开源 MQTT 代理能否每秒处理一百万条消息以进行持久会话? TBMQ 2.x 证明 可以!更重要的是,它实现了这一点,没有单点故障,并确保即使在硬件发生故障时也不会丢失数据,这使其成为适用于 IIoT 应用程序的强大的自托管 MQTT 代理解决方案。
本文深入探讨了定义最近的架构决策和性能改进 2.0.x 版本 TBMQ,重点关注这些变化如何在可扩展的物联网架构中优化持久会话处理、增强 P2P 消息传递以及提高整体系统效率。
我们希望本文为寻求将数据库工作负载卸载到持久缓存层的想法和模式的软件工程师提供有价值的见解,从而帮助提高系统的可扩展性和性能。此外,对于那些探索 Mosquitto 替代方案的人来说,TBMQ 是一个功能强大且容错的 MQTT 代理选项。
扇入模式
而TBMQ 1.x版本 能处理一次性拥有 1 亿客户d是补丁 每秒 300 万条消息,作为高性能 MQTT 代理,它主要设计用于聚合来自 IoT 设备的数据并将其可靠地传送到后端应用程序 (QoS 1)。该架构基于我们在工业物联网和其他大规模物联网部署方面的经验,其中数百万台设备将数据传输到有限数量的应用程序。
通过这些部署,我们认识到物联网设备和应用程序遵循不同的通信模式。 IoT 设备或传感器经常发布数据,但订阅的主题或更新相对较少。相比之下,应用程序从数万甚至数十万台设备订阅数据,需要可靠的消息传递。此外,由于系统维护、升级、故障转移场景或临时网络中断,应用程序经常会经历一段时间的停机。
为了解决这些差异,TBMQ 引入了一个关键功能:将 MQTT 客户端分类为标准(物联网设备)或 应用 客户。这种区别可以优化应用程序持久 MQTT 会话的处理。具体来说,每个持久应用程序客户端都分配有一个单独的 Kafka 主题。这种方法可确保 MQTT 客户端重新连接时有效的消息持久化和检索,从而提高整体可靠性和性能。此外,应用程序客户端支持 MQTT 的共享订阅功能,允许应用程序的多个实例有效地分发消息处理。



卡夫卡 作为核心组件之一。 Kafka 专为高吞吐量、分布式消息传递而设计,可有效处理大量数据流,使其成为 TBMQ 的理想选择。由于最新的 Kafka 版本能够管理大量主题,因此该架构非常适合企业规模的部署。
P2P模式
与扇入不同,点对点 (P2P) 通信模式支持 MQTT 客户端之间的直接消息交换。 P2P 通常使用唯一定义的主题来实现,非常适合私人消息传递、设备到设备通信、命令传输和其他直接交互用例。
扇入和点对点 MQTT 消息传递之间的主要区别之一是消息的数量和流量。在 P2P 场景中,订阅者不处理大量消息,因此无需为每个 MQTT 客户端分配专用的 Kafka 主题和消费者线程。相反,P2P 消息交换的主要要求是低延迟和可靠的消息传递,即使对于可能暂时离线的客户端也是如此。为了满足这些需求,TBMQ 优化了标准 MQTT 客户端(包括 IoT 设备)的持久会话管理。

在 TBMQ 1.x 中,标准 MQTT 客户端依赖 PostgreSQL 进行消息持久化和检索,确保在客户端重新连接时传送消息。虽然 PostgreSQL 最初表现良好,但它有一个基本限制——它只能垂直扩展。我们预计,随着持久 MQTT 会话数量的增长,PostgreSQL 的架构最终将成为瓶颈。为了解决这个问题,我们探索了更具可扩展性的替代方案,能够满足 MQTT 代理不断增长的需求。由于其水平可扩展性、本机集群支持和广泛采用,Redis 很快被选为最合适的选择。
PostgreSQL 的使用和限制
为了充分理解这种转变背后的原因,首先检查 MQTT 客户端在 PostgreSQL 架构中的运行方式非常重要。该架构是围绕两个关键表构建的。
这 device_session_ctx 表负责维护每个持久 MQTT 客户端的会话状态:
Table "public.device_session_ctx"
Column | Type | Collation | Nullable | Default
--------------------+------------------------+-----------+----------+---------
client_id | character varying(255) | | not null |
last_updated_time | bigint | | not null |
last_serial_number | bigint | | |
last_packet_id | integer | | |
Indexes:
"device_session_ctx_pkey" PRIMARY KEY, btree (client_id)关键列是 last_packet_id 和 last_serial_number,用于维护持久 MQTT 客户端的消息顺序:
-
last_packet_id表示最后收到的 MQTT 消息的数据包 ID。 -
last_serial_number充当持续递增的计数器,防止 MQTT 数据包 ID 在达到其限制后回绕时出现消息顺序问题65535.
