点对点(P2P)通信是MQTT的核心模式之一,可让设备以一对一方式直接交换消息。 该模式特别适用于需要可靠定向消息的IoT场景,例如私信、命令下发及其他直接交互类用例。 本次测试旨在评估代理在P2P通信场景下配合持久化DEVICE客户端时的表现。 持久化DEVICE客户端非常适合P2P消息场景:它通过共享Kafka主题降低Kafka负载,并借助Redis 在客户端临时离线期间仍保障可靠投递。测试将负载从200,000逐步提升至1,000,000条/秒, 并同步扩展基础设施,最终展示了TBMQ的可扩展性与稳定性能。
测试方法
为评估TBMQ在大规模点对点通信下的能力,我们共执行了五项测试,重点衡量性能、资源效率和延迟,最高吞吐量达到1M条/秒。 这里的吞吐量是指每秒消息总数,包含入站与出站消息。 测试环境部署在AWS EKS集群,并随负载上升进行水平扩容。 通过这种方式,我们可以验证TBMQ在需求持续增长时,是否仍能保持可靠且稳定的性能。
每项测试均运行10分钟,发布者与订阅者数量保持一致。
发布者与订阅者均使用QoS1以确保可靠投递。
订阅者将clean_session设置为false,
以便在离线期间保留全部消息,并在重连后继续接收。
发布者每秒向唯一主题"europe/ua/kyiv/$number"发送62字节消息,
订阅者订阅对应主题"europe/ua/kyiv/$number/+"。
其中$number作为每对发布者与订阅者的唯一标识。
测试代理配置
