ThingsBoard开源物联网平台的核心功能之一是数据采集,该功能在高负载下必须稳定可靠。 本文将介绍我们为确保单台ThingsBoard服务器能持续处理20,000+台设备和30,000+条/秒MQTT发布消息所做的优化步骤, 合计约每分钟200万条消息。
架构
ThingsBoard的高性能依赖于以下核心项目:
- Netty:面向物联网设备的高性能MQTT服务器/代理。
- Cassandra:可扩展的高性能NoSQL数据库,用于存储设备时序数据。
- Actor系统:在数百万设备之间实现高性能消息协调。
- Kafka(或RabbitMQ、AWS SQS、Azure Event Hub、Google PubSub):可扩展的消息队列。
集群模式下还使用Zookeeper进行协调,以及gRPC通信。详见平台架构。
数据流与测试工具
物联网设备通过MQTT连接ThingsBoard服务器,并发送携带JSON载荷的publish命令。 单条发布消息大小约100字节。 MQTT是一种轻量级发布/订阅消息协议,相比HTTP请求/响应协议具有诸多优势。

ThingsBoard服务器处理MQTT发布消息后,异步存储到Cassandra。 服务器还可将数据推送至Web UI仪表盘的WebSocket订阅(如存在)。 我们尽量避免任何阻塞操作,这对整体系统性能至关重要。 ThingsBoard支持MQTT QoS 1,即客户端只有在数据写入Cassandra后才会收到发布消息的确认回复。 QoS 1可能产生的重复数据只是覆盖Cassandra中对应行,因此持久化数据中不会出现重复。 该机制保障了数据投递与持久化的可靠性。
我们使用了同样基于Akka和Netty的Gatling负载测试框架。 Gatling仅需2核CPU的5-10%即可模拟10,000个MQTT客户端。 关于我们如何改进非官方Gatling MQTT插件以适配测试场景,请参阅专题文章。
性能优化步骤
第1步:Cassandra驱动异步API
首次在配备SSD的现代4核笔记本上进行性能测试时,结果相当不理想——平台每秒仅能处理200条消息。 根本原因和主要性能瓶颈非常明显且容易定位。 经排查发现处理流程并非100%异步,我们在遥测服务Actor中执行了Cassandra驱动的阻塞API调用。 对服务实现进行快速重构后,性能提升超过10倍,1,000台设备可达到约2,500条/秒的发布消息处理能力。
第2步:连接池优化
为便于共享测试结果和复现流程,我们决定迁移到AWS EC2实例。首先在c4.xlarge实例(4 vCPU、7.5GB内存)上运行测试,Cassandra与ThingsBoard部署在同一机器上。

测试配置:
- 设备数量:10,000
- 每台设备发布频率:每秒一次
- 总负载:10,000条消息/秒
首次测试结果明显不可接受:

上述极高的响应时间是因为服务器根本无法处理每秒10,000条消息,导致消息不断排队。
我们首先通过监控测试实例的内存和CPU负载展开排查。 最初猜测性能不佳是由于CPU或内存负载过高。 但实际上,压测期间我们发现CPU在某些时刻会空闲数秒。 这种”暂停”现象每3-7秒发生一次,见下图。
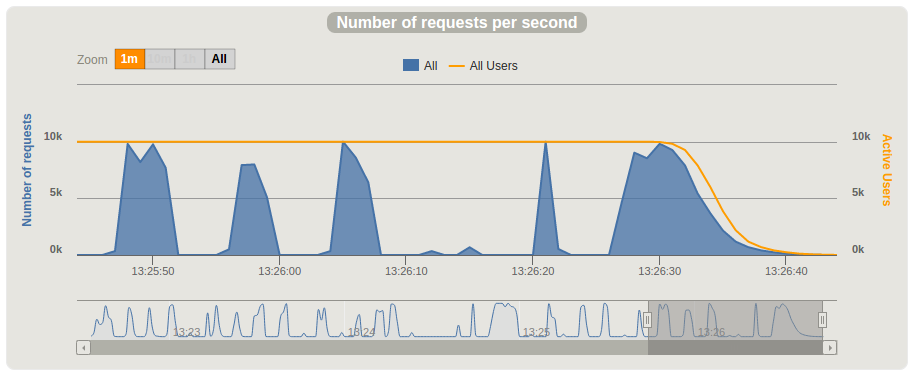
下一步,我们决定在这些暂停期间做线程转储。 我们预期能看到被阻塞的线程,从而找到暂停期间发生了什么的线索。 因此我们打开一个控制台监控CPU负载,另一个在压测过程中执行线程转储,使用以下命令:
1
2
3
kill -3 THINGSBOARD_PID
我们发现暂停期间始终有一个线程处于TIMED_WAITING状态,根本原因在于Cassandra驱动的awaitAvailableConnection方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
parking to wait for <0x0000000092d9d390> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2163)
at com.datastax.driver.core.HostConnectionPool.awaitAvailableConnection(HostConnectionPool.java:287)
at com.datastax.driver.core.HostConnectionPool.waitForConnection(HostConnectionPool.java:328)
at com.datastax.driver.core.HostConnectionPool.borrowConnection(HostConnectionPool.java:251)
at com.datastax.driver.core.RequestHandler$SpeculativeExecution.query(RequestHandler.java:301)
at com.datastax.driver.core.RequestHandler$SpeculativeExecution.sendRequest(RequestHandler.java:281)
at com.datastax.driver.core.RequestHandler.startNewExecution(RequestHandler.java:115)
at com.datastax.driver.core.RequestHandler.sendRequest(RequestHandler.java:91)
at com.datastax.driver.core.SessionManager.executeAsync(SessionManager.java:132)
at org.thingsboard.server.dao.AbstractDao.executeAsync(AbstractDao.java:91)
at org.thingsboard.server.dao.AbstractDao.executeAsyncWrite(AbstractDao.java:75)
at org.thingsboard.server.dao.timeseries.BaseTimeseriesDao.savePartition(BaseTimeseriesDao.java:135)
因此我们意识到,Cassandra驱动默认的连接池配置在我们的场景下导致了糟糕的结果。
连接池功能的官方配置文档包含一个特殊选项「单连接并发请求数」(Simultaneous requests per connection),允许调整单个连接上的并发请求数。 我们使用Cassandra驱动协议v3,其默认值为:
- LOCAL主机:1024
- REMOTE主机:256
考虑到我们实际需要从10,000台设备拉取数据,默认值显然不够。 因此我们修改了代码,将LOCAL和REMOTE主机的值设为最大值:
1
2
3
poolingOptions
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32768)
.setMaxRequestsPerConnection(HostDistance.REMOTE, 32768);
修改后的测试结果如下。

