在TBMQ 1.x中,持久DEVICE客户端依赖PostgreSQL进行消息持久化和检索, 以确保客户端重连时仍能正确投递消息。 PostgreSQL在初期表现良好,但存在只能垂直扩展这一根本性限制。 我们预计,随着持久MQTT会话数量的增长,PostgreSQL架构最终将成为瓶颈。 为解决这一问题,我们开始探索更易扩展的替代方案,以应对MQTT Broker不断增长的业务需求。 考虑到Redis具备水平扩展能力、原生集群支持且应用广泛,我们很快将其确定为最佳方案。
PostgreSQL使用与限制
要充分理解这次迁移的原因,首先需要了解MQTT客户端在PostgreSQL架构中的工作方式。该架构围绕两个关键表构建。
device_session_ctx表负责维护每个持久MQTT客户端的会话状态:
Table "public.device_session_ctx"
Column | Type | Collation | Nullable | Default
--------------------+------------------------+-----------+----------+---------
client_id | character varying(255) | | not null |
last_updated_time | bigint | | not null |
last_serial_number | bigint | | |
last_packet_id | integer | | |
Indexes:
"device_session_ctx_pkey" PRIMARY KEY, btree (client_id)
关键列为last_packet_id和last_serial_number,用于维护持久MQTT客户端的消息顺序:
last_packet_id表示收到的最后一条MQTT消息的Packet ID。last_serial_number作为持续递增的计数器,用于防止在MQTT Packet ID达到65535上限回绕后导致消息顺序问题。
device_publish_msg表负责存储必须发布给持久MQTT客户端(订阅者)的消息:
Table "public.device_publish_msg"
Column | Type | Collation | Nullable | Default
--------------------------+------------------------+-----------+----------+---------
client_id | character varying(255) | | not null |
serial_number | bigint | | not null |
topic | character varying | | not null |
time | bigint | | not null |
packet_id | integer | | |
packet_type | character varying(255) | | |
qos | integer | | not null |
payload | bytea | | not null |
user_properties | character varying | | |
retain | boolean | | |
msg_expiry_interval | integer | | |
payload_format_indicator | integer | | |
content_type | character varying(255) | | |
response_topic | character varying(255) | | |
correlation_data | bytea | | |
Indexes:
"device_publish_msg_pkey" PRIMARY KEY, btree (client_id, serial_number)
"idx_device_publish_msg_packet_id" btree (client_id, packet_id)
需要重点说明的关键列:
time:记录消息存储时的系统时间(时间戳),该字段用于定期清理过期消息。msg_expiry_interval:表示消息过期时间(秒)。 仅对包含过期属性的传入MQTT 5.0消息生效。 若消息未携带过期属性,则没有固定过期时间,会一直保留,直到被基于时间或大小的清理策略移除。
这两个表共同承担消息持久化与会话状态管理。
device_session_ctx表用于快速检索每个持久MQTT客户端的最新MQTT Packet ID与Serial Number。
当Broker从共享Kafka Topic收到客户端消息时,会先查询该表获取最新值。
随后这些值会按顺序递增并分配给每条消息,再写入device_publish_msg表。
虽然该设计保障了消息可靠投递,但也带来了性能上限。 根据TimescaleDB博客文章, 在理想条件下,原生PostgreSQL每秒最多可处理约30万次插入。 但实际性能会受硬件、工作负载和表结构等因素影响。 即使通过垂直扩展获得一定提升,PostgreSQL单表插入吞吐最终仍会触达硬性上限。
Redis作为可扩展替代方案
我们选择迁移到Redis,核心原因在于它能够解决PostgreSQL遇到的关键性能瓶颈。 PostgreSQL依赖磁盘存储和垂直扩展,而Redis主要在内存中运行,可显著降低读写延迟。 此外,Redis的分布式架构使TBMQ能够水平扩展,即使在客户端会话数与消息存储量持续增长的情况下,也能保持高效的消息检索与投递。
基于这些优势,我们启动了迁移工作,并评估了既能满足Redis Cluster约束、又能保留PostgreSQL方案能力的数据结构,以实现高效水平扩展。 这也为我们提供了优化原有设计的契机,例如利用Redis内置过期机制改进定期清理策略。
Redis Cluster约束
从PostgreSQL迁移到Redis时,我们发现若要完整复用现有数据模型,就需要组合多种Redis数据结构,才能高效处理消息的持久化与排序。 这意味着每个持久MQTT客户端会话都需要多个Key。
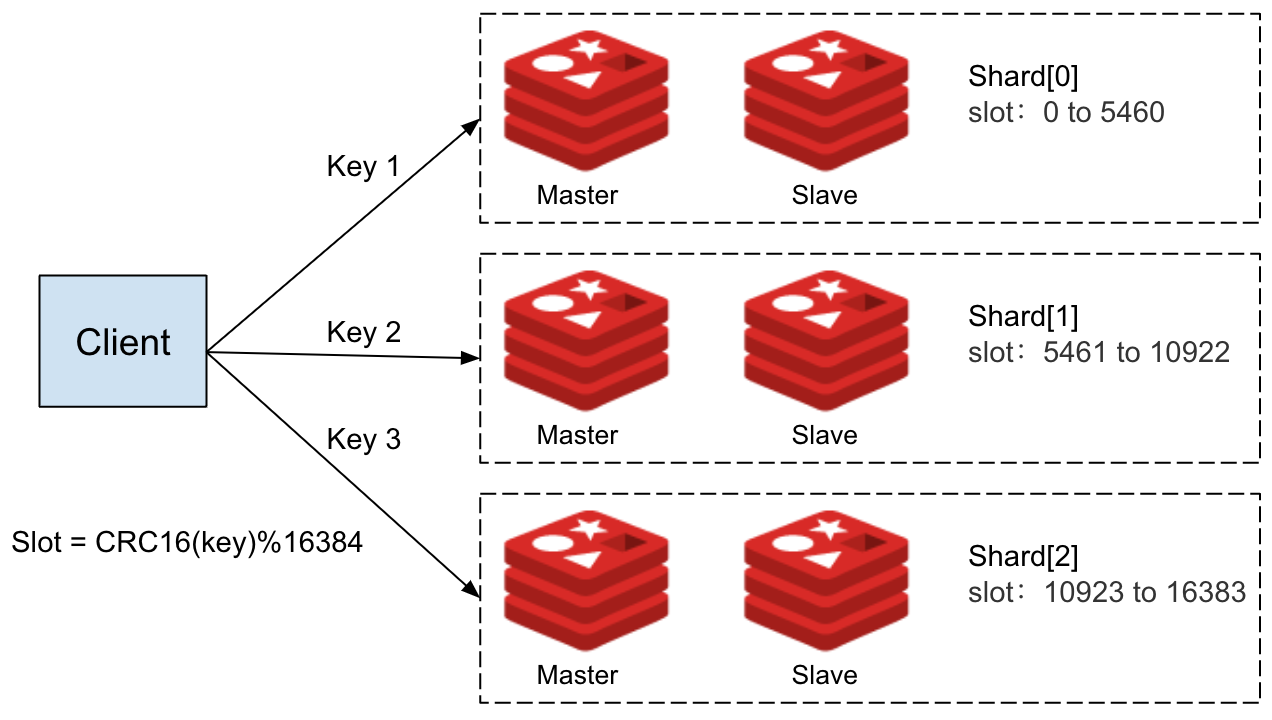
Redis Cluster通过将数据分布到多个Slot实现水平扩展。
但多Key操作必须访问同一Slot内的Key。
若Key分散在不同Slot,操作便会触发跨Slot错误并导致执行失败。
为解决该问题,我们在Key命名中使用持久MQTT客户端ID作为Hash Tag。
即通过将Client ID放入花括号{}中,使Redis将同一客户端的所有Key哈希至同一个Slot。
这样可确保单客户端相关数据聚合在一起,使多Key操作稳定执行且不报错。
通过Lua脚本实现原子操作
在TBMQ这类高吞吐环境中,一致性至关重要,同一MQTT客户端可能同时收到多条消息。 Hash Tag可避免跨Slot错误,但若缺乏原子操作,仍可能存在竞态条件或部分更新风险。 这可能导致消息丢失或顺序错误,因此确保更新同一MQTT客户端Key的操作具备原子性至关重要。
Redis单条命令天然具备原子性。 但在我们的场景中,单次处理往往涉及同一MQTT客户端多个数据结构的更新。 如果不具备整体原子性,一旦有其他进程在命令执行间隙插入修改,就会产生数据不一致。 这时Lua脚本就能发挥作用。Lua脚本作为单一隔离单元执行。 脚本执行期间,不允许其他命令并发运行,确保脚本内操作原子化执行。
基于此,我们决定:对于保存消息、重连检索未投递消息等关键操作,均通过独立Lua脚本完成。 这可确保单个Lua脚本内的所有操作位于同一Hash Slot,并同时保证原子性与一致性。
Redis数据结构