测试代理 用于模拟发布者和订阅者,从而在消息流量持续增长时真实评估TBMQ性能。 该代理由性能测试pod(runner)集群和负责监控的编排器pod组成。 runner pod分为两类:发布者和订阅者。测试期间,发布者pod数量始终与订阅者pod数量一致, 且发布者pod使用的实例数始终等于订阅者pod使用的实例数。下表展示各吞吐量级别下,单类runner(发布者或订阅者)的每实例pod数量及部署实例数。
| 吞吐量(条/秒) | 每实例Pod数 | EC2实例数 |
|---|---|---|
| 200k | 5 | 1 |
| 400k | 5 | 1 |
| 600k | 10 | 1 |
| 800k | 5 | 2 |
| 1M | 5 | 4 |
编排器pod部署在独立EC2实例上,该实例还运行了Kafka Redpanda console和Redis Insight等组件,用于监控与协调。 该灵活配置使测试代理在流量增长时仍可正常运行,并能处理端口限制等基础设施约束。
基础设施概览
为清晰呈现测试环境,本节详细说明各服务的硬件规格,以及EKS集群pod在AWS EC2实例上的分布情况。
硬件规格
| 服务名称 | TBMQ | Kafka | Redis | AWS RDS(PostgreSQL) |
|---|---|---|---|---|
| 实例类型 | c7a.4xlarge | c7a.large | c7a.large | db.m6i.large |
