MQTT broker的一项重要能力是接收客户端发布的消息、基于topic进行过滤,并将消息分发给订阅者。 这一过程在高负载下尤为重要。 本文将介绍为确保TBMQ能够可靠处理约 1亿连接客户端并有效管理每秒600万条MQTT发布消息吞吐量所采取的措施。
测试方法
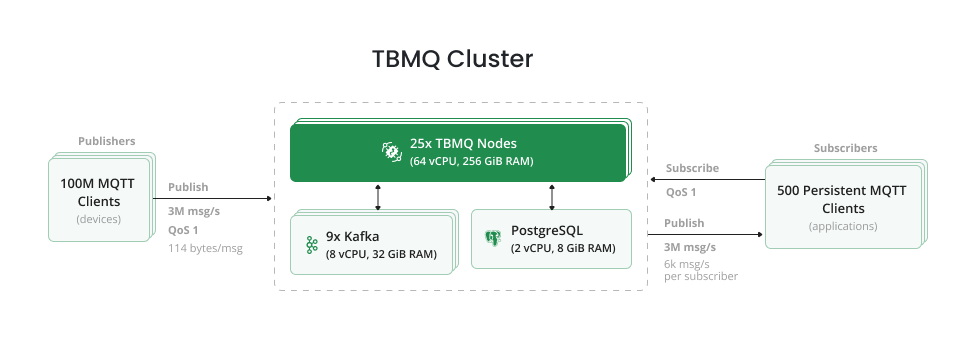
我们选择Amazon Web Services (AWS) 作为执行性能测试的云提供商。 在 EKS 集群中部署了25节点的TBMQ集群(每个EC2实例/节点部署1个broker pod),并连接 RDS 和 Kafka。 有关TBMQ架构的全面了解,请参阅后续页面。 RDS以单实例部署,Kafka由9个broker组成,分布在3个可用区 (AZ) 中。
不同IoT设备配置在产生的消息数量和每条消息大小上各不相同。 我们模拟了发送含五个数据点的消息的智能追踪器设备。单条 “publish” 消息大小约为 114字节。 以下是模拟消息结构,与真实测试用例略有不同,因为测试agent会生成有效载荷值。
1
{ "lat": 40.761894, "long": -73.970455, "speed": 55.5, "fuel": 92, "batLvl": 81 }
发布者分为500个组,总计20万个发布者,每组6k msg/s。
每组负责向其指定的topic模式传输数据,格式为 CountryCode/RandomString/GroupId/ClientId。
因此,发布者使用了约 1亿个不同topic的广泛范围。
同时配置了500个订阅者组,每组包含一个 APPLICATION 订阅者。
这些订阅者使用的topic过滤器与各自发布者组的topic模式对应(即 CountryCode/RandomString/GroupId/+)。
因此,每个订阅者每秒可接收6k条消息,确保高效处理入站数据。
在上述场景中,TBMQ集群稳定维持100,000,500个连接,有效处理每秒600万条消息的吞吐量。 吞吐量指每秒消息总数,包括入站和出站消息。 每秒处理300万条入站消息,在1小时测试运行中总计108亿条消息。
测试 agent 协调MQTT客户端的配置和建立,支持灵活配置其数量。 这些客户端持续运行,不断通过MQTT向指定topic发布时序数据。 此外,agent还负责配置通过topic过滤器订阅以接收上述客户端发布的消息的MQTT客户端。
考虑到客户端的预热阶段,值得注意的是进行了6轮发布者各发送单条消息的操作。 因此,约7分钟内生成了总计6亿条预热消息。 这些预热消息用于准备系统并启动数据流。 除预热阶段外,整个测试共处理了114亿条消息。 该数字涵盖预热消息及完整测试期间产生和处理的后继消息。
该数据量约为1TB,存储在标记为 tbmq.msg.all 的初始Kafka topic中。
每个配置为APPLICATION订阅者的订阅者在Kafka中都有专用topic,
接收累计2280万条消息以供进一步处理和分析。
值得注意的是,在500个订阅者的配置下,数据收集仅依赖Kafka,Postgres不参与。
因为当前配置仅包含归类为 APPLICATION 的持久客户端。
提示:如需规划和管理Kafka磁盘空间,请调整 大小保留策略 和 时长保留策略。 有关各topic相关配置的详细信息,请参阅配置文档。