这device_publish_msg 表负责存储必须发布到持久 MQTT 客户端(订阅者)的消息。
Table "public.device_publish_msg"
Column | Type | Collation | Nullable | Default
--------------------------+------------------------+-----------+----------+---------
client_id | character varying(255) | | not null |
serial_number | bigint | | not null |
topic | character varying | | not null |
time | bigint | | not null |
packet_id | integer | | |
packet_type | character varying(255) | | |
qos | integer | | not null |
payload | bytea | | not null |
user_properties | character varying | | |
retain | boolean | | |
msg_expiry_interval | integer | | |
payload_format_indicator | integer | | |
content_type | character varying(255) | | |
response_topic | character varying(255) | | |
correlation_data | bytea | | |
Indexes:
"device_publish_msg_pkey" PRIMARY KEY, btree (client_id, serial_number)
"idx_device_publish_msg_packet_id" btree (client_id, packet_id)要突出显示的关键列:
-
time– 捕获存储消息时的系统时间(时间戳)。该字段用于定期清理过期消息。 -
msg_expiry_interval– 表示消息的过期时间(以秒为单位)。仅针对包含到期属性的传入 MQTT 5 消息进行设置。如果缺少过期属性,则消息没有特定的过期时间,并且将保持有效,直到通过基于时间或基于大小的清理将其删除。
这些表共同管理消息持久性和会话状态。这 device_session_ctx 表旨在快速检索为每个持久 MQTT 客户端存储的最后一个 MQTT 数据包 ID 和序列号。当从共享 Kafka 主题接收到客户端的消息时,代理会查询此表以获取最新值。这些值按顺序递增并分配给每条消息,然后保存到 device_publish_msg 桌子。