| vCPU | 16 | 2 | 2 | 2 |
| 内存(GiB) | 32 | 4 | 4 | 8 |
| 存储(GiB) | 20 | 30 | 8 | 20 |
| 网络带宽(Gibps) | 12.5 | 12.5 | 12.5 | 12.5 |
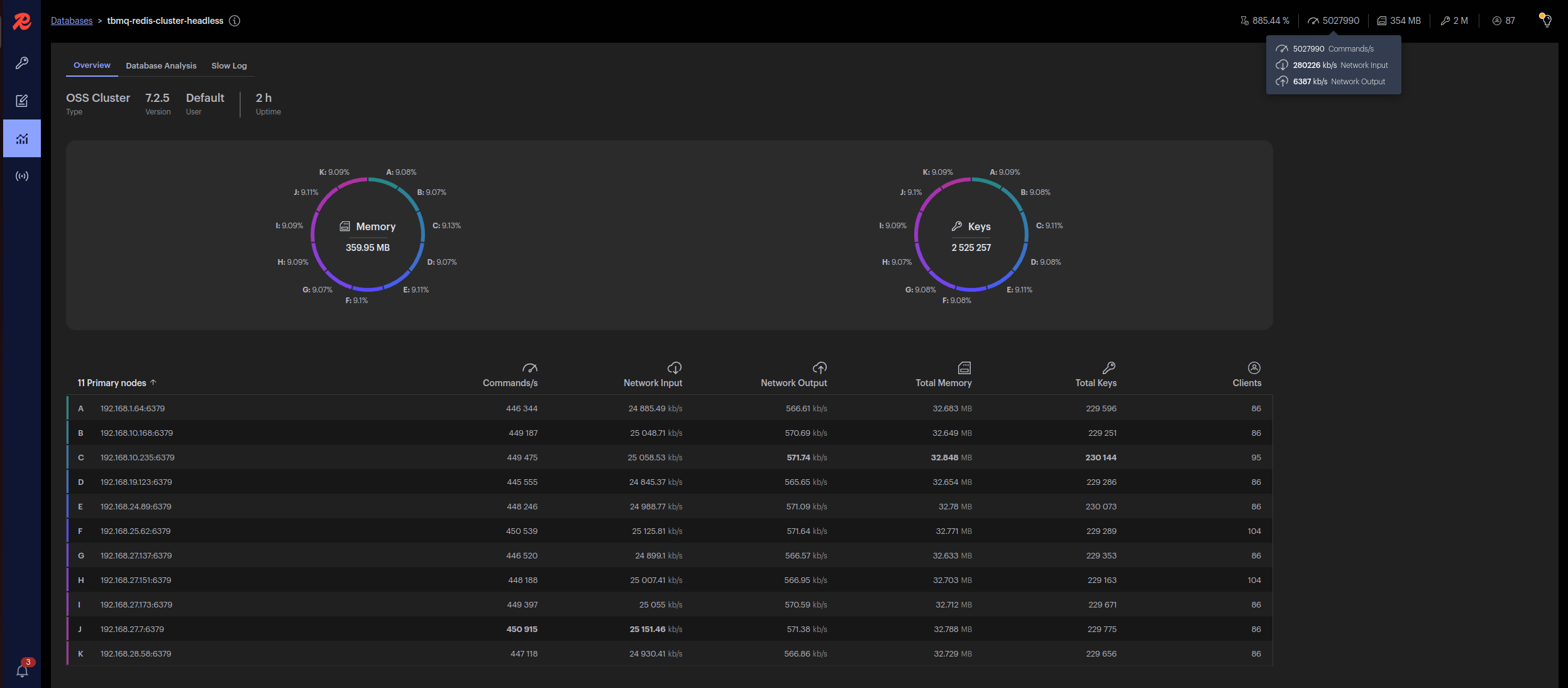
注意: 所有测试仅使用Redis主节点,未启用副本,以降低负载测试成本。 该配置有助于在不过度配置资源的前提下达到目标吞吐量。
EC2实例与Pod分布
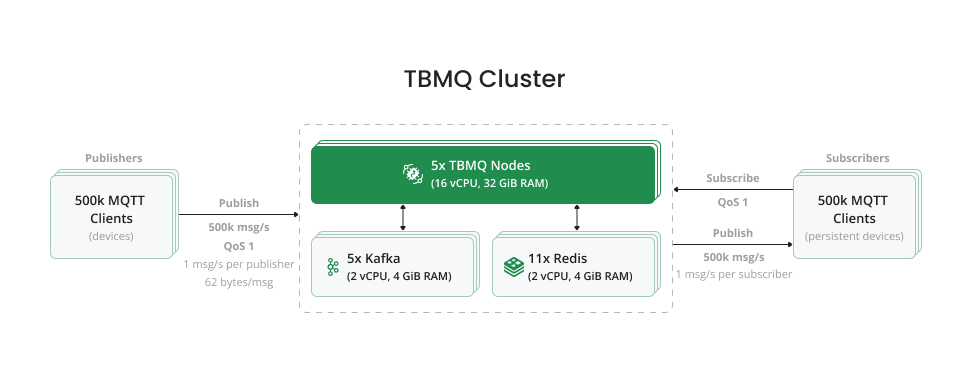
下图展示本测试中AWS EC2实例与EKS集群pod在其上的分布:
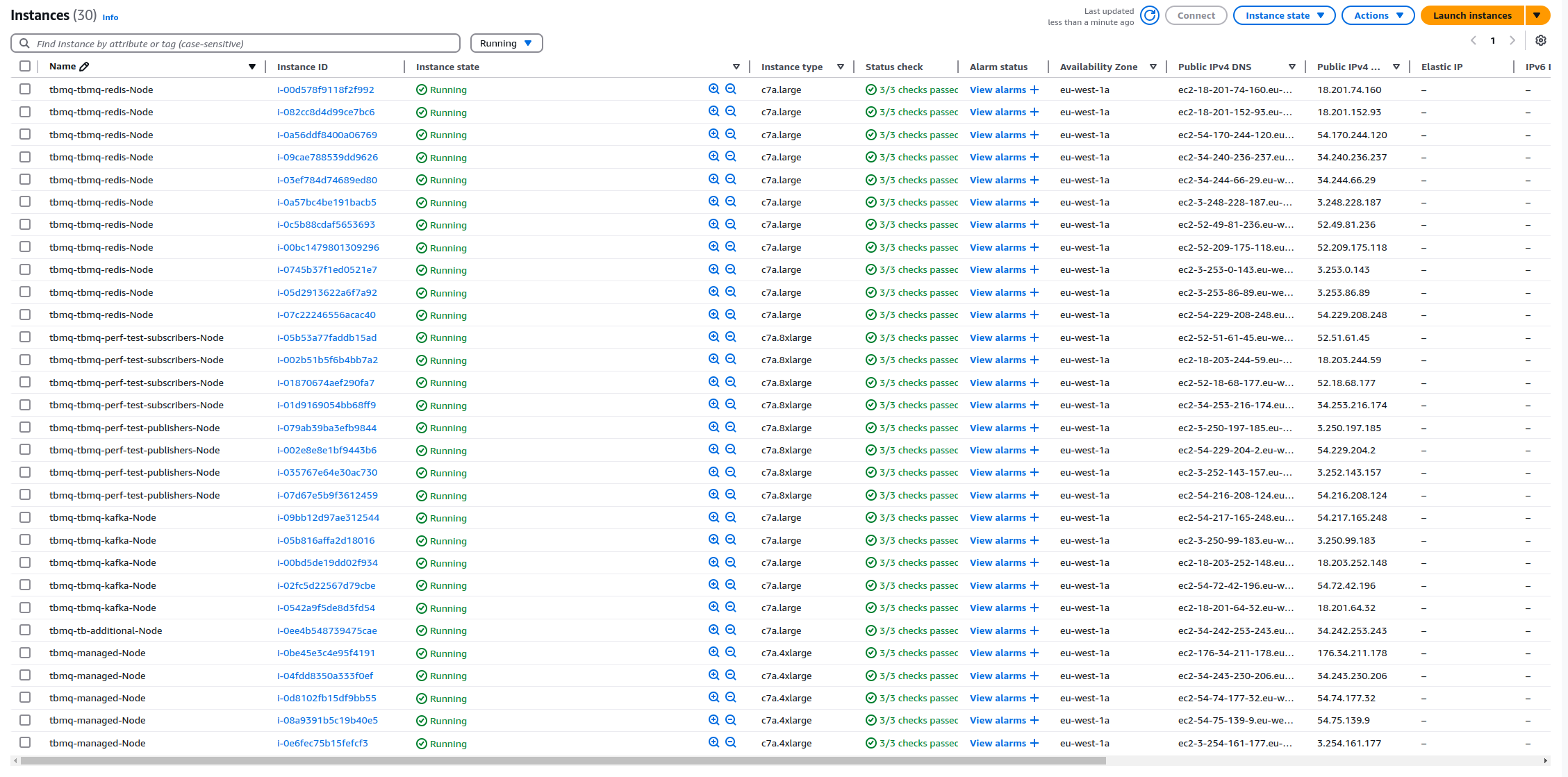
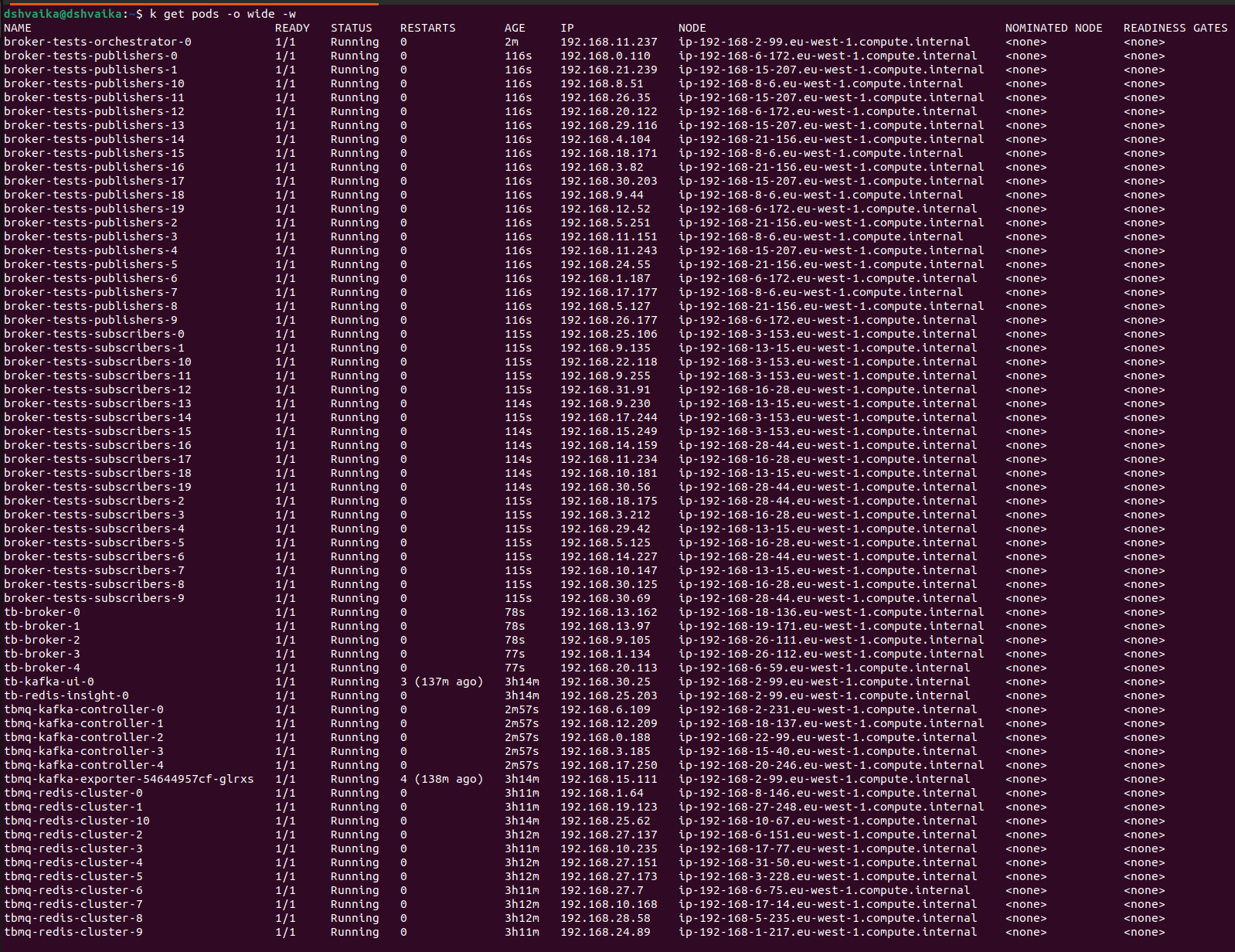
注意: 图中展示的是最终测试(1M条/秒吞吐量)对应的基础设施配置。
每轮测试都会根据负载动态调整实例规模,详见下一节。
性能测试
TBMQ性能测试按阶段推进:从200k条/秒起步,每次增加200k,直至1M条/秒。 每个阶段都会调整TBMQ代理节点数和Redis节点数;在1M条/秒测试中,还额外扩展Kafka节点数以承载更高负载。 下表汇总了各阶段测试配置。
| 吞吐量(条/秒) | 发布者/订阅者 | TBMQ节点数 | Redis节点数 | Kafka节点数 |