每个MQTT客户端与broker建立独立连接。 该方法确保每个客户端独立运行并保持与broker的专用连接以实现无缝通信。
使用的硬件
| 服务名称 | TBMQ | AWS RDS (PostgreSQL) | Kafka |
|---|---|---|---|
| 实例类型 | m6g.metal | db.m6i.large | m6a.2xlarge |
| 内存 (GiB) | 256 | 8 | 32 |
| vCPU | 64 | 2 | 8 |
| 存储 (GiB) | 10 | 100 | 500 |
| 网络带宽 (Gibps) | 25 | 12.5 | 12.5 |
测试总结
客户端连接速率达到了约22k连接/秒的显著水平,表明配置高效。 为确保无资源泄漏或随时间性能下降,测试执行了1小时,以便进行充分观察和分析。
以每秒300万条发布消息的速率(含预热消息),整个测试共处理了114亿条消息,实现约1TB的入站和出站吞吐量。
该数据量展示了TBMQ的可扩展性和处理能力。
为保持高可靠性和消息投递保障,发布者和订阅者均采用 1 级MQTT服务质量 (QoS),即 AT_LEAST_ONCE。
该QoS级别确保消息至少投递一次,保证数据完整性和一致性。
考虑到测试的全面性,下表总结了关键要素和结果,便于查阅。
| 设备数 | 吞吐量 (msg/秒) | Broker CPU | Broker内存 | Kafka CPU | Kafka读写吞吐量 | PostgreSQL CPU | PostgreSQL读写IOPS |
|---|---|---|---|---|---|---|---|
| 100M | 6M | 45% | 160GiB | 58% | 7k / 80k KiB/s | 2% | 小于1 / 小于3 |
以下统计提供了测试期间使用的Kafka topic的洞察
(即 publish_msg,Kafka topic重命名 [1] 后为 tbmq.msg.all,
是存储所有消息的主Kafka topic,以及若干接收数据的APPLICATION订阅者的应用topic示例)。
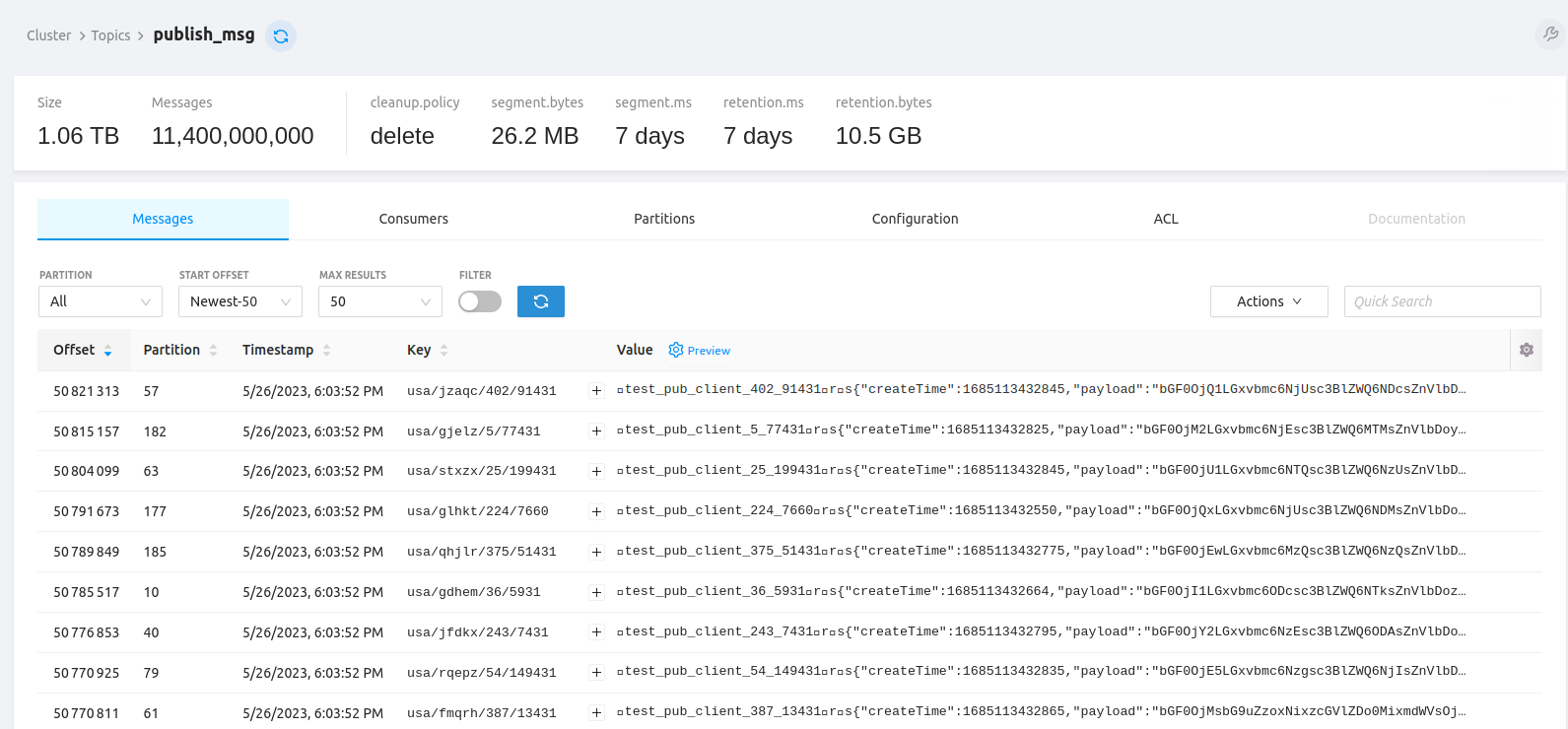
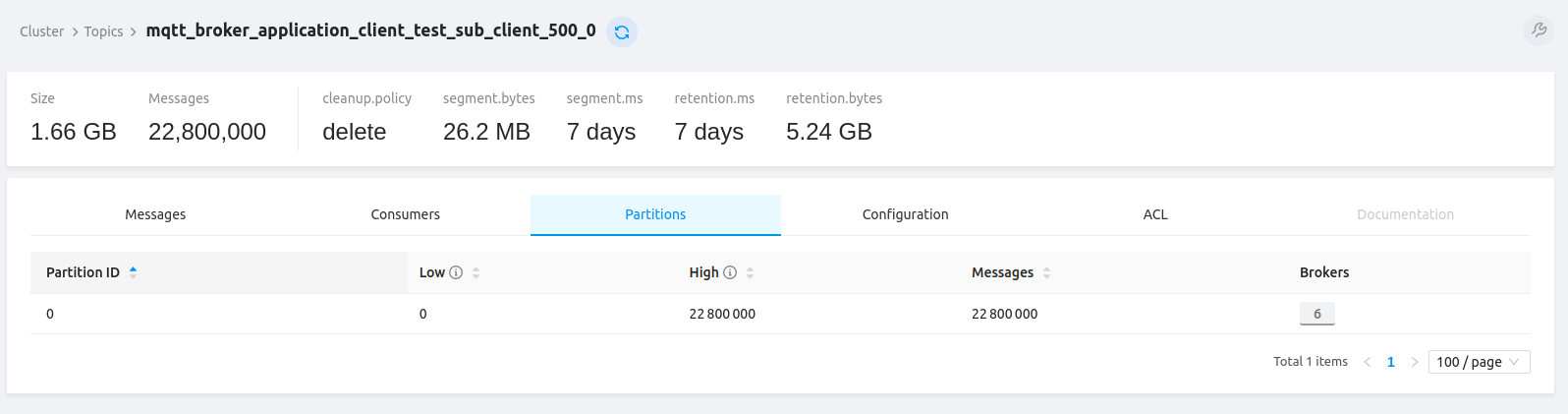
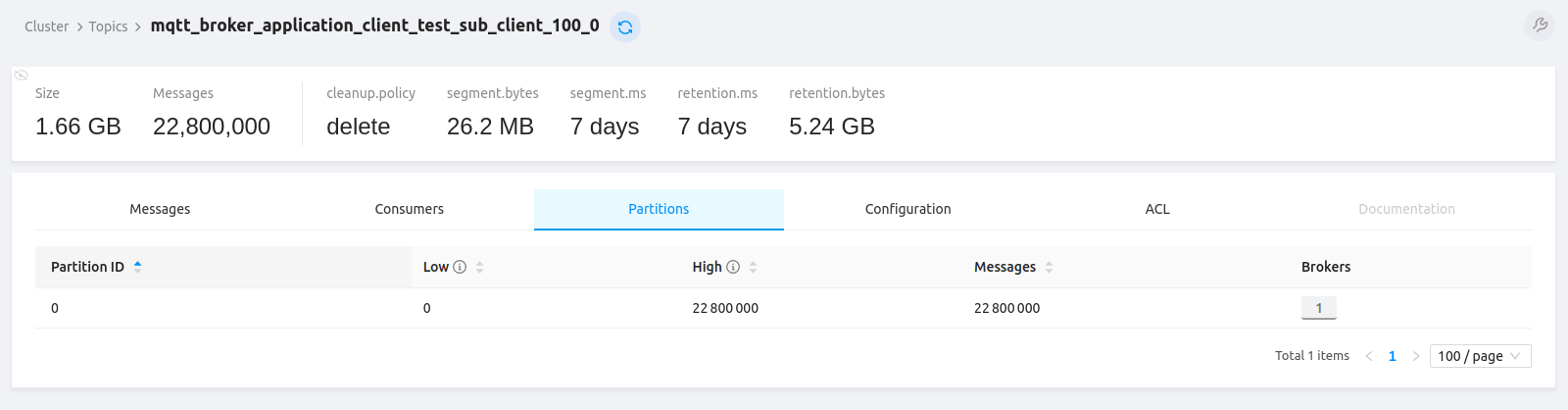
需要强调的是,所提供信息显示处理所有消息的成功率为100%。
publish_msg 和应用topic包含压缩数据,因为生产者发送压缩数据且Kafka broker保留生产者设置的原始压缩编解码器(compression.type 属性)。
该方法在保持消息完整性和原始压缩设置的同时,确保高效的数据存储和传输。
接下来关注消息处理延迟。 下表包含关键统计,阐明该评估方面:
| 消息延迟 平均值 | 消息延迟95分位 | 发布确认 平均值 | 发布确认95分位 |
|---|---|---|---|
| 195 ms | 295 ms | 23 ms | 55 ms |
其中 “消息延迟 平均值” 表示从发布者发送消息到订阅者接收的平均时长,
“发布确认 平均值” 表示从发布者发送消息到收到 PUBACK 确认的平均时间,
95分位为相应延迟统计的95百分位。
经验总结
当前配置下的TBMQ集群具备处理更大负载的能力。Kafka提供可靠且高可用的消息处理。