虽然这种设计确保了可靠的消息传递,但它也引入了性能限制。为了更好地了解其局限性,我们进行了原型测试来评估 PostgreSQL 在 P2P 通信模式下的性能。使用具有 64GB RAM 和 12 个 CPU 核心的单个实例,我们使用专用的 性能测试工具 能够生成 MQTT 客户端并模拟所需的消息负载。主要性能指标是平均消息处理延迟——从消息发布到订阅者确认的时间点进行测量。仅当没有性能下降时,测试才被认为是成功的,这意味着代理始终将平均延迟保持在两位数毫秒范围内。
通过原型测试,我们最终达到了 使用 PostgreSQL 作为持久性消息存储,吞吐量限制为 30k msg/s。吞吐量是指每秒的消息总数,包括传入消息和传出消息。
基于 TimescaleDB 博客 邮政,vanilla PostgreSQL 在理想条件下每秒可以处理高达 300k 的插入。但是,此性能取决于硬件、工作负载和表架构等因素。虽然垂直扩展可以提供一些改进,但 PostgreSQL 的每表插入吞吐量最终会达到硬性限制。我们相信 Redis 能够克服这一瓶颈,因此开始了迁移过程,以实现更高的可扩展性和效率。
Redis 作为可扩展的替代方案
我们决定迁移到 Redis 是因为它能够解决 PostgreSQL 遇到的核心性能瓶颈。与依赖基于磁盘的存储和垂直扩展的 PostgreSQL 不同,Redis 主要在内存中运行,从而显着减少了读写延迟。此外,Redis的分布式架构支持水平扩展,非常适合P2P通信场景中的高吞吐量消息传递。

考虑到这些好处,我们从评估数据结构开始迁移过程,这些数据结构可以保留 PostgreSQL 方法的功能,同时与 Redis 集群约束保持一致,以实现高效的水平扩展。这也提供了一个机会来改进原始设计的某些方面,例如通过利用内置过期机制等 Redis 功能进行定期清理。
Redis 集群约束
从 PostgreSQL 迁移到 Redis 时,我们认识到复制现有数据模型需要多个 Redis 数据结构来有效处理消息持久化和排序。反过来,这意味着每个持久 MQTT 客户端会话使用多个密钥。
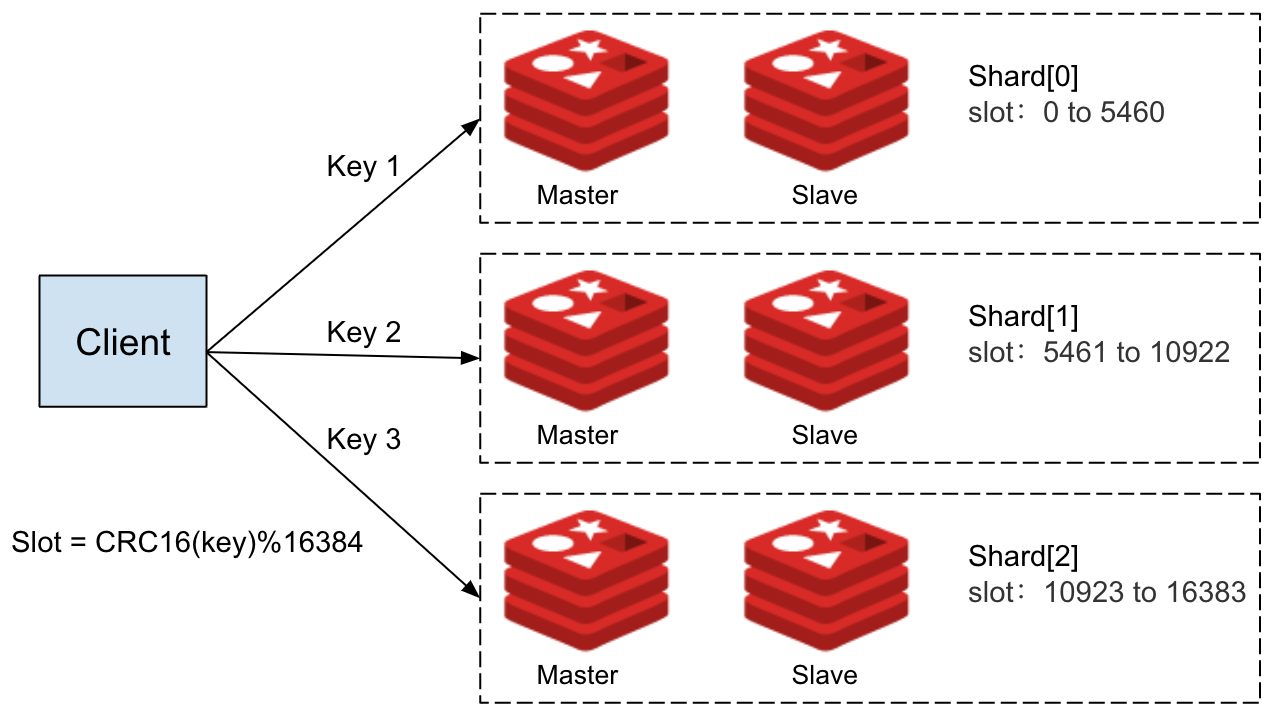
Redis Cluster 将数据分布在多个槽中以实现水平扩展。然而,多键操作必须访问同一槽内的键。如果密钥驻留在不同的插槽中,则该操作会触发跨插槽错误,从而阻止命令执行。 我们用了持久的 MQTT 客户端 ID 作为井号在我们的关键名称中来解决这个问题。将客户端 ID 括在花括号中 {},Redis 确保同一客户端的所有键都被哈希到同一个槽。这保证了每个客户端的相关数据保持在一起,从而允许多键操作顺利进行。
通过 Lua 脚本进行原子操作
在 TBMQ 等高吞吐量环境中,一致性至关重要,因为许多消息可以同时到达同一个 MQTT 客户端。标签有助于避免跨槽错误,但如果没有原子操作,则存在竞争条件或部分更新的风险。这可能会导致消息丢失或排序错误。确保更新同一 MQTT 客户端的密钥的操作是原子的非常重要。