|---|---|---|---|---|
| 200k | 100k | 1 | 3 | 3 |
| 400k | 200k | 2 | 5 | 3 |
| 600k | 300k | 3 | 7 | 3 |
| 800k | 400k | 4 | 9 | 3 |
| 1M | 500k | 5 | 11 | 5 |
测试关键结论如下:
- 可扩展性:TBMQ表现出线性扩展能力。随着负载从200k提升到1M条/秒,通过逐步增加TBMQ、Redis和Kafka节点,系统始终保持稳定可靠。
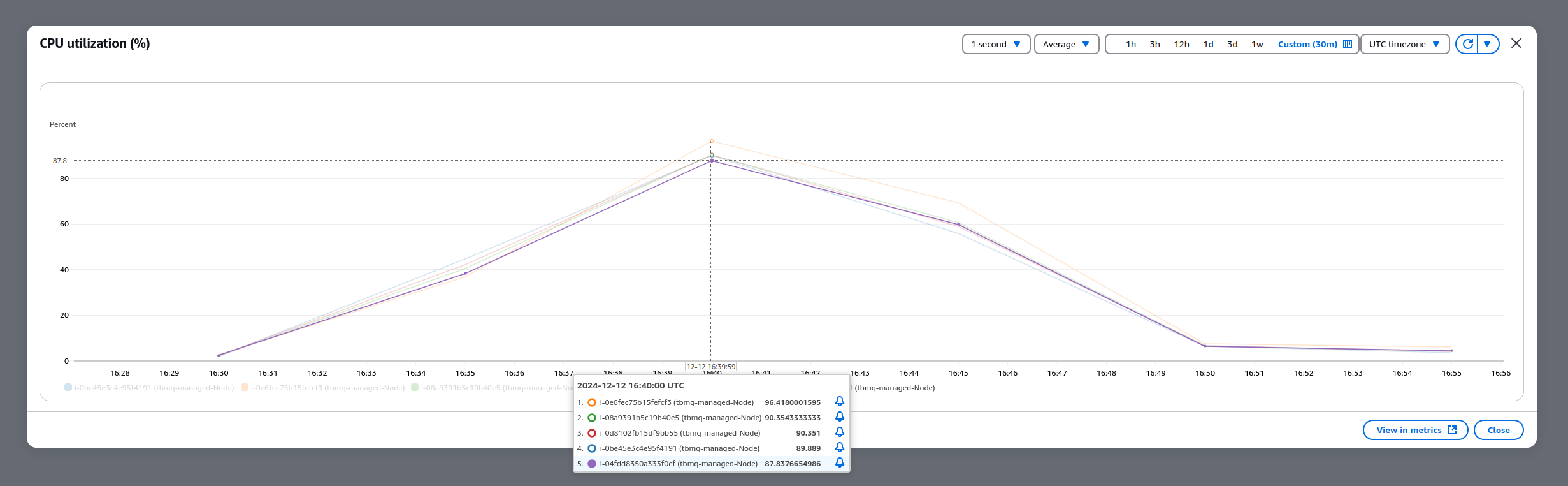
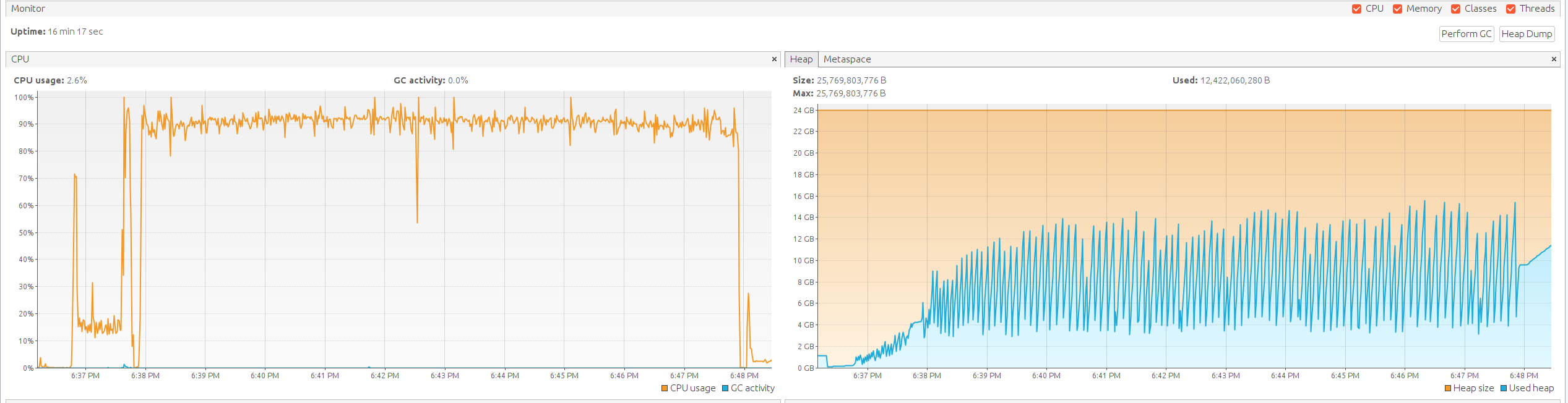
- 资源利用率:在所有测试阶段,TBMQ节点CPU利用率基本维持在约90%,表明系统能够高效利用资源且不过度消耗。
- 延迟控制:所有测试中的消息延迟均保持在两位数毫秒范围内。这与本次测试统一采用的QoS1(发布者与持久化订阅者)预期一致。 同时我们还跟踪了发布者确认延迟,其平均值在各阶段均保持在个位数毫秒范围内。
- 高性能:在一对一通信模式下,TBMQ表现出优异效率,约达到每CPU核心8900条/秒。 该值通过总吞吐量除以测试环境总CPU核心数计算得出。
此外,下表与监控截图汇总了最终1M条/秒测试的核心结果。
| QoS | 消息平均延迟 | 发布确认平均延迟 | TBMQ平均CPU | 消息体(字节) |
|---|---|---|---|---|