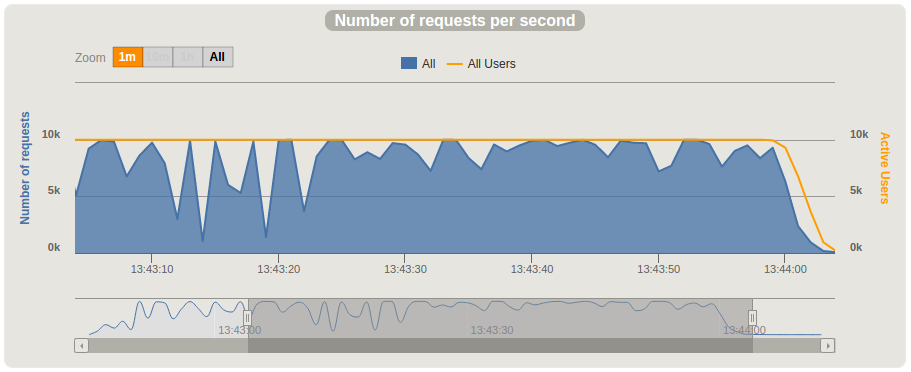
结果有了明显改善,但距离每分钟100万条消息仍有差距。在c4.xlarge上测试时不再出现CPU暂停现象。 整个测试期间CPU负载较高(80-95%)。我们做了多次线程转储以确认Cassandra驱动不再等待可用连接,确实未再出现该问题。
第3步:纵向扩展
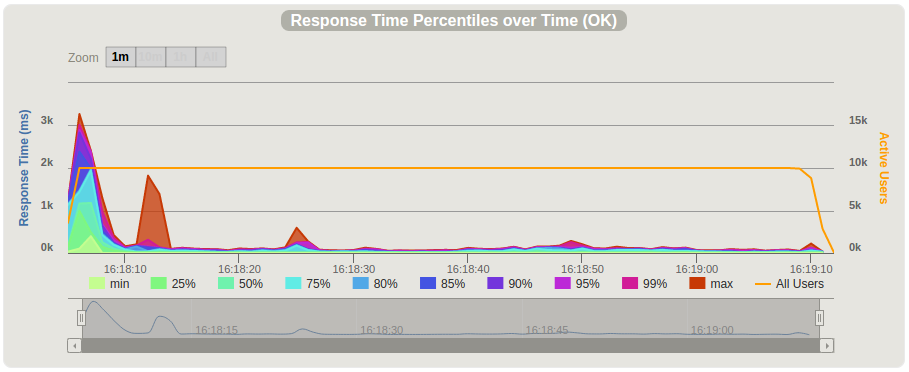
我们决定在性能翻倍的c4.2xlarge节点(8 vCPU、15GB内存)上运行相同测试。 性能提升并非线性,CPU仍处于高负载状态(80-90%)。