Redis 旨在以原子方式执行单个命令。然而,在我们的例子中,我们需要更新多个数据结构,作为每个 MQTT 客户端的单个操作的一部分。如果另一个进程在命令之间修改相同的数据,则在没有原子性的情况下按顺序执行这些命令可能会导致不一致。那就是那里 Lua脚本 Lua 脚本作为一个独立的单元执行。在脚本执行期间,没有其他命令可以同时运行,确保脚本内的操作以原子方式发生。
根据这些信息,我们决定对于任何操作,例如保存消息或在重新连接时检索未传递的消息,我们将执行一个单独的 Lua 脚本。这确保了单个 Lua 脚本中的所有操作都驻留在同一个哈希槽中,从而保持原子性和一致性。
选择正确的 Redis 数据结构
迁移的关键要求之一是维护消息顺序,这项任务以前由 serial_number PostgreSQL 中的专栏 device_publish_msg 桌子。在评估了各种 Redis 数据结构之后,我们确定 排序集 (ZSET)是理想的替代品。
Redis 排序集自然地按分数组织数据,从而可以按升序或降序快速检索消息。虽然排序集提供了维护消息顺序的有效方法,但将完整消息有效负载直接存储在排序集中会导致内存使用过多。 Redis 不支持排序集中的每个成员 TTL。因此,除非明确删除,否则消息会无限期地保留。与 PostgreSQL 类似,我们必须使用以下命令执行定期清理 ZREMRANGEBYSCORE 删除过期的消息。该操作的复杂度为 O(log N + M), 在哪里 M 是删除的元素数量。为了克服这个限制,我们决定使用存储消息有效负载 字符串 数据结构,同时存储在排序集中对这些键的引用。
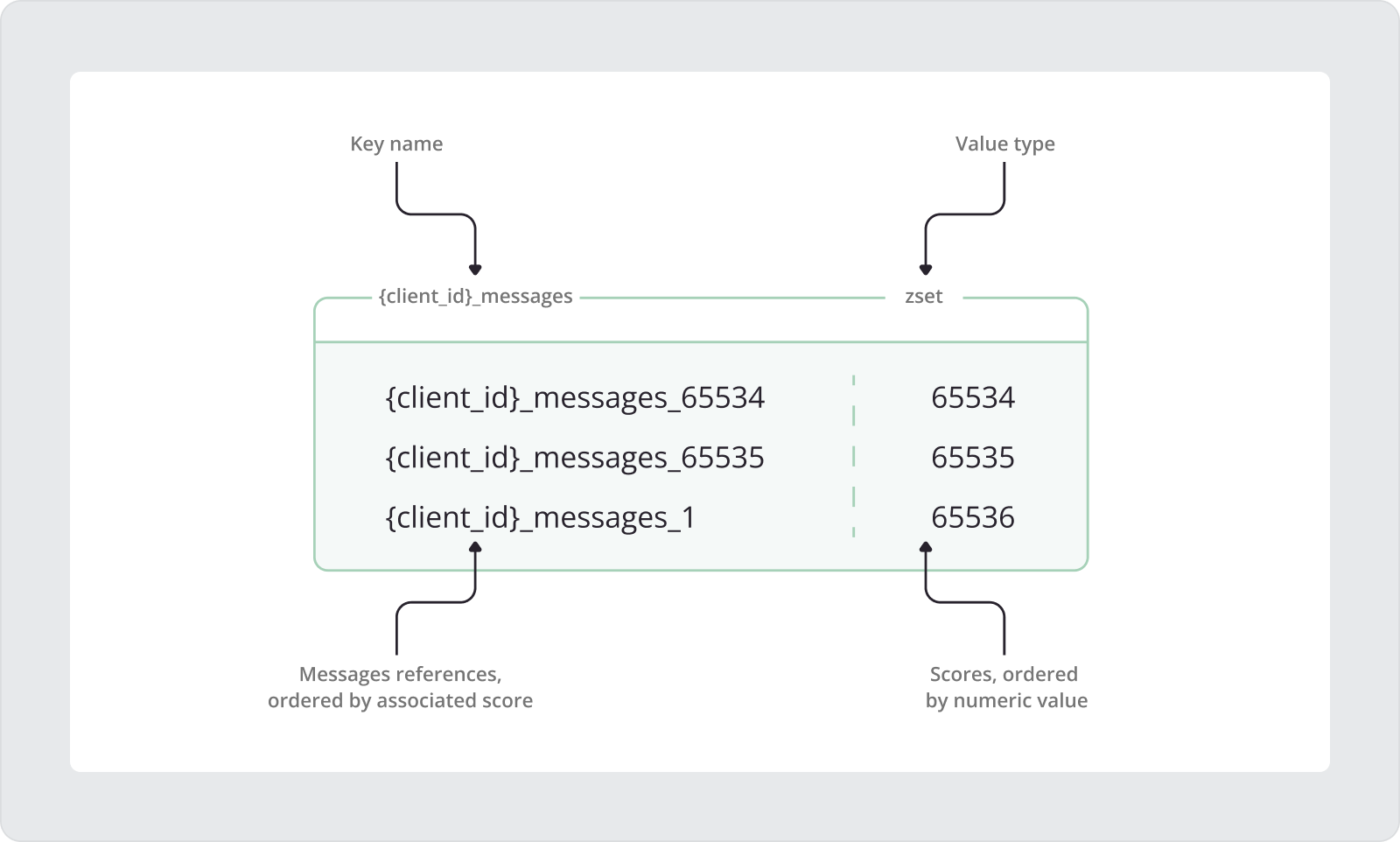
client_id 是实际客户端 ID 的占位符,而大括号 {} 在它周围添加以创建一个 井号.在上图中,您可以看到,即使 MQTT 数据包 ID 回绕,分数也会继续增长。让我们仔细看看该图中所示的细节。首先,MQTT 数据包 ID 等于的消息的引用 65534 被添加到排序集中:
ZADD {client_id}_messages 65534 {client_id}_messages_65534这里, {client_id}_messages 是排序集键名,其中 {client_id} 充当从持久 MQTT 客户端的唯一 ID 派生的哈希标签。后缀 _messages 是添加到每个排序集键名以保持一致性的常量。排序后的集合键名后面是分值 65534 对应客户端收到消息的MQTT报文ID。最后,我们看到指向 MQTT 消息实际负载的引用键。与排序集键类似,消息引用键使用 MQTT 客户端的 ID 作为哈希标签,后跟 _messages 后缀和 MQTT 数据包 ID 值。
在下一次迭代中,我们添加数据包 ID 等于 MQTT 消息的消息引用 65535 进入已排序的集合。这是最大数据包 ID,因为范围限制为 65535.