在此场景中,APPLICATION 订阅者的使用以及测试性质导致PostgreSQL负载最小,每秒仅执行少量操作。
TBMQ节点之间无直接通信,有助于水平扩展以达到上述结果。
尽管采用QoS 0可进一步提高消息速率,我们的目的是以更实际的配置展示TBMQ的处理能力。
一般而言,QoS 1因在消息投递速度与可靠性之间取得平衡而广受欢迎。
TBMQ适合低消息速率和高消息速率场景。
在fan-in、p2p和fan-out等多种处理场景中表现优异,同样适用于不同规模的部署。
凭借其固有的垂直和水平可扩展能力,broker可适应小规模或大规模部署的需求。
测试期间遇到的挑战
在追求如此大规模的连接和数据流过程中,我们遇到了一些需要投入精力进行代码优化的场景。
例如,解决Kafka生产者断开连接问题,该问题会带来消息丢失的不利后果。 为解决此问题,我们实现了专用于处理 Kafka生产者的发布回调 [2] 的独立executor服务。 该措施有效解决了上述断开连接问题。
为进一步提升性能,我们通过利用Kafka生产者固有的线程安全特性,消除了对专用发布队列的需求 [3]。 该调整以另一种方式实现了消息排序保证,从而在整体系统效率方面带来额外收益。
引入了额外调整以提高处理速率,如与 消息包处理、UUID生成 [4] 改进相关的提交, 以及采用 无需显式刷新即可发送消息 [5] 的机制。
为优化内存利用率并减少不必要的垃圾产生,我们进行了大量工作以改进整体内存使用。 这些增强 6、 7、 8 不仅提升了Garbage Collector性能,还减少了stop-the-world暂停,从而改善了整体系统响应性。
在后期的大规模测试阶段,我们观察到客户端在broker节点之间分布不均。 这导致特定broker节点负载disproportionate,对发布者影响较小,但对APPLICATION客户端影响显著,需要更多资源。 结果是一个broker节点处理的请求远多于其他节点。 为解决此问题,我们设计了一种机制,确保 broker节点间的客户端均匀分布 [9], 并伴随其他小幅性能改进。
通过这些努力,我们成功解决了沿途的各种挑战,优化了代码性能,确保了系统的平稳高效运行。
TCO计算
以下为使用AWS部署TBMQ的总拥有成本 (TCO) 计算。
重要说明:以下所有计算和价格均为近似值,仅供说明用途。 要获取精确的价格信息,强烈建议咨询您的云服务提供商。 例如,AWS提供多种成本节省机会,如 Savings Plans(最高 72% 折扣)、 RDS Reserved Instances(最高 69%)、 MSK Tiered Storage(50% 或更多), 以及多种其他选项。
us-east-1区域的AWS EKS集群。约73美元/月。
AWS实例类型:25 x m6g.metal实例(64 vCPU AWS Graviton2处理器,256 GiB,EBS GP3 10GiB)托管25个TBMQ节点。约23,800美元/月。
AWS RDS:db.m6i.large(2 vCPU,8 GiB),100GiB存储。约100美元/月。
AWS MSK:9个broker(每AZ 3个broker)x m6a.2xlarge(8 vCPU,32 GiB),4,500GiB总存储。约2,600美元/月。
TCO:约26,573美元/月或每设备每月0.0003美元。
运行测试
负载配置:
- 1亿个发布MQTT客户端(智能追踪器设备);
- 500个持久订阅MQTT客户端(消费数据的特定应用,如用于分析/图表);