响应时间有了显著改善。测试开始时出现明显峰值后,最大响应时间保持在200ms以内,平均响应时间约50ms。
每秒请求数约10,000。
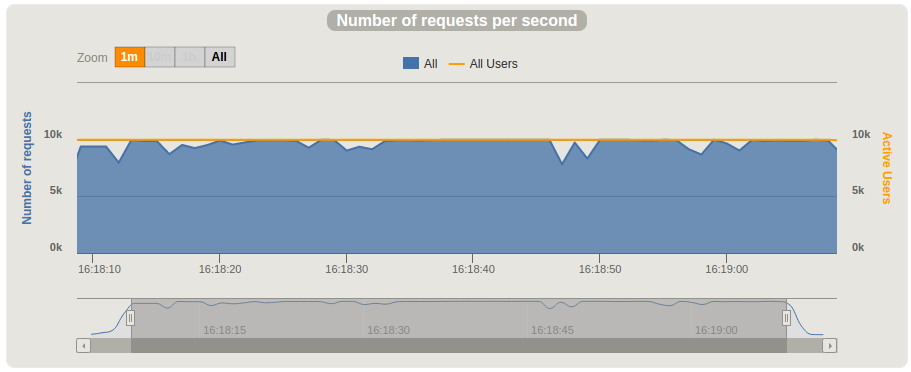
我们还在c4.4xlarge(16 vCPU、30GB内存)上执行了测试,但未观察到明显提升,因此决定将ThingsBoard服务器与Cassandra分离,并将Cassandra迁移至三节点集群。
第4步:水平扩展
我们的主要目标是确定单台运行在c4.2xlarge上的ThingsBoard服务器能处理多少MQTT消息。 ThingsBoard集群的水平扩展将在单独文章中介绍。 因此我们将Cassandra迁移到三台独立的c4.xlarge实例(默认配置), 并从两台独立的c4.xlarge实例同时启动Gatling压测工具, 以尽量减少第三方因素对延迟和吞吐量的影响。

测试配置:
- 设备数量:20,000
- 每台设备发布频率:每秒两次
- 总负载:40,000条消息/秒
从两台不同客户端机器同时发起的测试统计结果如下。

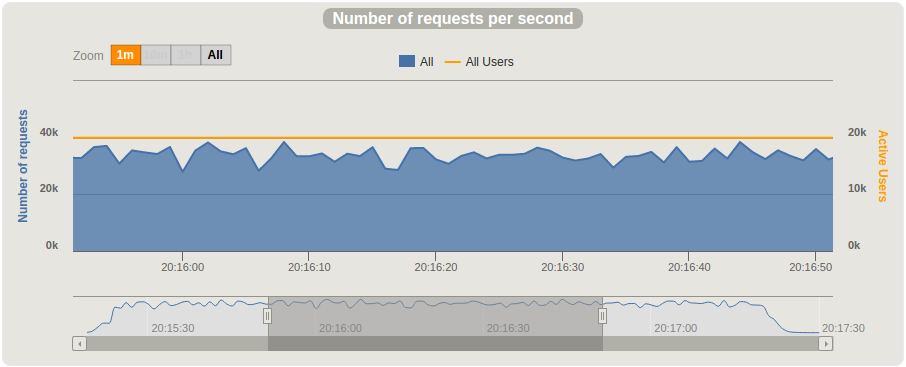
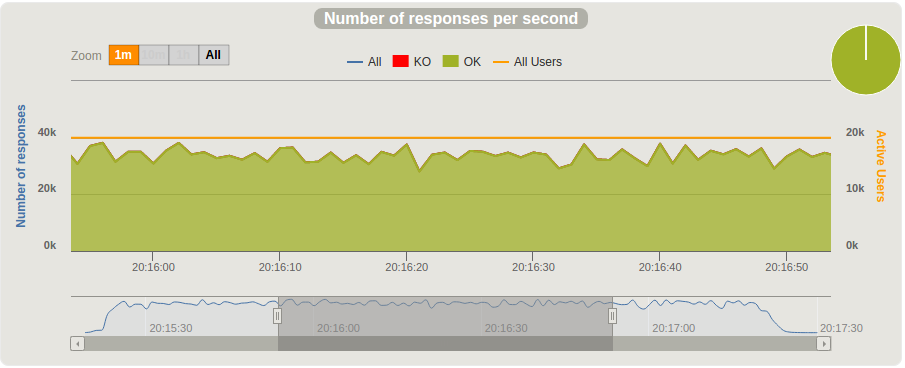
基于两次同时测试的数据,我们达到了每秒30,000条发布消息的吞吐量,即每分钟180万条。
如何复现测试
我们准备了多个AWS AMI,供有兴趣复现这些测试的人使用。详见文档页面中的详细说明。
总结
本次性能测试表明,一个成本约每小时1美元的小型ThingsBoard集群,即可轻松接收、存储和可视化设备发送的超过1亿条消息。 我们将继续致力于性能优化,并计划在后续博文中发布ThingsBoard集群的性能测试结果。 希望本文对正在评估平台并希望自行执行性能测试的用户有所帮助。 同时也希望这些性能优化步骤能为使用类似技术的工程师提供参考。