| 1 | ~75ms | ~8ms | 91% | 62 |
其中:
- TBMQ平均CPU:所有TBMQ节点的平均CPU利用率。
- 消息平均延迟:消息从发布者发送到订阅者接收的平均耗时。
- 发布确认平均延迟:发布者发送消息到收到PUBACK确认的平均耗时。
这些结果表明,TBMQ能够在点对点消息场景中提供可靠、可扩展且高性能的消息能力。 我们将继续在不牺牲可靠性的前提下推进性能优化。 关于后续潜在改进,请参阅未来优化章节。
如何复现1M条/秒吞吐量测试
建议先阅读我们的安装指南,其中提供了在AWS上部署TBMQ的分步说明。 此外,你还可以查看本次性能测试使用的脚本与参数所在分支,以深入了解具体配置。 在性能测试执行层面,我们提供了专用性能测试工具, 可用于生成MQTT客户端并模拟目标消息负载。尤其针对P2P场景,我们对测试工具进行了增强,使其能够自动生成发布者与订阅者配置, 而无需从JSON配置文件加载。更多P2P测试配置细节请参考README.md。
从Jedis迁移到Lettuce:解决关键测试瓶颈
性能测试期间最关键的挑战之一,是突破Jedis库在高吞吐场景中的限制。 Jedis采用同步调用模型,会按顺序发送并处理Redis命令,系统必须等待前一条命令完成后才能继续下一条。 这种方式显著限制了Redis并发处理能力,也难以充分利用可用系统资源。