- 通过MQTT每秒600万条消息吞吐量,每条MQTT消息包含5个数据点,消息大小114字节;
- PostgreSQL数据库存储MQTT客户端凭证、客户端会话状态;
- Kafka队列持久化消息。
如前所述,上述消息速率和消息大小在初始Kafka topic中每小时产生约 ~1TB 数据, 每个订阅者topic每小时约 ~1.6GB 数据。
但是,出于可视化、分析等目的,不必长期存储数据。 TBMQ负责接收消息、在订阅者之间分发,并可选择为离线客户端临时存储。 因此,建议根据您的具体需求配置适当的存储大小。 此外,提醒您务必配置Kafka topic的大小保留策略和时长保留策略。
测试agent由性能测试节点(runner)集群和监督这些runner的编排器组成。 为实现runner角色,我们部署了2000个发布者和500个订阅者Kubernetes pod,另有一个pod作为编排器。
通过利用JSON配置,我们可以分别指定发布者和订阅者,将其组织成组以便灵活控制。 下面查看发布者和订阅者的配置。
发布者组:
1
2
3
4
5
6
{
"id":1,
"publishers":200000,
"topicPrefix":"usa/ydwvv/1/",
"clientIdPrefix":null
}
其中
- id-发布者组标识符;
- publishers-组中发布者客户端数量;
- topicPrefix-发布消息的topic前缀;
- clientIdPrefix-发布者的客户端ID前缀。
订阅者组:
1
2
3
4
5
6
7
8
9
10
{
"id":1,
"subscribers":1,
"topicFilter":"usa/ydwvv/1/+",
"expectedPublisherGroups":[1],
"persistentSessionInfo":{
"clientType":"APPLICATION"
},
"clientIdPrefix":null
}
其中
- id-订阅者组标识符;
- subscribers-组中订阅者客户端数量;
- topicFilter-订阅的topic过滤器;
- expectedPublisherGroups-当前订阅者将接收其消息的发布者组id列表(该参数用于调试和统计目的);
- persistentSessionInfo-包含客户端类型的持久化信息对象;
- clientIdPrefix-订阅者的客户端ID前缀。
测试运行
测试从客户端与集群建立连接开始。APPLICATION 客户端订阅相关topic,发布者进入预热阶段。
100,000,500个客户端在性能测试pod之间均匀分布,便于与broker并行连接。
一段时间后,所有客户端成功建立连接,每个性能测试pod通知编排器其就绪状态。
为评估进度,我们可以查看 client_session(Kafka topic重命名 [1] 后为 tbmq.client.session)
Kafka topic。该topic提供连接会话的近似计数。
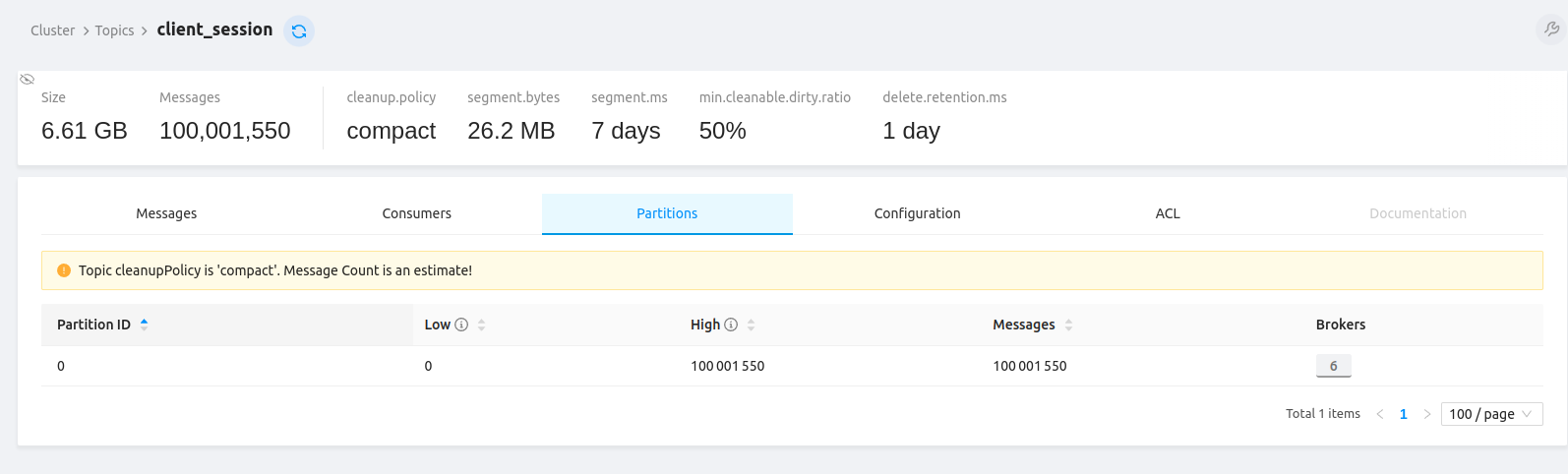
当所有runner就绪后,编排器通知集群已就绪,消息发布开始。
1
09:12:35.407 [main] INFO o.t.m.b.tests.MqttPerformanceTest-Start msg publishing.