ZADD {client_id}_messages 65535 {client_id}_messages_65535因此,在下一次迭代中,MQTT 数据包 ID 应等于 1,而分数应继续增长并等于 65536.
ZADD {client_id}_messages 65536 {client_id}_messages_1这种方法可确保消息的引用在排序集中正确排序,而不管数据包 ID 的有限范围如何。
消息有效负载存储为字符串值 SET 支持过期的命令(EX),提供 O(1) 写入的复杂性和 TTL 应用:
SET {client_id}_messages_1 "{
\"packetType\":\"PUBLISH\",
\"payload\":\"eyJkYXRhIjoidGJtcWlzYXdlc29tZSJ9\",
\"time\":1736333110026,
\"clientId\":\"client\",
\"retained\":false,
\"packetId\":1,
\"topicName\":\"europe/ua/kyiv/client/0\",
\"qos\":1
}" EX 600除了高效更新和 TTL 应用程序之外的另一个好处是可以检索消息有效负载:
GET {client_id}_messages_1或删除:
DEL {client_id}_messages_1具有恒定的复杂性 O(1) 而不影响有序集结构。
我们的 Redis 架构的另一个非常重要的元素是使用字符串键来存储最后处理的 MQTT 数据包 ID:
GET {client_id}_last_packet_id
"1"此方法与 PostgreSQL 解决方案具有相同的目的。当客户端重新连接时,服务器必须确定正确的数据包 ID,以分配给将保存在 Redis 中的下一条消息。最初,我们考虑使用排序集的最高分数作为参考。然而,由于存在排序集可能为空或完全删除的情况,我们得出结论,最可靠的解决方案是单独存储最后一个数据包 ID。
动态管理排序集大小
这种混合方法利用排序集和字符串数据结构,消除了基于时间定期清理的需要,因为现在应用了每条消息的 TTL。此外,按照 PostgreSQL 设计,我们需要以某种方式根据配置中设置的消息限制来解决排序集的清理问题。
# Maximum number of PUBLISH messages stored for each persisted DEVICE client
limit: "${MQTT_PERSISTENT_SESSION_DEVICE_PERSISTED_MESSAGES_LIMIT:10000}"此限制是我们设计的重要组成部分,使我们能够控制和预测每个持久 MQTT 客户端所需的内存分配。例如,客户端可能会连接,触发持久会话的注册,然后快速断开连接。在这种情况下,必须确保为客户端存储的消息数量(在等待潜在的重新连接时)保持在定义的限制内,以防止无限制的内存使用。
if (messagesLimit > 0xffff) {
throw new IllegalArgumentException("Persisted messages limit can't be greater than 65535!");
}为了反映 MQTT 协议的自然约束,单个客户端的最大持久消息数设置为 65535.
