以创建告警
按照现有的“创建和清除告警”指南,根据传入遥测中的”anomaly”布尔标志创建告警,并参考“告警时发送邮件”指南发送邮件通知。 探索其他指南以了解更多。
步骤5. 关闭调试消息日志
尽管Debug模式在开发和故障排查时非常有用,但将其在生产环境中保持启用会显著增加数据库占用的磁盘空间,因为所有调试数据都会存储其中。 强烈建议在完成调试后关闭Debug模式。