经过一段时间的处理后,我们可以评估测试期间使用的JMX、Grafana和 Kafka UI 等监控工具,以及AWS CloudWatch以获取更全面的洞察。 经检查,我们观察到良好结果。发布和消费的消息正在处理,无明显延迟。 应用处理器高效将消息投递给订阅者,确保平稳不中断的流。 此外,所有100,000,500个客户端与broker保持稳定连接。
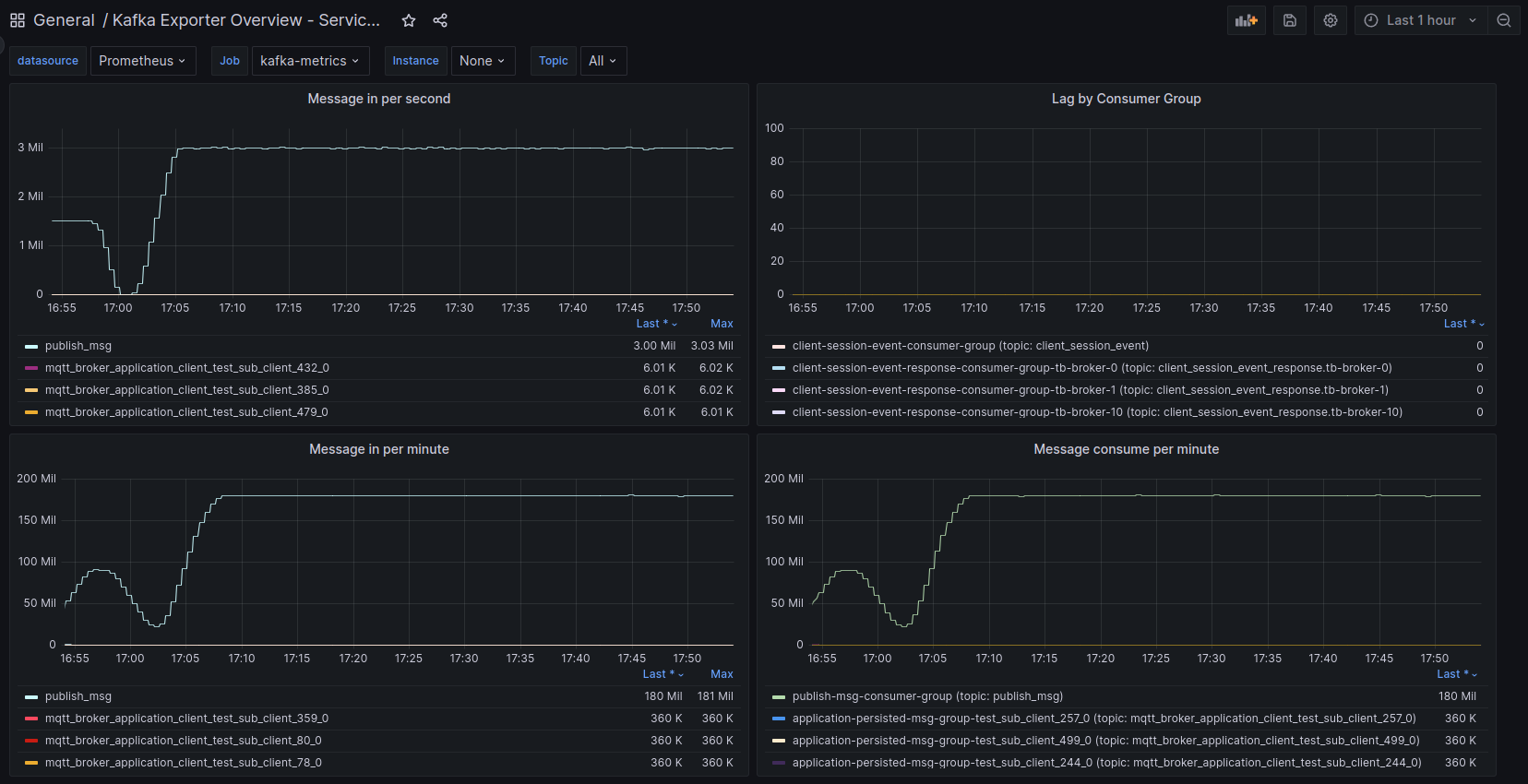
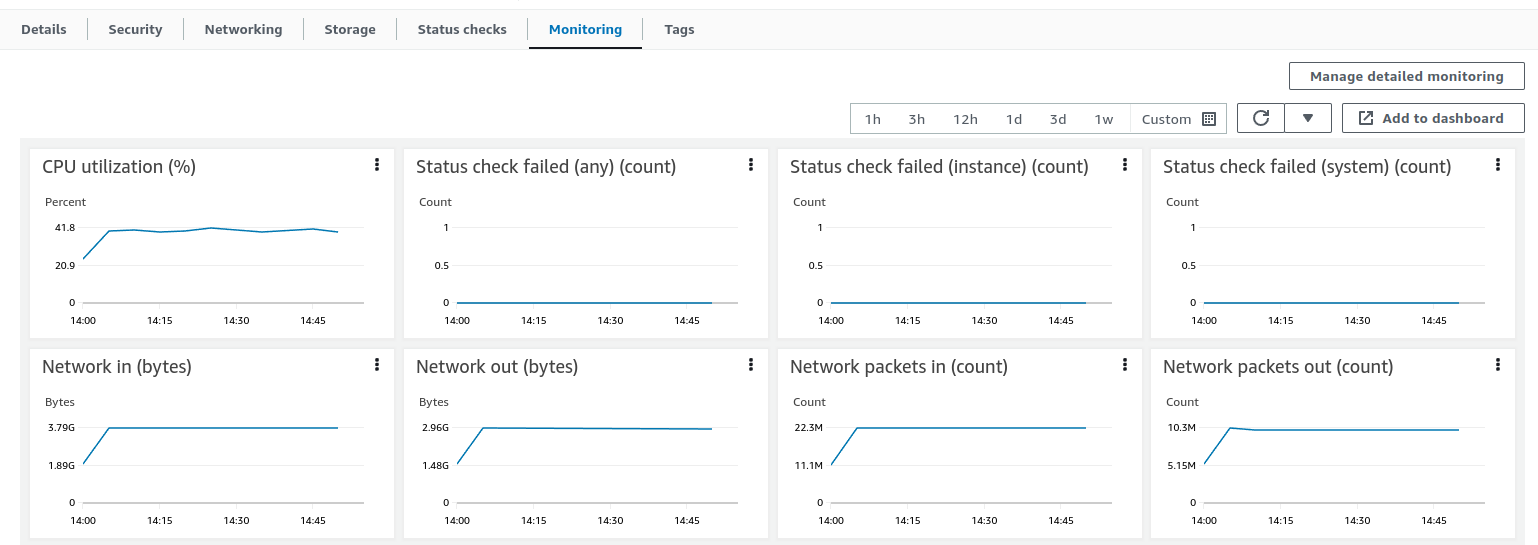
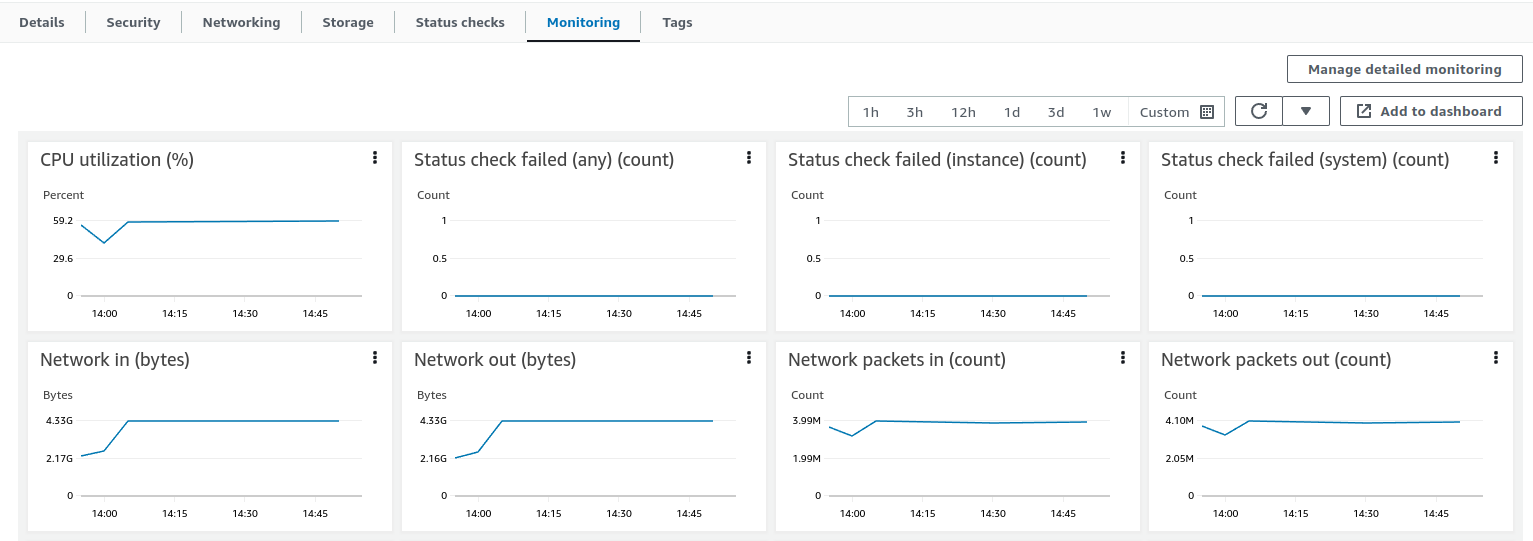