迁移的关键要求之一是保持消息顺序。此前该能力由PostgreSQL的device_publish_msg表中serial_number列承担。
在评估多种Redis数据结构后,我们确定Sorted Sets(ZSET)是最佳替代方案。
Redis Sorted Set会按Score自然组织数据,支持按升序或降序快速检索消息。
虽然Sorted Set适合维护顺序,但若将完整消息Payload直接存入Sorted Set,会造成较高内存占用。
Redis不支持对Sorted Set中单个成员设置TTL,因此消息若不被显式删除,将会长期保留。
与PostgreSQL类似,我们仍需使用ZREMRANGEBYSCORE定期清理过期消息。
该操作复杂度为 O(log N + M),其中 M 为移除的元素数。
为解决这一限制,我们决定将消息Payload存入String结构,并在Sorted Set中仅保存对应Key的引用。
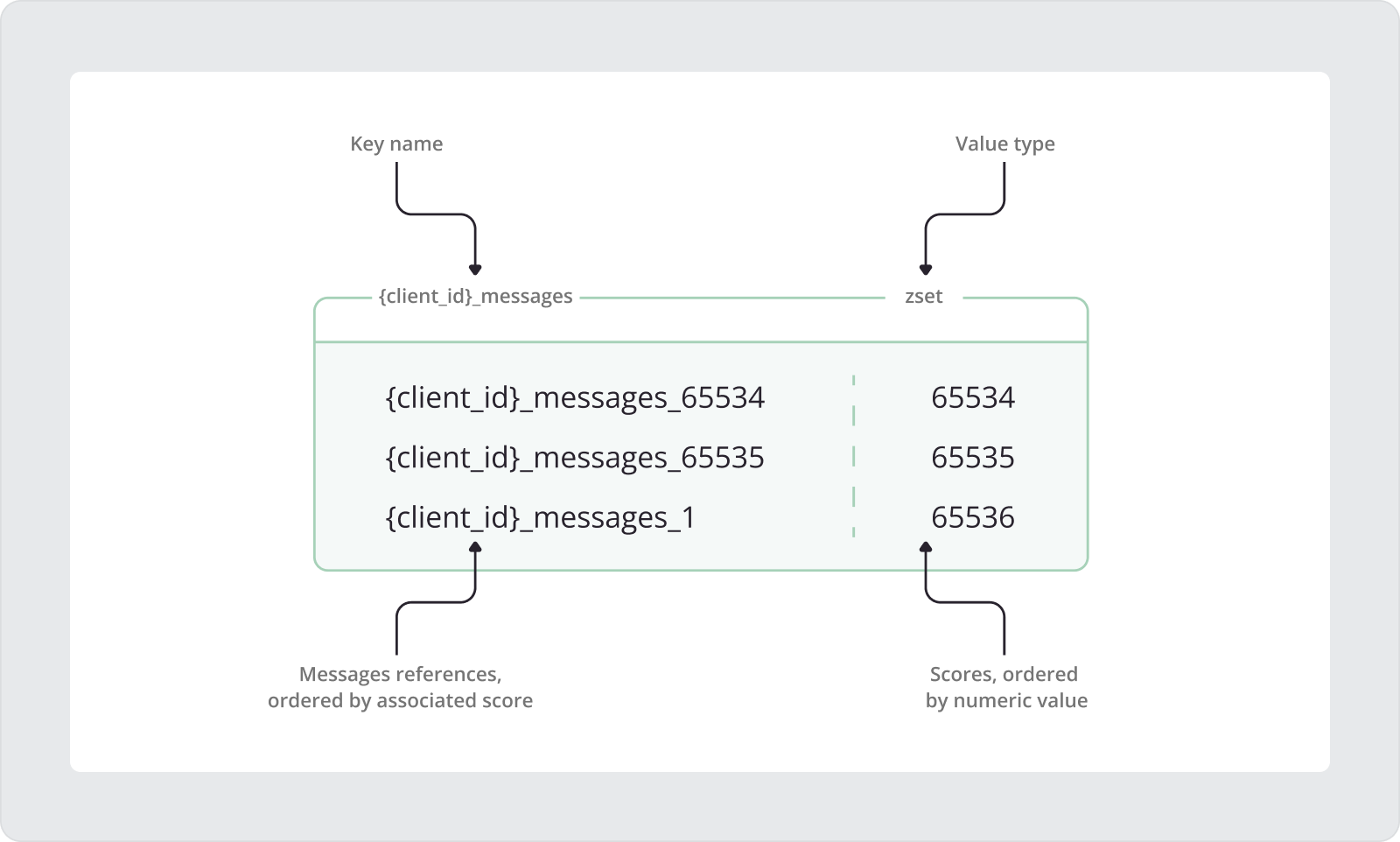
从上图可见,每个Key都遵循{client_id}_messages模式,
其中client_id是实际Client ID占位符,
其外层花括号{}用于创建Hash Tag。
另外,即使MQTT Packet ID发生回绕,Score仍会持续增长。
下面进一步说明图中流程。
首先,将MQTT Packet ID为65534的消息引用加入Sorted Set:
1
ZADD {client_id}_messages 65534 {client_id}_messages_65534
此处,{client_id}_messages是Sorted Set的Key名,{client_id}是由持久MQTT客户端唯一ID派生的Hash Tag。
后缀 _messages 是为一致性添加的常量。
在Sorted Set Key名之后,Score值65534对应客户端收到消息的MQTT Packet ID。
最后是引用Key,指向MQTT消息真实Payload。
与Sorted Set Key类似,消息引用Key同样使用MQTT客户端ID作为Hash Tag,后跟_messages后缀和MQTT Packet ID值。
下一次迭代中,将Packet ID为65535的MQTT消息引用加入Sorted Set。65535是Packet ID上限。
1
ZADD {client_id}_messages 65535 {client_id}_messages_65535
因此在下一轮中,MQTT Packet ID会回绕到1,但Score应继续增长到65536。
1
ZADD {client_id}_messages 65536 {client_id}_messages_1
这种方式可确保消息引用在Sorted Set中保持正确排序,不受Packet ID回绕影响。
消息Payload通过支持过期参数(EX)的SET命令存储为String值,可实现O(1)复杂度写入与TTL设置:
1
2
3
4
5
6
7
8
9
10
SET {client_id}_messages_1 "{
\"packetType\":\"PUBLISH\",
\"payload\":\"eyJkYXRhIjoidGJtcWlzYXdlc29tZSJ9\",
\"time\":1736333110026,
\"clientId\":\"client\",
\"retained\":false,
\"packetId\":1,
\"topicName\":\"europe/ua/kyiv/client/0\",
\"qos\":1
}" EX 600
除高效写入和TTL应用外,其另一优势是消息Payload可直接检索:
1
GET {client_id}_messages_1
或直接删除:
1
DEL {client_id}_messages_1
均为常数复杂度O(1),且不影响Sorted Set结构。