为了在 Redis 解决方案中处理这个问题,我们实现了排序集大小的动态管理。添加新消息时,会对排序集进行修剪,以确保消息总数保持在所需的限制内,并且还会清理关联的字符串以释放内存。
-- Get the number of elements to be removed
local numElementsToRemove = redis.call('ZCARD', messagesKey) - maxMessagesSize
-- Check if trimming is needed
if numElementsToRemove > 0 then
-- Get the elements to be removed (oldest ones)
local trimmedElements = redis.call('ZRANGE', messagesKey, 0, numElementsToRemove - 1)
-- Iterate over the elements and remove them
for _, key in ipairs(trimmedElements) do
-- Remove the message from the string data structure
redis.call('DEL', key)
-- Remove the message reference from the sorted set
redis.call('ZREM', messagesKey, key)
end
end
消息检索和清理
我们的设计不仅确保新消息持久化期间的动态大小管理,而且还支持消息检索期间的清理,这在设备重新连接以处理未传递的消息时发生。此方法通过删除对过期消息的引用来保持排序集干净。
-- Define the sorted set key
local messagesKey = KEYS[1]
-- Define the maximum allowed number of messages
local maxMessagesSize = tonumber(ARGV[1])
-- Get all elements from the sorted set
local elements = redis.call('ZRANGE', messagesKey, 0, -1)
-- Initialize a table to store retrieved messages
local messages = {}
-- Iterate over each element in the sorted set
for _, key in ipairs(elements) do
-- Check if the message key still exists in Redis
if redis.call('EXISTS', key) == 1 then
-- Retrieve the message value from Redis
local msgJson = redis.call('GET', key)
-- Store the retrieved message in the result table
table.insert(messages, msgJson)
else
-- Remove the reference from the sorted set if the key does not exist
redis.call('ZREM', messagesKey, key)