为解决该问题,我们迁移到了Lettuce客户端。 Lettuce底层基于Netty实现高效异步通信。 与Jedis不同,Lettuce允许在不等待前序命令完成的情况下并行发送多条命令,从而实现非阻塞处理并提升资源利用率。 这种架构使我们能够在高消息负载下更充分释放Redis性能。
当然,迁移到Lettuce并不简单。 我们需要将较大规模代码从同步流程改造为异步流程,包括重构Redis命令的发送与处理方式。 通过审慎设计与严格测试,我们确保了变更后的系统在可靠性与正确性方面保持稳定。
未来优化
目前,我们在Redis中使用Lua脚本处理DEVICE持久化客户端消息。 这些脚本可保证消息保存、更新、删除操作的原子性,这对数据一致性非常关键。 但受Redis Cluster约束影响(单个脚本访问的所有key必须位于同一哈希槽),我们当前采用“每个客户端执行一次脚本”的方式。
为进一步优化性能,我们正在评估调整客户端ID哈希机制,主动将更多客户端聚合到同一Redis哈希槽中。 这样可以提升按哈希槽批处理的概率,使单次Lua脚本执行同时处理多个客户端。 该方案有望降低处理开销并提升Redis效率,同时继续满足集群约束。
结论
在全部五轮测试中,TBMQ展现出线性可扩展性与高效资源利用率。 随着负载从200,000提升至1,000,000条/秒,系统始终保持可靠消息投递,并将延迟控制在点对点场景可接受的高效范围内。
这些能力使TBMQ成为高性能一对一通信且要求可靠投递的IoT场景中的可信选择。 我们将持续探索进一步优化路径以提升性能,而现有结果已经证明TBMQ能够胜任高吞吐业务需求。