我们Redis架构的另一关键点,是使用String Key存储已处理的最后MQTT Packet ID:
1
2
GET {client_id}_last_packet_id
"1"
该方法与PostgreSQL方案中的作用一致。 客户端重连时,服务器必须确定正确的Packet ID,并将其分配给下一条即将写入Redis的消息。 最初我们考虑使用Sorted Set最高Score作为参考。 但考虑到Sorted Set可能为空或被整体移除, 我们最终认为最可靠的做法是单独存储最后Packet ID。
动态管理Sorted Set大小
这种将Sorted Set与String结合的方案,基本消除了基于时间的定期清理需求,因为现在每条消息都带有TTL。 此外,沿用PostgreSQL的设计,我们仍需根据配置中的消息上限控制Sorted Set的大小。
1
2
# Maximum number of PUBLISH messages stored for each persisted DEVICE client
limit: "${MQTT_PERSISTENT_SESSION_DEVICE_PERSISTED_MESSAGES_LIMIT:10000}"
该限制是设计中的关键约束,可帮助我们控制并预测每个持久MQTT客户端的内存占用。 例如,客户端可能连接后触发持久会话注册,随后迅速断开。 在这类场景中,必须确保该客户端在等待重连期间的消息存储数量始终受限,防止内存无限增长。
1
2
3
if (messagesLimit > 0xffff) {
throw new IllegalArgumentException("Persisted messages limit can't be greater than 65535!");
}
为贴合MQTT协议天然约束,单个客户端最大持久消息数设置为65535。
为在Redis方案中落实该逻辑,我们实现了Sorted Set大小的动态管理。 新增消息时会裁剪Sorted Set,确保消息总数不超过上限,并同步清理关联String以释放内存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- Get the number of elements to be removed
local numElementsToRemove = redis.call('ZCARD', messagesKey)-maxMessagesSize
-- Check if trimming is needed
if numElementsToRemove > 0 then
-- Get the elements to be removed (oldest ones)
local trimmedElements = redis.call('ZRANGE', messagesKey, 0, numElementsToRemove-1)
-- Iterate over the elements and remove them
for _, key in ipairs(trimmedElements) do
-- Remove the message from the string data structure
redis.call('DEL', key)
-- Remove the message reference from the sorted set
redis.call('ZREM', messagesKey, key)
end
end
消息检索与清理
该设计不仅在持久化新消息时具备动态大小管理能力,也支持在消息检索阶段进行清理, 即设备重连并处理未投递消息时。 具体做法是移除失效消息引用,以保持Sorted Set整洁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