end
end
-- Return the retrieved messages
return messages通过利用 Redis 的排序集和字符串,以及用于原子操作的 Lua 脚本,我们的新设计实现了高效的消息持久化和检索以及动态清理。此设计解决了基于 PostgreSQL 的解决方案的可扩展性限制。
在接下来的部分中,我们将描述基于 Redis 的新架构与 PostgreSQL 解决方案的性能比较。这些部分介绍了性能测试的结果及其主要发现。
从 Jedis 迁移到 Lettuce

正如我们之前提到的,我们进行了原型测试,揭示了使用 PostgreSQL 进行持久性消息存储时 30k msg/s 吞吐量的限制。在我们迁移到 Redis 的那一刻,我们已经使用了 杰迪斯 用于 Redis 交互的库,主要用于缓存管理,并将其扩展为处理持久性 MQTT 客户端的消息持久性。然而,使用 Jedis 实现 Redis 的初步结果却出乎意料。虽然我们预计 Redis 的性能将显着优于 PostgreSQL,但性能提升幅度不大——仅达到 40k 消息/秒的吞吐量,而 PostgreSQL 的吞吐量限制为 30k 消息/秒。
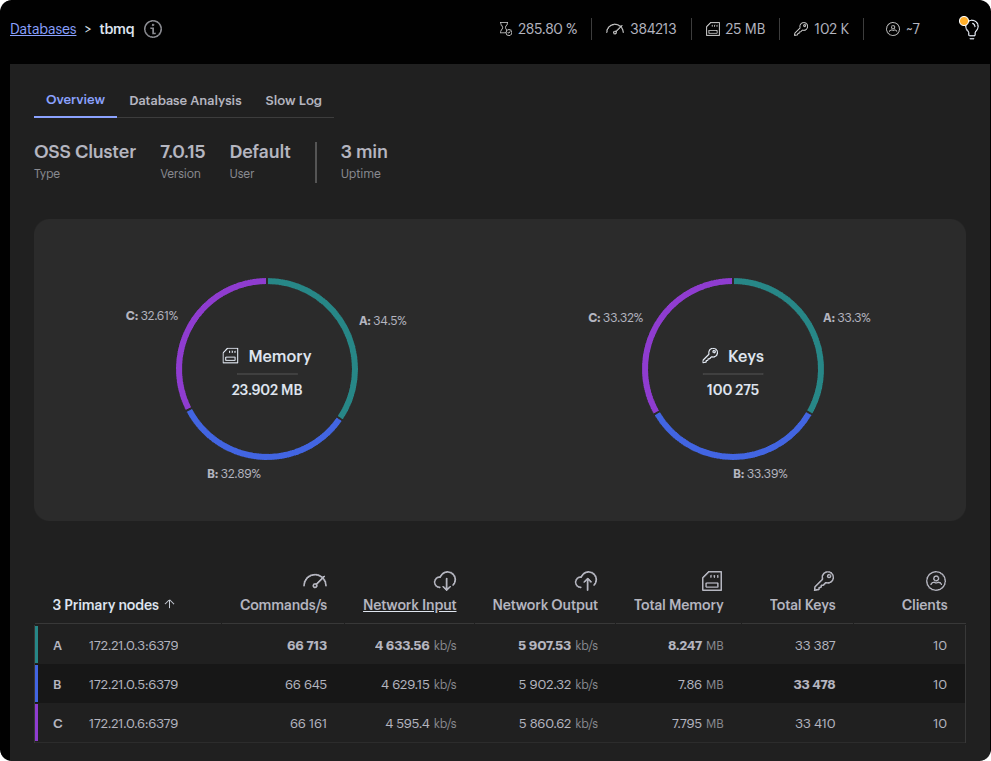
这促使我们调查瓶颈,发现 Jedis 是一个限制因素。 Jedis 可靠且同步运行,按顺序处理每个 Redis 命令。这迫使系统等待一个操作完成后再执行下一个操作。在高吞吐量环境中,这种方法极大地限制了 Redis 的潜力,阻碍了系统资源的充分利用。
为了克服这个限制,我们迁移到 莴苣,一个构建在之上的异步 Redis 客户端 内蒂。借助 Lettuce,我们的吞吐量提高到了 60k msg/s,展示了非阻塞操作和改进的并行性的优势。
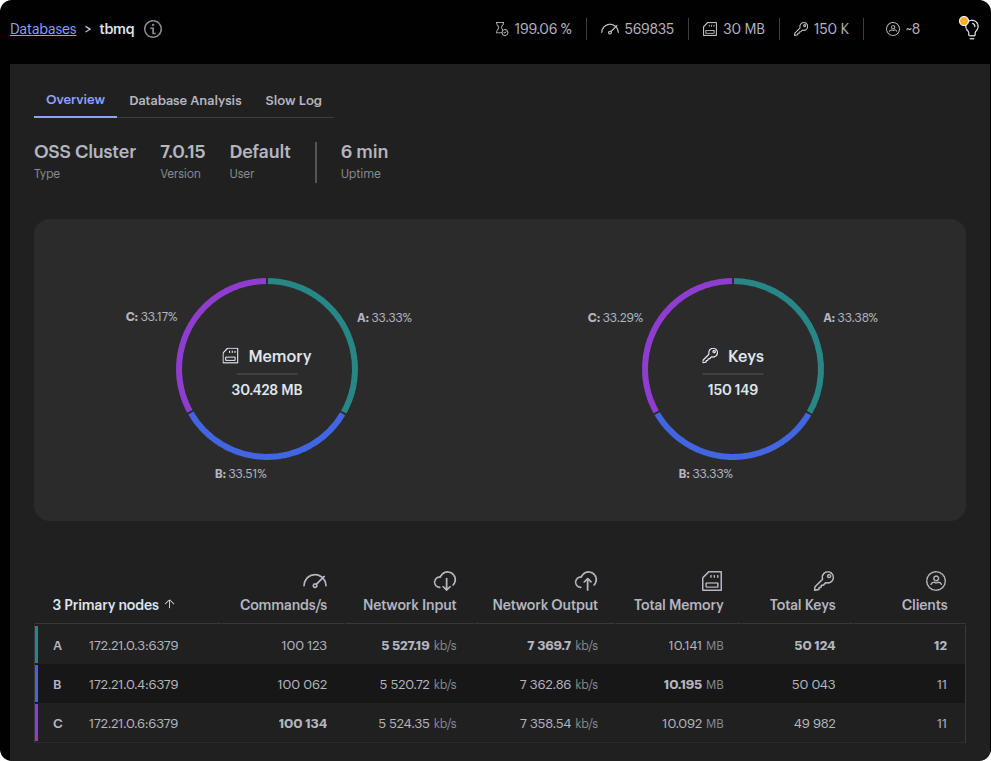
Lettuce 允许并行发送和处理多个命令,充分利用 Redis 的并发工作负载能力。最终,迁移释放了我们期望从 Redis 获得的性能提升,为成功的大规模 P2P 测试铺平了道路。
扩展点对点消息传递
随着 Redis 和 Lettuce 的完全集成,下一个挑战是确保 TBMQ 能够在分布式环境中处理大规模 P2P 消息传递。为了模拟现实世界的条件,我们部署了 AWS EKS(弹性 Kubernetes 服务)上的 TBMQ,使我们能够动态扩展系统并对系统进行压力测试。
为了评估性能并证明我们的系统可以有效扩展,我们从每秒 200,000 条消息开始,并在每次迭代中增加 200,000 条消息的负载。在每个阶段,我们都扩展了 TBMQ 代理和 Redis 节点的数量,以处理不断增长的流量,同时保持系统稳定。对于 1M 消息/秒测试,我们还扩展了 Kafka 代理的数量来处理相应的工作负载。
| 吞吐量(消息/秒) | 出版商 | 订阅者 | TBMQ 经纪商 | Redis 节点 | 卡夫卡经纪人 |
| 20万 | 10万 | 10万 | 1 | 3 | 3 |
| 40万 | 20万 | 20万 | 2 | 5 | 3 |
| 60万 | 30万 | 30万 | 3 | 7 | 3 |
| 80万 | 40万 | 40万 | 4 | 9 | 3 |
| 1M | 50万 | 50万 | 5 | 11 | 5 |
除了添加资源之外,负载的每次增加都需要对 Kafka 主题分区和 Lettuce 命令批处理参数进行微调。这些调整有助于均匀分配流量并保持延迟稳定,从而防止我们扩展时出现瓶颈。