AWS实例(部署TBMQ节点的位置)监控显示平均CPU负载约45%。 另一方面,AWS RDS资源未被利用,因为没有DEVICE持久客户端,每秒仅发送少量请求。 同时,Kafka监控表明还有更多可用资源,暗示必要时可处理更高负载。
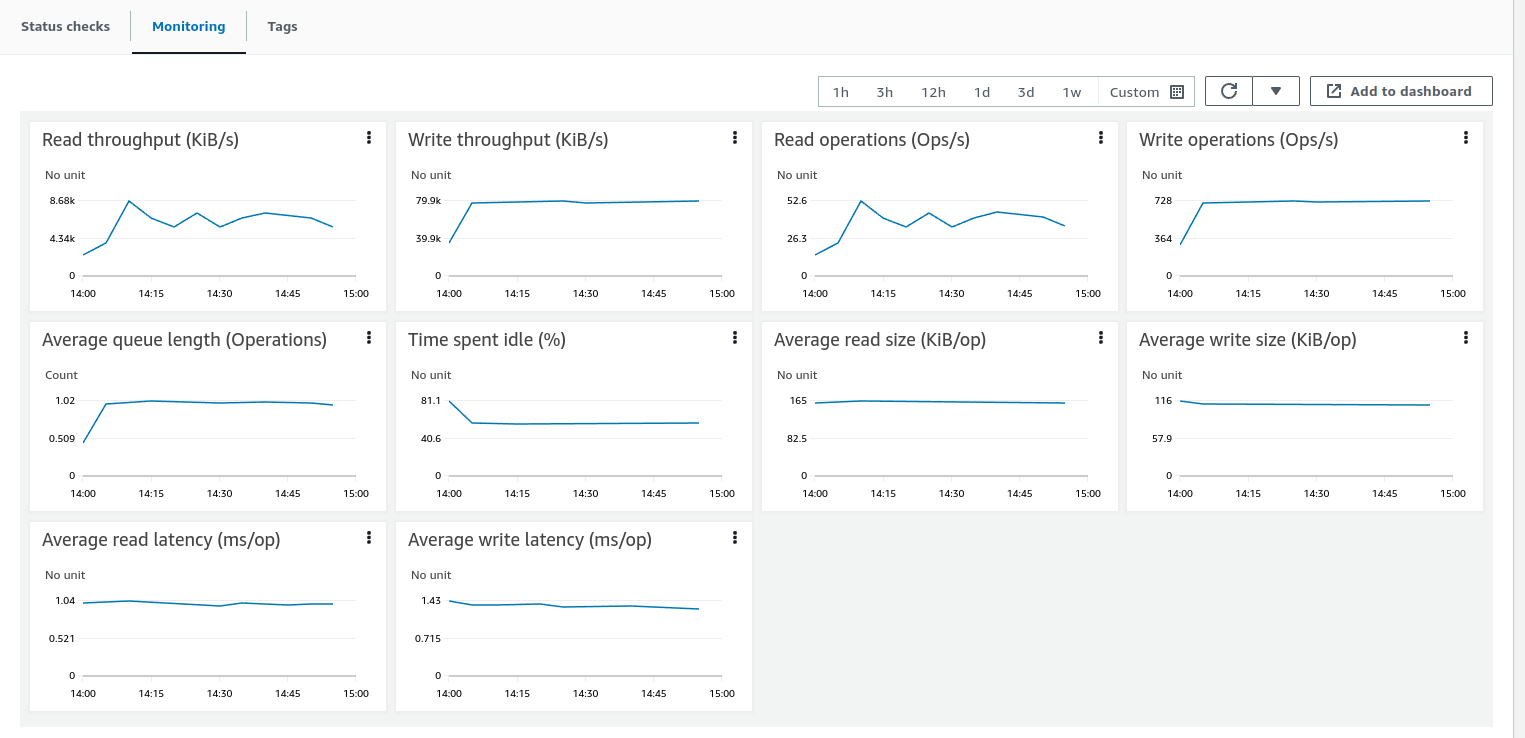
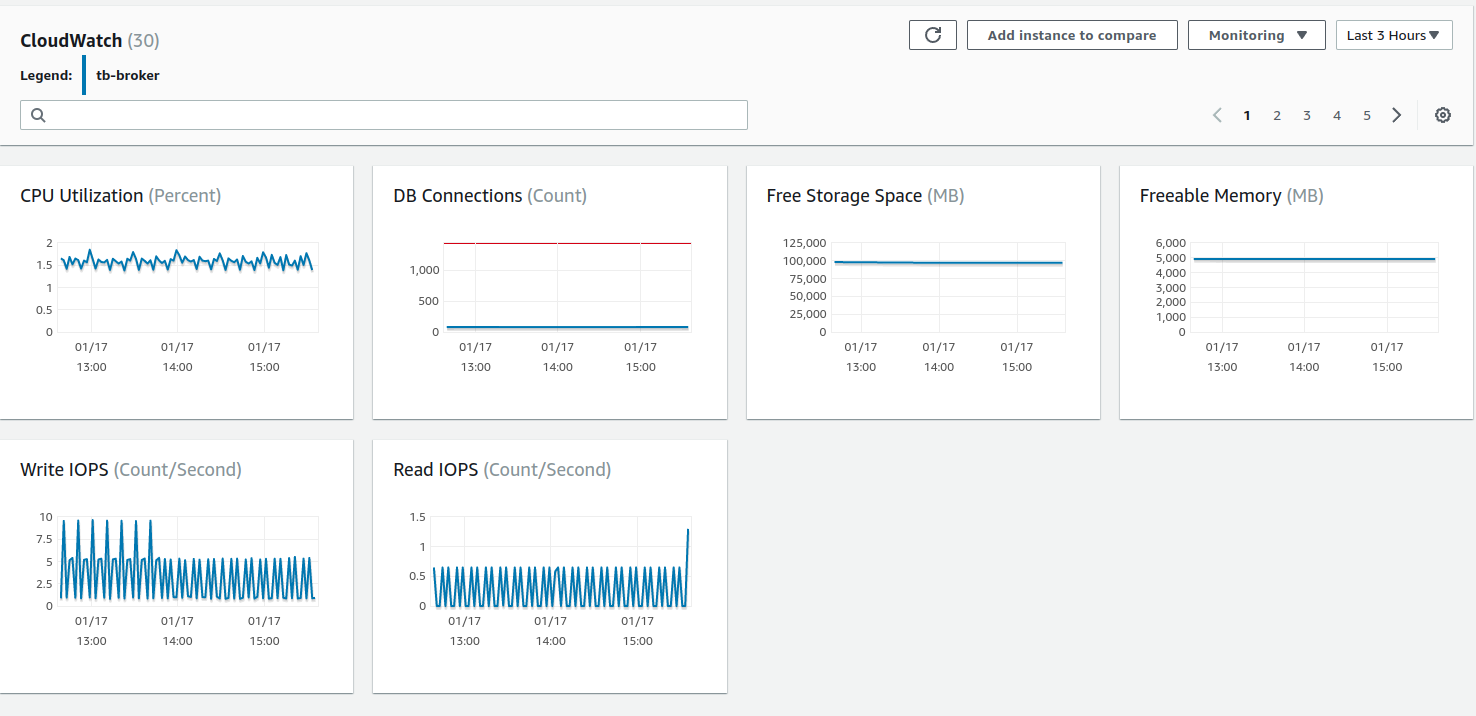
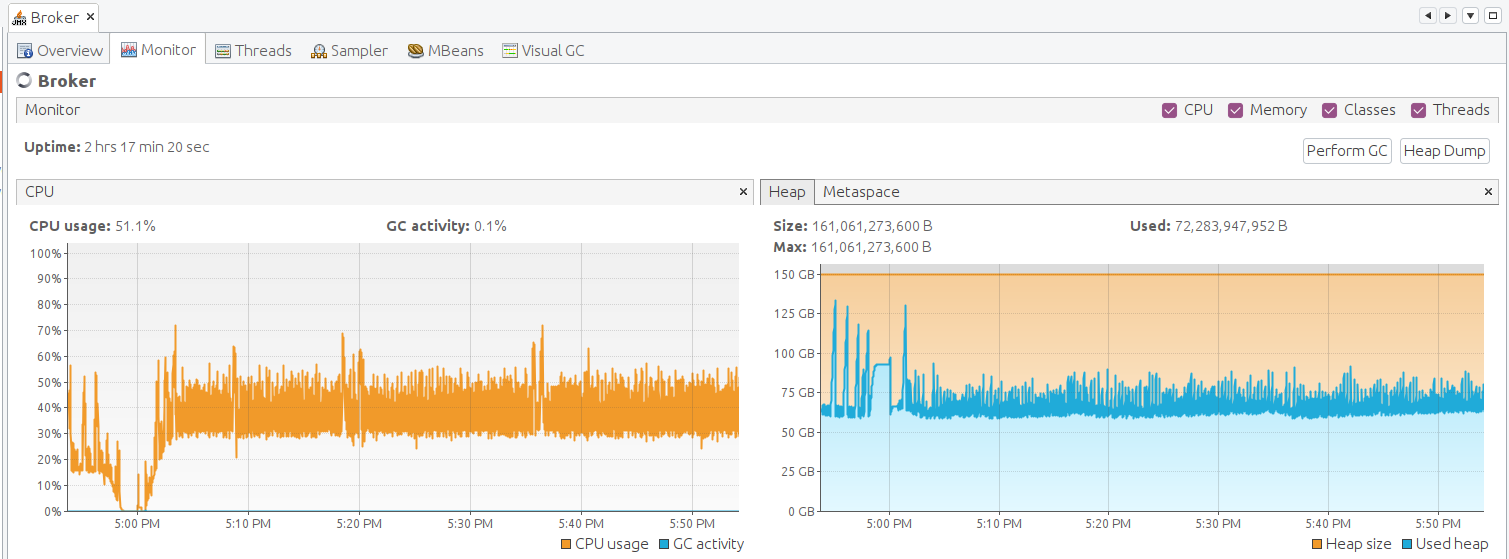
最后,让我们检查TBMQ的JVM状态。为此,我们必须转发JMX端口以建立连接并监控Java应用。
1