-- Define the sorted set key
local messagesKey = KEYS[1]
-- Define the maximum allowed number of messages
local maxMessagesSize = tonumber(ARGV[1])
-- Get all elements from the sorted set
local elements = redis.call('ZRANGE', messagesKey, 0, -1)
-- Initialize a table to store retrieved messages
local messages = {}
-- Iterate over each element in the sorted set
for _, key in ipairs(elements) do
-- Check if the message key still exists in Redis
if redis.call('EXISTS', key) == 1 then
-- Retrieve the message value from Redis
local msgJson = redis.call('GET', key)
-- Store the retrieved message in the result table
table.insert(messages, msgJson)
else
-- Remove the reference from the sorted set if the key does not exist
redis.call('ZREM', messagesKey, key)
end
end
-- Return the retrieved messages
return messages
通过结合Redis的Sorted Set与String结构,并借助Lua脚本实现原子操作,新方案实现了高效的消息持久化、检索与动态清理。 这也从根本上解决了PostgreSQL方案中的可扩展性限制。
Jedis迁移到Lettuce
为了验证基于Redis的新持久化消息存储架构是否具备良好可扩展性,我们选择点对点(P2P)MQTT通信模式作为性能测试场景。 与扇入(多对一)或扇出(一对多)场景不同,P2P模式通常是一对一通信,并且每一对通信端都会创建新的持久会话。 因此,这种模式非常适合用来评估系统在会话数量持续增长时的扩展能力。
在开展大规模测试前,我们完成了原型验证。结果显示:使用PostgreSQL进行持久化消息存储时,吞吐量上限约为30k msg/s。 迁移到Redis时,我们当时使用的是Jedis库,其主要用途是缓存管理。 因此,最初我们决定在Jedis基础上扩展,实现持久化MQTT客户端的消息存储。 但基于Jedis的Redis实现初测结果并不理想。虽然我们预期Redis性能会显著优于PostgreSQL,但实际提升有限,吞吐量仅从PostgreSQL的30k msg/s提高到40k msg/s。
这促使我们进一步排查瓶颈,最终发现Jedis是主要限制因素之一。 Jedis虽然稳定可靠,但采用同步方式工作,即Redis命令按顺序逐条执行。 这会导致系统必须等待上一条操作完成后,才能执行下一条。 在高吞吐环境下,这种机制会明显限制Redis的潜力,无法充分利用系统资源。 为了解决这一问题,我们迁移到Lettuce——一个基于Netty构建的异步Redis客户端。 迁移后,吞吐量提升到60k msg/s,验证了非阻塞处理和更高并行能力带来的显著收益。
Lettuce支持多条命令并行发送与处理,能够充分释放Redis在并发负载场景下的处理能力。 最终,这次迁移让我们真正获得了预期中的Redis性能提升,也为大规模P2P测试奠定了基础。 如果你想深入了解测试架构、方法与结果,欢迎阅读我们的性能测试文章。