| 吞吐量(消息/秒) | Kafka 主题分区 | 生菜批量大小 |
| 20万 | 12 | 150 |
| 40万 | 12 | 250 |
| 60万 | 12 | 300 |
| 80万 | 16 | 400 |
| 1M | 20 | 500 |
生菜批量大小 – 刷新前缓冲的 Redis 命令数。当达到批量大小时或每隔 3毫秒,以先到者为准。
我们达到了我们的目标 每秒 100 万条消息,验证 TBMQ 支持高吞吐量可靠 P2P 消息传递的能力。为了更好地说明测试设置和结果,下图提供了最终性能测试的可视化分解。

测试结果
在整个测试过程中,我们监控了关键性能指标,例如 CPU 利用率、内存使用率和消息处理延迟。我们的 P2P 测试中强调的 TBMQ 的突出优势之一是其卓越的每 CPU 核心每秒消息性能。与其他代理的公共基准相比,TBMQ 始终以更少的资源提供更高的吞吐量,从而增强了大规模部署的效率。
测试的主要结论包括:
- 可扩展性: TBMQ 展示了线性可扩展性。通过在更高的工作负载下增量添加 TBMQ 节点、Redis 节点和 Kafka 节点,当消息吞吐量从 200k 增加到 1M 消息/秒时,我们保持了可靠的性能。
- 高效的资源利用: 在所有测试阶段,TBMQ 节点上的 CPU 利用率始终保持在 90% 左右,这表明系统有效地使用了可用资源,而没有过度消耗。
- 延迟管理: 所有测试中观察到的延迟均保持在两位数范围内。考虑到 QoS 1,这是可以预见的 为我们的测试选择的级别,适用于发布者和持久订阅者。我们还跟踪了发布者的平均确认延迟,该延迟在所有测试阶段都保持在个位数范围内。
- 高性能: TBMQ 的一对一通信模式显示出出色的效率,每个 CPU 内核处理约 8900 条消息/秒。我们通过将总吞吐量除以设置中使用的 CPU 核心总数来计算此值。
此外,下表全面总结了最终 1M 消息/秒测试的关键要素和结果:
| 服务质量 | P2P延迟 |
发布 延迟 |
每秒消息数 每个CPU核心 |
TBMQ CPU 使用率 |
有效载荷 (字节) |
| 1 | 〜75毫秒 | 〜8毫秒 | 8900 | 91% | 62 |
P2P 延迟: 从发布者发送 PUB 消息到订阅者收到消息的平均持续时间。
发布延迟: 发布者发送 PUB 消息到收到 PUBACK 确认之间所用的平均时间。
要更深入地了解测试架构、方法和结果,请查看我们的 详细的性能测试文章.
结论
TBMQ 2.x 为自托管 MQTT 代理树立了新基准,证明其能够每秒处理 100 万条消息以进行持久会话,而不会丢失数据 - 即使在发生硬件故障时也是如此。 TBMQ 旨在消除单点故障和瓶颈,通过结合用于持久性的 Redis、用于消息分发的 Kafka 和高度优化的代理代码库,实现了卓越的效率。
在我们的测试中,通过比较其他平台的公共数据,TBMQ 在每个 CPU 核心处理的消息方面处于领先地位(~8,900 条消息/秒),使其成为高吞吐量 IIoT 和其他 MQTT 部署的有力选择。这种效率不仅仅是一个原始指标,它还意味着更低的基础设施成本和更简单的扩展。
TBMQ 长期以来一直是扇入和扇出场景中的佼佼者,可以轻松处理从数百万设备到后端系统的数据。现在,它在 P2P 消息传递方面也脱颖而出,为一对一通信用例提供低延迟和高吞吐量。如果您需要大吞吐量、低延迟和高效的资源利用,TBMQ 提供了一条经过验证的前进道路。