kubectl port-forward tb-broker-0 9999:9999
请打开 VisualVM 并添加本地应用。 添加后打开它并让数据收集几分钟。 以下是TBMQ的JMX监控。Broker节点运行平稳,无明显问题。
如何复现测试
请参阅后续安装指南了解如何在AWS上部署TBMQ。 此外,您可以查看包含本性能测试期间运行TBMQ所用脚本和参数的 branch。 最后,性能测试工具可用于执行性能测试, 该工具可生成MQTT客户端并产生负载。 配置性能测试时,您可以查看并修改 发布者 和 订阅者 的配置文件以模拟所需负载。
结论
本性能测试展示了TBMQ集群能够高效处理来自不同设备的每秒600万条消息吞吐量,并同时处理1亿个并发连接。 我们致力于持续改进,将进行进一步工作以提升性能。 因此,我们预计在不久的将来发布TBMQ集群的更新性能结果。 我们真诚希望本文对评估TBMQ的人员以及希望在自己环境中进行性能测试的人员有所帮助。
如有反馈,欢迎在 GitHub 和 Twitter 关注我们。
参考提交
[1]-Kafka topic重命名。
[2]-Kafka生产者回调。
[3]-停止将发布消息加入队列。
[4]-消息包处理、UUID生成改进。
[5]-无需刷新发送消息。
[7]-移除应用发布消息副本。
[8]-发布消息中的Bytebuf。
[9]-broker节点间MQTT客户端均匀分布。